SEO Spider 标签页
内部链接
“内部链接”标签页整合了从大多数其他标签页(外部链接、hreflang 和结构化数据标签页除外)提取的所有数据。这意味着所有数据都可以全面查看,并可以一起导出以进行进一步分析。
被归类为“内部”的 URL 与爬取的起始页位于同一子域名下。通过使用“爬取所有子域名“配置、列表模式或 CDN 功能,可以将 URL 设置为内部链接。
列
此标签页包含以下列。
- Address – URL 地址。
- Content – URL 的内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- Title 1 – 页面上发现的(第一个)页面标题。
- Title 1 Length – 页面标题的字符长度。
- Title 1 Pixel Width – 页面标题的像素宽度,如我们的像素宽度文章中所述。
- Meta Description 1 – 页面上的(第一个)meta 描述。
- Meta Description Length 1 – meta 描述的字符长度。
- Meta Description Pixel Width – meta 描述的像素宽度。
- Meta Keyword 1 – meta 关键词。
- Meta Keywords Length – meta 关键词的字符长度。
- h1 – 1 – 页面上的第一个 h1(标题)。
- h1 – Len-1 – h1 的字符长度。
- h2 – 1 – 页面上的第一个 h2(标题)。
- h2 – Len-1 – h2 的字符长度。
- Meta Robots 1 – 在 URL 上找到的 Meta robots 指令。
- X-Robots-Tag 1 – URL 的 X-Robots-tag HTTP 标头指令。
- Meta Refresh 1 – Meta refresh 数据。
- Canonical Link Element – canonical 链接元素数据。
- rel=“next” 1 – SEO Spider 收集这些 HTML 链接元素,旨在指示分页系列中 URL 之间的关系。
- rel=“prev” 1 – SEO Spider 收集这些 HTML 链接元素,旨在指示分页系列中 URL 之间的关系。
- HTTP rel=“next” 1 – SEO Spider 收集这些 HTTP 链接元素,旨在指示分页系列中 URL 之间的关系。
- HTTP rel=“prev” 1 – SEO Spider 收集这些 HTTP 链接元素,旨在指示分页系列中 URL 之间的关系。
- Size – 资源的大小,取自 Content-Length HTTP 标头。如果未提供此字段,则大小报告为零。对于 HTML 页面,这会更新为(未压缩的)HTML 的大小。导出时,大小以字节为单位,因此请除以 1,024 以转换为千字节。
- Transferred – 实际传输以加载资源的字节数,如果已压缩,则可能小于“size”。
- Total Transferred – 实际传输以加载 URL 的字节数,包括在 JavaScript 渲染 模式下的所有已加载资源。
- Word Count – 这是 body 标签内的所有“单词”,不包括 HTML 标记。计数基于可在“Config > Content > Area”下调整的内容区域。默认情况下,nav 和 footer 元素被排除。您可以包含或排除 HTML 元素、类和 ID 以计算精确的字数。我们的数字可能与手动执行此计算的结果不完全相同,因为解析器会对无效的 HTML 执行某些修复。您的渲染设置也会影响所考虑的 HTML。我们对单词的定义是获取文本并按空格分隔。不考虑内容的可见性(例如,设置为隐藏的 div 中的文本)。
- Text Ratio – 在页面的 HTML body 标签中找到的非 HTML 字符数(文本),除以 HTML 页面组成的字符总数,并显示为百分比。
- Crawl Depth – 页面与起始页的深度(与起始页的“点击”次数)。请注意,目前在我们的页面深度计算中,重定向算作一个级别。
- Folder Depth – URL 的深度,基于 URL 路径中的子文件夹数量(/sub-folder/)。这不是要优化的 SEO 指标,但可用于分段和高级表格搜索。
- Link Score – 介于 0-100 之间的指标,它根据页面的内部链接计算页面的相对价值,类似于 Google 自己的 PageRank。要填充此列,需要“爬取分析”。
- Inlinks – 指向 URL 的内部超链接的数量。“内部入站链接”是指从正在爬取的同一子域中的锚元素指向给定 URL 的链接。
- Unique Inlinks – 指向 URL 的“唯一”内部入站链接的数量。“内部入站链接”是指从正在爬取的同一子域中的锚元素指向给定 URL 的链接。例如,如果“页面 A”链接到“页面 B”3 次,则这将计为 3 个入站链接和 1 个指向“页面 B”的唯一入站链接。
- Unique JS Inlinks – 指向 URL 的“唯一”内部入站链接的数量,这些链接仅在 JavaScript 执行后才出现在渲染的 HTML 中。“内部入站链接”是指从正在爬取的同一子域中的锚元素指向给定 URL 的链接。例如,如果“页面 A”链接到“页面 B”3 次,则这将计为 3 个入站链接和 1 个指向“页面 B”的唯一入站链接。
- % of Total – 来自爬取的内部 HTML 页面总数的 URL 的唯一内部入站链接(200 响应 HTML 页面)的百分比。“内部入站链接”是指从正在爬取的同一子域中的锚元素指向给定 URI 的链接。
- Outlinks – 来自 URL 的内部出站链接的数量。“内部出站链接”是指从给定 URL 到正在爬取的同一子域上的其他 URL 的锚元素中的链接。
- Unique Outlinks – 来自 URL 的唯一内部出站链接的数量。“内部出站链接”是指从给定 URL 到正在爬取的同一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,则这将计为 3 个出站链接和 1 个指向“页面 B”的唯一出站链接。
- Unique JS Outlinks – 来自 URL 的唯一内部出站链接的数量,这些链接仅在 JavaScript 执行后才出现在渲染的 HTML 中。“内部出站链接”是指从给定 URL 到正在爬取的同一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,则这将计为 3 个出站链接和 1 个指向“页面 B”的唯一出站链接。
- External Outlinks – 来自 URL 的外部出站链接的数量。“外部出站链接”是指从给定 URL 到另一个子域的锚元素中的链接。
- Unique External Outlinks – 来自 URL 的唯一外部出站链接的数量。“外部出站链接”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,则这将计为 3 个外部出站链接和 1 个指向“页面 B”的唯一外部出站链接。
- Unique External JS Outlinks – 来自 URL 的唯一外部出站链接的数量,这些链接仅在 JavaScript 执行后才出现在渲染的 HTML 中。“外部出站链接”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,则这将计为 3 个外部出站链接和 1 个指向“页面 B”的唯一外部出站链接。
- Closest Similarity Match – 这显示了近似重复 URL 的最高相似度百分比。SEO Spider 将识别具有 90% 相似度匹配的近似重复项,可以调整该相似度以查找具有较低相似度阈值的内容。例如,如果一个页面有两个近似重复页面,相似度分别为 99% 和 90%,则此处将显示 99%。要填充此列,必须通过“Config > Content > Duplicates”选择“Enable Near Duplicates”配置,并且必须执行“Crawl Analysis”后处理。只有内容超过所选相似度阈值的 URL 才会包含数据,其他 URL 将保持空白。因此,默认情况下,此列仅包含相似度为 90% 或更高的 URL 的数据,除非已通过“Config > Content > Duplicates”和“Near Duplicate Similarity Threshold”设置进行了调整。
- No. Near Duplicates – 在爬取中发现的满足或超过“Near Duplicate Similarity Threshold”的近似重复 URL 的数量,默认情况下为 90% 匹配。可以在“Config > Content > Duplicates”下调整此设置。要填充此列,必须通过“Config > Content > Duplicates”选择“Enable Near Duplicates”配置,并且必须执行“Crawl Analysis”后处理。
- Spelling Errors – 为 URL 发现的拼写错误总数。要填充此列,必须通过“Config > Content > Spelling & Grammar”选择“Enable Spell Check”。
- Grammar Errors – 为 URL 发现的语法错误总数。要填充此列,必须通过“Config > Content > Spelling & Grammar”选择“Enable Grammar Check”。
- Language – 为拼写和语法检查选择的语言。这基于 HTML 语言属性,但也可以通过“Config > Content > Spelling & Grammar”设置语言。
- Hash – 使用 MD5 算法的页面哈希值。这是仅针对完全重复内容的重复内容检查。如果两个哈希值匹配,则页面在内容上完全相同。如果存在单个字符差异,它们将具有唯一的哈希值,并且不会被检测为重复内容。因此,这不是近似重复内容的检查。可以在“URL > Duplicate”下查看完全重复项。
- Response Time – 下载 URL 的时间(以秒为单位)。可以在我们的 FAQ 中找到更详细的信息。
- Last-Modified – 从服务器 HTTP 响应中的 Last-Modified 标头读取。如果服务器未提供此信息,则该值将为空。
- Redirect URI – 如果“address”URL 重定向,则此列将包含重定向 URL 目标。上面的状态代码将显示重��定向的类型,301、302 等。
- Redirect Type – 以下之一:HTTP Redirect:由 HTTP 标头触发,HSTS Policy:由于先前的 HSTS 标头,由 SEO Spider 在本地转换,JavaScript Redirect:由 JavaScript 执行触发(仅在使用 JavaScript 渲染时才会发生)或 MetaRefresh Redirect:由 HTML 中的 meta refresh 标记触发。
- HTTP Version – 这显示了爬取所使用的 HTTP 版本,默认情况下为 HTTP/1.1。如果服务器启用了 HTTP/2,则 SEO Spider 当前仅在 JavaScript 渲染模式下使用 HTTP/2 进行爬取。
- URL Encoded Address – SEO Spider 实际请求的 URL。所有非 ASCII 字符都经过百分比编码,有关更多详细信息,请参见 RFC 3986。
- Title 2, meta description 2, h1-2, h2-2 等 – SEO Spider 将从源代码中遇到的前两个元素收集数据。因此,h1-2 是页面上第二个 h1 标题的数据。
筛选器
此标签页包含以下筛选器。
- HTML – HTML 页面。
- JavaScript – 任何 JavaScript 文件。
- CSS – 发现的任何样式表。
- Images – 任何图像。
- PDF – 任何可移植文档文件。
- Flash – 任何 .swf 文件。
- Other – 任何其他文件类型,如文档等。
- Unknown – 任何具有未知内容类型的 URL。要么是因为未提供内容类型、内容类型不正确,要么是因为无法爬取 URL。被 robots.txt 阻止的 URL 也将出现在此处,例如,因为它们的文件类型未知。
外部链接
“外部链接”标签页包含有关外部 URL 的数据。被归类为“外部”的 URL 与爬取的起始页位于不同的子域名下。
列
此标签页包含以下列。
- Address – 外部 URL 地址
- Content – URL 的内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Crawl Depth – 页面与主页或起始页的深度(与起始页的“点击”次数)。
- Inlinks – 找到的指向外部 URL 的链接数量。
筛选器
此标签页包含以下筛选器。
- HTML – HTML 页面。
- JavaScript – 任何 JavaScript 文件。
- CSS – 发现的任何样式表。
- Images – 任何图像。
- PDF – 任何可移植文档文件。
- Flash – 任何 .swf 文件。
- Other – 任何其他文件类型,如文档等。
- Unknown – 任何具有未知内容类型的 URL。要么是因为未提供内容类型,要么是因为无法爬取 URL。被 robots.txt 阻止的 URL 也将出现在此处,例如,因为它们的文件类型未知。
安全性
“安全性”标签页显��示与爬取中内部 URL 的安全性相关的数据。
列
此标签页包含以下列。
- Address – 爬取的 URL。
- Content – URL 的内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- Canonical Link Element 1/2 等 – URL 上的 canonical 链接元素数据。如果存在多个实例,Spider 将找到所有实例。
- Meta Robots 1/2 等 – 在 URL 上找到的 Meta robots。如果存在多个实例,Spider 将找到所有实例。
- X-Robots-Tag 1/2 等 – X-Robots-tag 数据。如果存在多个实例,Spider 将找到所有实例。
筛选器
此标签页包含以下筛选器。
- HTTP URLs – 此过滤器将显示不安全的 (HTTP) URL。如今,所有网站都应该通过 HTTPS 在 Web 上进行安全访问。这不仅对安全性很重要,而且现在也是用户所期望的。Chrome 和其他浏览器会对任何 HTTP URL 或存在混合内容问题(即加载不安全资源)的 URL 显示“不安全”消息。
- HTTPS URLs – HTTP 的安全版本。所有内部 URL 都应该通过 HTTPS,因此应该出现在此过滤器下。
- 混合内容 – 这会显示任何通过安全 HTTPS 连接加载的 HTML 页面,这些页面具有通过不安全的 HTTP 连接加载的资源,例如图像、JavaScript 或 CSS。混合内容会削弱 HTTPS,并使页面更容易被窃听和危及原本安全的页面。浏览器可能会自动阻止 HTTP 资源加载,或者它们可能会尝试将其升级到 HTTPS。所有 HTTP 资源都应更改为 HTTPS,以避免安全问题以及在浏览器中加载时出现问题。
- 表单 URL 不安全 – HTML 页面上有一个表单,其 action 属性 URL 不安全 (HTTP)。这意味着输入到表单中的任何数据都不安全,因为它可能会在传输过程中被查看。网站上所有表单中包含的所有 URL 都应该被加密,因此需要使用 HTTPS。
- HTTP URL 上的表单 – 这意味着表单位于 HTTP 页面上。输入到表单中的任何数据,包括用户名和密码,都不安全。如果 Chrome 在 HTTP 页面上发现带有密码输入字段的表单,则会显示“不安全”消息。
- 不安全的跨域链接 – 使用 target=”_blank” 属性(在新选项卡中打开)链接到外部网站的 URL,但同时未使用 rel=”noopener”(或 rel=”noreferrer”)。单独使用 target=”_blank” 会使这些页面在某些旧版浏览器中面临安全和性能问题,据估计这些浏览器的市场份额低于 5%。在锚元素上设置 target=”_blank” 隐式提供与设置 rel=”noopener” 相同的 rel 行为,对于大多数现代浏览器(如 Chrome、Safari、Firefox 和 Edge)来说,它不会设置 window.opener。
- 协议相关的资源链接 – 此过滤器将显示任何使用协议相关链接加载资源(例如图像、JavaScript 和 CSS)的页面。协议相关链接只是一个不指定方案的 URL 链接(例如,//screamingfrog.co.uk)。它可以帮助开发人员节省指定协议的时间,并让浏览器根据与资源的当前连接来确定协议。但是,随着 HTTPS 的普及,这种技术现在已经过时,并且可能会使某些站点受到“中间人”攻击和性能问题的影响。
- 缺少 HSTS 标头 – 任何缺少 HSTS 响应标头的 URL。HTTP 严格传输安全响应标头 (HSTS) 指示浏览器应仅使用 HTTPS 而不是 HTTP 访问该网站。如果网站接受与 HTTP 的连接,然后在重定向到 HTTPS 之前,访问者最初仍将通过 HTTP 进行通信。HSTS 标头指示浏览器永远不要通过 HTTP 加载,并自动将所有请求转换为 HTTPS。
- 缺少 Content-Security-Policy 标头 – 任何缺少 Content-Security-Policy 响应标头的 URL。此标头允许网站控制为页面加载哪些资源。此策略可以帮助防范跨站点脚本 (XSS) 攻击,这些攻击利用浏览器对从服务器收到的内容的信任。SEO Spider 仅检查标头的存在,而不查询标头中找到的策略,以确定它们是否为网站设置良好。这应该手动执行。
- 缺少 X-Content-Type-Options 标头 – 任何缺少值为“nosniff”的“X-Content-Type-Options”响应标头的 URL。在缺少 MIME 类型的情况下,浏览器可能会“嗅探”以猜测内容类型,以便为用户正确解释它。但是,攻击者可能会利用这一点,他们可以尝试加载恶意代码,例如通过他们已入侵的图像加载 JavaScript。为了最大限度地减少这些安全问题,应提供 X-Content-Type-Options 响应标头并将其设置为“nosniff”。这指示浏览器仅依赖 Content-Type 标头并阻止任何不准确匹配的内容。
- 缺少 X-Frame-Options 标头 – 任何缺少值为“DENY”或“SAMEORIGIN”的 X-Frame-Options 响应标头的 URL。这指示浏览器不要在框架、iframe、embed 或对象中呈现页面。这有助于避免“点击劫持”攻击,在这种攻击中,您的内容显示在由攻击者控制的另一个网页上。
- 缺少安全 Referrer-Policy 标头 – 任何在 Referrer-Policy 标头中缺少“no-referrer-when-downgrade”、“strict-origin-when-cross-origin”、“no-referrer”或“strict-origin”策略的 URL。使用 HTTPS 时,重要的是 URL 不要泄漏到非 HTTPS 请求中。这可能会使用户遭受“中间人”攻击,因为网络上的任何人都可能查看它们。
- 错误的内容类型 – 这会显示任何实际内容类型与标头中设置的内容类型不匹配的 URL。它还会识别任何��使用的无效 MIME 类型。当服务器设置 X-Content-Type-Options: nosniff 响应标头时,这一点尤其重要,因为浏览器依赖内容类型标头来正确处理页面。例如,当 HTML 网页以 text/html 以外的 MIME 类型提供时,这可能会导致 HTML 网页被下载而不是被呈现。因此,所有响应都应在 content-type 标头中设置准确的 MIME 类型。
为了发现任何具有不安全元素(例如 HTTP 链接、规范链接、分页以及混合内容(图像、JS、CSS))的 HTTPS 页面,我们建议使用“报告”顶级菜单下的“不安全内容”报告。
响应代码
“响应代码”选项卡显示抓取中内部和外部 URL 的 HTTP 状态和状态代码。过滤器按常见的响应代码桶对 URL 进行分组。
列
此选项卡包括以下列。
- Address – 抓取的 URL。
- Content – URL 的内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- Inlinks – 指向 URL 的内部链接数。“内部链接”是指从正在抓取的同一子域指向给定 URL 的链接。
- Response Time – 下载 URL 的时间(以秒为单位)。更多详细信息可以在我们的常见问题解答中找到。
- Redirect URL – 如果地址 URL 重定向,则此列将包含重定向 URL 目标。上面的状态代码将显示重定向的类型,301、302 等。
- Redirect Type – 以下之一:HTTP Redirect:由 HTTP 标头触发;HSTS Policy:由于先前的 HSTS 标头,由 SEO Spider 在本地进行转换;JavaScript Redirect:由 JavaScript 的执行触发(只有在使用 JavaScript 渲染时才会发生);或 Meta Refresh Redirect:由页面的 HTML 中的 meta refresh 标记触发。
过滤器
此选项卡包括以下内部和外部 URL 的过滤器。
- 被 Robots.txt 阻止 – 所有被网站的 robots.txt 阻止的 URL。这意味着它们无法被抓取,如果您希望搜索引擎抓取和索引页面内容,这是一个关键问题。
- 被阻止的资源 – 所有被阻止渲染页面的资源,例如图像、JavaScript 和 CSS。这可能是由于 robots.txt,或者由于加载文件时出错。仅当启用 JavaScript 渲染时,此过滤器才会填充(在默认的“仅文本”抓取模式下,被阻止的资源将显示在“被 Robots.txt 阻止”下)。这��可能是一个问题,因为搜索引擎可能无法访问关键资源以准确地渲染页面。
- 无响应 – 当 URL 不向 SEO Spider 的 HTTP 请求发送响应时。通常是格式错误的 URL、连接超时、连接被拒绝或连接错误。应更新格式错误的 URL,并且通常可以通过调整 SEO Spider 配置来解决其他连接问题。
- 成功 (2XX) – 请求的 URL 已成功接收、理解、接受和处理。理想情况下,抓取中遇到的所有 URL 都将是状态代码“200”,状态为“OK”,这非常适合内容的抓取和索引。
- 重定向 (3XX) – 遇到重定向。这些将包括服务器端重定向,例如 301 或 302 重定向。理想情况下,所有内部链接都将指向规范解析 URL,并避免链接到重定向的 URL。这减少了用户重定向跳跃的延迟。
- 重定向 (JavaScript) – 遇到 JavaScript 重定向。理想情况下,所有内部链接都将指向规范解析 URL,并避免链接到重定向的 URL。这减少了用户重定向跳跃的延迟。
- 重定向 (Meta Refresh) – 遇到 meta refresh。理想情况下,所有内部链接都将指向规范解析 URL,并避免链接到重定向的 URL。这减少了用户重定向跳跃的延迟。
- 重定向链 – 重定向到另一个 URL 的内部 URL,该 URL 也会重定向。这可能会连续发生多次,每次重定向都称为“跳跃”。完整的重定向链可以通过“报告 > 重定向 > 重定向链”查看和导出。
- 重定向循环 – 重定向到另一个 URL 的内部 URL,该 URL 也会重定向。这可能会连续发生多次,每次重定向都称为“跳跃”。仅当 URL 重定向到重定向链中的先前 URL 时,此过滤器才会填充。带有循环的重定向链可以通过“报告 > 重定向 > 重定向链”查看和导出,并将“循环”列过滤为“True”。
- 客户端错误 (4xx) – 表示请求出现问题。这可能包括诸如 400 错误请求、403 禁止、404 页面未找到、410 已删除、429 请求过多 等响应。网站上的所有链接都应理想地解析为 200“OK”URL。应将 404 等错误更新到其正确位置,删除并在适当的地方重定向。
- 服务器错误 (5XX) – 服务器未能满足表面上有效的请求。这可能包括常见的响应,例如 500 内部服务器错误 和 503 服务器不可用。所有 URL 都应以 200“OK”状态响应,这可能表明服务器在负载下或需要调查的错误配置。
请参阅我们的 Learn SEO 指南中的 HTTP 状态代码,或者要解决使用 SEO Spider 时的响应问题,请阅读我们的 抓取时的 HTTP 状态代码 教程。
URL
“URL”选项卡显示与抓取中发现的 URL 相关的数据。过滤器显示为 URL 发现的常见问题。
列
此选项卡包括以下列。
- 地址 – 抓取的 URL。
- 内容 – URL 的内容类型。
- 状态代码 – HTTP 响应代码。
- 状态 – HTTP 标头响应。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因。 例如,如果它被规范化到另一个 URL。
- 哈希 – 页面的哈希值。 这是一个重复内容检查。 如果两个哈希值匹配,则页面内容完全相同。
- 长度 – URL 的字符长度。
- Canonical 1 – canonical 链接元素数据。
- URL 编码地址 – SEO Spider 实际请求的 URL。 所有非 ASCII 字符都经过百分比编码,有关更多详细信息,请参见 RFC 3986。
过滤器
此选项卡包含以下过滤器。
- 非 ASCII 字符 – URL 中包含 ASCII 字符集中未包含的字符。 标准规定 URL 只能使用 ASCII 字符集发送,并且某些用户可能难以处理此范围之外的字符的��细微差别。 URL 必须转换为有效的 ASCII 格式,方法是将链接编码为带有安全字符的 URL(由 % 后跟两个十六进制数字组成)。 如今,浏览器和搜索引擎在很大程度上能够准确地转换 URL。
- 下划线 – URL 中包含下划线,搜索引擎并不总是将其视为单词分隔符。 建议使用连字符作为单词分隔符。
- 大写 – URL 中包含大写字符。 URL 区分大小写,因此作为最佳实践,通常 URL 应为小写,以避免任何潜在的混淆和重复 URL。
- 多个斜杠 – URL 的路径中有多个正斜杠(例如,screamingfrog.co.uk/seo//)。 这通常是错误的,作为最佳实践,URL 的路径各部分之间应只有一个斜杠,以避免任何潜在的混淆和重复 URL。
- 重复路径 – URL 具有在 URL 字符串中重复的路径(例如,screamingfrog.co.uk/services/seo/technical/seo/)。 在某些情况下,这可能是合法的且合乎逻辑的,但它也通常指向不良的 URL 结构和潜在的改进。 它还可以帮助识别不正确的相对链接导致无限 URL 的问题。
- 包含空格 – URL 中包含空格。 这些被认为是不安全的,并且可能导致在共享 URL 时链接断开。 应使用连字符作为单词分隔符,而不��是空格。
- 内部搜索 – URL 可能是网站内部搜索功能的一部分。 Google 和其他搜索引擎建议阻止抓取内部搜索页面。 为避免 Google 索引被阻止的内部搜索 URL,也不应通过内部链接发现它们。
- 参数 – URL 包含参数,例如“?”或“&”。 这对于 Google 或其他搜索引擎抓取来说不是问题,但建议限制 URL 中的参数数量,这对于用户来说可能很复杂,并且可能是低价值附加 URL 的标志。
- 损坏的书签 – 具有损坏书签(也称为“命名锚点”、“跳转链接”和“跳过链接”)的 URL,这些书签使用 HTML 中的 ID 属性将用户链接到网页的特定部分,并将片段 (#) 和 ID 名称附加到 URL。 单击链接后,页面将滚动到带有书签的位置。 虽然这些链接对于用户来说非常有用,但在设置中很容易出错,并且随着页面更新以及 ID 更改或删除,它们通常会随着时间的推移而“损坏”。 损坏的书签意味着用户仍然会被带到正确的页面,但他们不会被定向到预期的部分。 虽然 Google 会将这些 URL 视为同一页面(因为它忽略了 # 中的任何内容),但他们可以使用命名锚点在搜索结果中为页面排名提供“跳转到”链接。 请参阅我们的如何查找损坏的书签指南。
- GA 跟踪参数 – 包含 Google Analytics 跟踪参数的 URL。 除了创建必须抓取的重复页面之外,在内部链接上使用跟踪参数可能会覆盖原始会话数据。 utm= 参数会剥离原始流量来源,并使用指定的属性启动新会话。 _ga= 和 _gl= 参数用于跨域链接并识别特定用户,在链接中包含此参数会阻止分配唯一的用户 ID。
- 超过 115 个字符 – URL 的长度超过 115 个字符。 这不一定是问题,但研究表明,用户更喜欢更短、更简洁的 URL 字符串。
页面标题
“页面标题”选项卡包含与抓取中内部 URL 的页面标题元素相关的数据。 过滤器显示了页面标题中发现的常见问题。
页面标题,通常称为“标题标签”、“元标题”或有时称为“SEO 标题”,是网页头部中的 HTML 元素,用于向用户和搜索引擎描述页面的用途。 它们被广泛认为是页面最强的页面排名信号之一。
页面标题元素应放置在文档的头部中,并且在 HTML 中如下所示:
<title>This Is A Page Title</title>
列
此选项卡�包含以下列。
- 地址 – 抓取的 URL。
- 出现次数 – 在页面上找到的页面标题的数量(SEO Spider 最多找到 2 个)。
- 标题 1/2 – 页面标题元素的内容。
- 标题 1/2 长度 – 页面标题的字符长度。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因。 例如,如果 URL 被规范化到另一个 URL,或者具有“noindex”等。
过滤器
此选项卡包含以下列。
- 缺失 – 任何缺少页面标题元素的页面,内容为空或包含空格。 用户和搜索引擎都会读取和使用页面标题来了解页面的用途。 因此,页面具有简洁、描述性和唯一的页面标题至关重要。
- 重复 – 任何具有重复页面标题的页面。 为每个页面设置不同的唯一页面标题非常重要。 如果每个页面都具有相同的页面标题,那么用户和搜索引擎更难区分一个页面与另一个页面。
- 超过 60 个字符 – 任何页面标题长度超过 60 个字符的页面。 超过此限制的字符可能会在 Google 的搜索结果中被截断,并且在评分中的权重会降低。
- 低于 30 个字符 – 任何页面标题长度低于 30 个字符的页面。 这不一定是问题,但您有更多空间来定位其他关键字或传达您的 USP。
- 超过 X 像素 – Google 代码段长度实际上是基于像素限制,而不是字符长度。 SEO Spider 尝试匹配 SERP 中的最新像素截断点,但这只是一个近似值,Google 会经常调整它们。 此过滤器显示任何页面标题长度超过 X 像素的页面。
- 低于 X 像素 – 任何页面标题长度低于 X 像素的页面。 这不一定是坏事,但您有更多空间来定位其他关键字或传达您的 USP。
- 与 h1 相同 – 任何页面标题与页面上的 h1 完全匹配的页面。 这不一定是问题,但可能指出了定位替代关键字、同义词或相关关键短语的潜在机会。
- 多个 – 任何具有多个页面标题的页面。 一个页面应该只有一个页面标题元素。 多个页面标题通常是由 CMS 中多个冲突的插件或模块引起的。
- 在
<head>之外 – 标题元素位于 HTML 中 head 元素��之外的页面。 页面标题应位于 head 元素内,否则搜索引擎可能会忽略它。 即使在 head 元素之外,Google 通常仍然会识别页面标题,但不应依赖于此。
Meta description
“Meta description”选项卡包含与抓取中内部 URL 的 meta description 相关的数据。 过滤器显示了 meta description 中发现的常见问题。
Meta description 是网页头部中的 HTML 属性,用于向用户提供页面摘要。 Google 不会将描述中的单词用于排名,但它们可以显示在搜索结果中供用户查看,因此会严重影响点击率。
Meta description 应放置在文档的头部中,并且在 HTML 中如下所示:
<meta name="description" content="This is a meta description."/>
列
此选项卡包含以下列。
- 地址 – 抓取的 URL。
- 出现次数 – 在页面上找到的 meta description 的数量(我们最多找到 2 个)。
- Meta Description 1/2 – meta description。
- Meta Description 1/2 长度 – meta description 的字符长度。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因。 例如,如果 URL 被规范化到另一个 URL。
过滤器
此选项卡包含以下过滤器。
- 缺失 – 任何缺少 meta description 的页面,内容为空或包含空格。 这是一个错失的机会,无法传达您的产品或服务的优势,并影响重要 URL 的点击率。
- 重复 – 任何具有重复 meta description 的页面。 拥有不同的唯一 meta description 来传达每个页面的优势和用途非常重要。 如果它们是重复的或无关紧要的,那么它们将被搜索引擎忽略。
- 超过 155 个字符 – 任何 meta description 长度超过 155 个字符的页面。 超过此限制的字符可能会在 Google 的搜索结果中被截断。
- 低于 70 个字符 – 任何 meta description 长度低于 70 个字符的页面。 这不是一个严格的问题,而是一个机会。 有额外的空间来传达优势、USP 或号召性用语。
- 超过 X 像素 – Google 代码段长度实际上是基于像素限制,而不是字符长度。 SEO Spider 尝试匹配 SERP 中的最新像素截断点,但这只是一个近似值,Google 会经常调整它们。 此过滤器显示任何描述长度超过 X 像素的页面,并且可能会在 Google 的搜索结果中被截断。
- 低于 X 像素 – 任何 meta description 长度低于 X 像素的页面。 这不是一个严格的问题,而是一个机会。 有额外的空间来传达优势、USP 或号召性用语。
- 多个 – 任何具有多个 meta description 的页面。 一个页面应该只有一个 meta description。 多个 meta description 通常是由 CMS 中多个冲突的插件或模块引起的。
- 在
<head>之外 – meta description 位于 HTML 中 head 元素之外的页面。 meta description 应位于 head 元素内,否则搜索引擎可能会忽略它。
请参阅我们的 Learn SEO 指南中的 Meta Descriptions写作。
Meta keywords
“Meta keywords”选项卡包含与 meta keywords 相关的数据。 过滤器显示了 meta keywords 中发现的常见问题。
Meta keywords 在很大程度上被搜索引擎忽略,并且它们不用作所有主要西方搜索引擎评分的信号。 特别是,Google 在对其搜索结果排名中的页面进行评分时根本不考虑它。 因此,我们建议完全忽略它,除非您定位的是其他搜索引擎。
Yandex 或 Baidu 等其他搜索引擎可能仍会在排名中使用它们,但我们建议在花时间优化它们之前对此状态进行研究。
meta keywords 标签应放置在文档的头部中,并且在 HTML 中如下所示
:
<meta name="keywords" content="seo, seo agency, seo services"/>
列
此选项卡包含以下列。
- Address – 抓取的 URL。
- Occurrences – 页面上找到的 meta keywords 的数量(我们最多找到 2 个)。
- Meta Keyword 1/2 – meta keywords。
- Meta Keyword 1/2 length – meta keywords 的字符长度。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
过滤器
此选项卡包含以下过滤器。
- Missing – 任何缺少 meta keywords 的页面。 如果您以 Google、Bing 和 Yahoo 为目标,那么这很好,因为它们不会在排名中使用它们。 如果您以百度或 Yandex 为目标,那么您可能希望考虑包含相关的目标关键词。
- Duplicate – 任何具有重复 meta keywords 的页面。 如果您以百度或 Yandex 为目标,那么建议使用与页面目的相关的唯一关键��词。
- Multiple – 任何具有多个 meta keywords 的页面。 页面上应该只有一个标签。
h1
h1 选项卡显示与页面的 <h1> 标题相关的数据。 过滤器显示了为 <h1> 发现的常见问题。
<h1> 到 <h6> 标签用于定义 HTML 标题。 <h1> 被认为是页面最重要的第一个主标题,而 <h6> 被认为是最不重要的。
标题应按大小和重要性排序,它们可以帮助用户和搜索引擎理解页面和部分的内容。 <h1> 应该描述页面的主要标题和目的,并且被广泛认为是更强的页面排名信号之一。
<h1> 元素应放置在文档的正文中,在 HTML 中如下所示:
<h1>This Is An h1</h1>
默认情况下,SEO Spider 将仅提取并报告在页面上发现的前两个 <h1>。 如果您希望提取所有 h1,那么我们建议使用自定义提取。
列
此选项卡包含以下列。
- Address – 抓取的 URL。
- Occurrences – 页面上找到的
<h1>的数量。 如上所述,我们最多找到 2 个。 - h1-1/2 –
<h1>的内容。 - h1-length-1/2 –
<h1>的字符长度。 - Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被�规范化到另一个 URL。
过滤器
此选项卡包含以下过滤器。
- Missing – 任何缺少
<h1>的页面,内容为空或包含空格。 用户和搜索引擎都会读取和使用<h1>来理解页面的目的。 因此,页面具有简洁、描述性和唯一的标题至关重要。 - Duplicate – 任何具有重复
<h1>的页面。 拥有独特、唯一和有用的页面非常重要。 如果每个页面都有相同的<h1>,那么用户和搜索引擎可能更难以区分一个页面与另一个页面。 - Over 70 characters – 任何
<h1>长度超过 70 个字符的页面。 这不是一个严格的问题,因为标题没有字符限制。 但是,它们对于用户和搜索引擎来说应该是简洁和描述性的。 - Multiple – 任何具有多个
<h1>的页面。 虽然这并非严格意义上的问题,因为 HTML5 标准允许页面上有多个<h1>,但在可用性方面,这种现代方法存在一些问题。 建议使用标题等级(h1–h6)来传达文档结构。 经典的 HTML4 标准定义每个页面应该只有一个<h1>�,这仍然是用户和 SEO 的普遍建议。 - Alt Text in h1 – 在 h1 中包含图像 alt 文本的页面。 这可能是因为图像中的文本被认为是页面上的主要标题,或者由于不适当的标记。 一些 CMS 模板会自动在网站上的徽标周围包含一个 h1。 虽然有强烈的论点认为标题应该使用文本而不是 alt 文本,但搜索引擎可能会将 h1 中的 alt 文本理解为 h1 的一部分,并据此进行评分。
- Non-sequential – h1 不是页面上第一个标题的页面。 标题元素应按逻辑顺序降序排列。 标题元素的目的是传达页面的结构,它们应该从 h1 到 h6 按逻辑顺序排列,这有助于浏览页面以及依赖辅助技术的用户。
请参阅我们的 Learn SEO 指南中的 Heading Tags。
h2
h2 选项卡显示与页面的 <h2> 标题相关的数据。 过滤器显示了为 <h2> 发现的常见问题。
<h1> 到 <h6> 标签用于定义 HTML 标题。 <h2> 被认为是页面上第二个重要的标题,通常大小和样式设置为第二大标题。
<h2> 标题通常用于描述文档中的部分或主题。 它们充当用户的路标,并可以帮助搜索引擎理解页面。
<h2> �元素应放置在文档的正文中,在 HTML 中如下所示:
<h2>This Is An h2</h2>
默认情况下,SEO Spider 将仅提取并报告在页面上发现的前两个 h2。 如果您希望提取所有 h2,那么我们建议使用自定义提取。
列
此选项卡包含以下列。
- Address – 抓取的 URL。
- Occurrences – 页面上找到的
<h2>的数量。 如上所述,我们最多找到 2 个。 - h2-1/2 –
<h2>的内容。 - h2-length-1/2 –
<h2>的字符长度。 - Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
过滤器
此选项卡包含以下过滤器。
- Missing – 任何缺少
<h2>的页面,内容为空或包含空格。 用户和搜索引擎都会读取和使用<h2>来理解页面和部分的内容。 理想情况下,大多数页面都应具有逻辑、描述性的<h2>。 - Duplicate – 任何具有重复
<h2>的页面。 拥有独特、唯一和有用的页��面非常重要。 如果每个页面都有相同的<h2>,那么用户和搜索引擎可能更难以区分一个页面与另一个页面。 - Over 70 characters – 任何
<h2>长度超过 70 个字符的页面。 这不是一个严格的问题,因为标题没有字符限制。 但是,它们对于用户和搜索引擎来说应该是简洁和描述性的。 - Multiple – 任何具有多个
<h2>的页面。 这不是一个问题,因为 HTML 标准允许在逻辑分层标题结构中使用多个<h2>。 但是,此过滤器可以帮助您快速扫描以查看它们是否被正确使用。 - Non-sequential – h2 不是页面上 h1 之后的第二个标题级别的页面。 标题元素应按逻辑顺序降序排列。 标题元素的目的是传达页面的结构,它们应该从 h1 到 h6 按逻辑顺序排列,这有助于浏览页面以及依赖辅助技术的用户。
请参阅我们的 Learn SEO 指南中的 Heading Tags。
Content
“Content”选项卡显示与抓取中发现的内部 HTML URL 的内容相关的数据。
这包括字数统计、可读性、重复和近似�重复内容,以及拼写和语法错误。
列
此选项卡包含以下列。
- Address – URL 地址。
- Word Count – 这是 body 标签内的所有“单词”,不包括 HTML 标记。 该计数基于可在“Config > Content > Area”下调整的内容区域。 默认情况下,nav 和 footer 元素被排除。 您可以包含或排除 HTML 元素、类和 ID 以计算更精确的字数统计。 我们的数字可能与手动执行此计算的结果不完全相同,因为解析器会对无效 HTML 执行某些修复。 您的渲染设置也会影响被视为 HTML 的内容。 我们对单词的定义是获取文本并按空格分隔。 不考虑内容的可视性(例如,设置为隐藏的 div 中的文本)。
- Average Words Per Sentence – 内容区域中的单词总数除以发现的句子总数。 这是作为 Flesch 可读性分析的一部分计算的。
- Flesch Reading Ease Score – Flesch 阅读易读性测试衡量文本的可读性。 这是一个广泛使用的可读性公式,它使用句子的平均长度和每个单词的平均音节数来提供 0-100 之间的分数。 0 非常难以阅读,最好由大学毕业生理解,而 100 非常容易阅读,可以被 11 岁的学生理解。
- Readability – 基于 Flesch 阅读易读性分数和记录的分数组的整体可读性评估分类。
- Closest Similarity Match – 这显示了近似重复 URL 的��最高相似度百分比。 SEO Spider 将识别具有 90% 相似度匹配的近似重复项,可以调整该匹配以查找具有较低相似度阈值的内容。 例如,如果一个页面有两个近似重复页面,相似度分别为 99% 和 90%,则此处将显示 99%。 要填充此列,必须通过“Config > Content > Duplicates”选择“Enable Near Duplicates”配置,并且必须执行后期“Crawl Analysis”。 只有内容超过所选相似度阈值的 URL 才会包含数据,其他 URL 将保持空白。 因此,默认情况下,此列仅包含相似度为 90% 或更高的 URL 的数据,除非已通过“Config > Content > Duplicates”和“Near Duplicate Similarity Threshold”设置对其进行了调整。
- No. Near Duplicates – 在抓取中发现的满足或超过“Near Duplicate Similarity Threshold”的近似重复 URL 的数量,默认情况下为 90% 匹配。 可以在“Config > Content > Duplicates”下调整此设置。 要填充此列,必须通过“Config > Content > Duplicates”选择“Enable Near Duplicates”配置,并且必须执行后期“Crawl Analysis”。
- Total Language Errors – 为 URL 发现的拼写和语法错误总数。 要填充此列,必须通过“Config > Content > Spelling & Grammar”选择“Enable Spell Check”或“Enable Grammar Check”。
- Spelling Errors – 为 URL 发现的拼写错误总数。 要填充此列,必须通过“Config > Content > Spelling & Grammar”选择“Enable Spell Check”。
- Grammar Errors – 为 URL 发现的语法错误总数。 要填充此列,必须通过“Config > Content > Spelling & Grammar”选择“Enable Grammar Check”。
- Language – 为拼写和语法检查选择的语言。 这基于 HTML 语言属性,但也可以通过“Config > Content > Spelling & Grammar”设置语言。
- Hash – 使用 MD5 算法的页面哈希值。 这是仅针对完全重复内容的重复内容检查。 如果两个哈希值匹配,则页面的内容完全相同。 如果存在单个字符差异,它们将具有唯一的哈希值,并且不会被检测为重复内容。 因此,这不是对近似重复内容的检查。 可以在“Content > Exact Duplicates”下查看完全重复项。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
过滤器
此选项卡包含以下过滤器。
- 完全重复 – 此��筛选器将显示彼此完全相同的页面,它使用 MD5 算法为每个页面计算一个“哈希”值,该值可以在“哈希”列中看到。此检查是针对页面的完整 HTML 执行的。它将显示所有具有匹配哈希值的完全相同的页面。完全重复的页面可能导致 PageRank 信号的分裂和排名的不可预测性。应该只有一个规范版本的 URL 存在并内部链接到它。其他版本不应被链接,并且它们应该 301 重定向到规范版本。
- 近似重复 – 此筛选器将基于配置的相似度阈值,使用 minhash 算法显示相似的页面。可以在“配置 > 内容 > 重复项”下调整阈值,默认设置为 90%。 “最接近的相似度匹配”列显示与另一个页面的最高相似度百分比。“近似重复项数量”列显示基于相似度阈值与该页面相似的页面数量。该算法针对页面上的文本运行,而不是像完全重复项那样针对完整的 HTML。用于此分析的内容可以在“配置 > 内容 > 区域”下配置。页面可能具有 100% 的相似度,但仅是“近似重复项”而不是完全重复项。这是因为完全重复项被排除为近似重复项,以避免它们被标记两次。相似度分数也会四舍五入,因此 99.5% 或更高将显示为 100%。要填充此列,必须通过“配置 > 内容 > 重复项“选择“启用近似重复项”配置,并且必须执行后“抓取分析”。
- 低内容页面 – 这将显示任何默认字数低于 200 个字的 HTML 页面。字数基于分析中使用的内容区域设置,可以通过“配置 > 内容 > 区域”进行配置。实际上页面没有最小字数限制,但搜索引擎确实需要描述性文本来理解页面的目的。此筛选器仅应用作粗略指南,以帮助识别可以通过在网站和页面目的的上下文中添加更多描述性内容来改进的页面。某些网站(例如电子商务)自然会有较低的字数,如果可以有效地传达产品详细信息,这是可以接受的。用于低内容页面筛选器的字数可以通过“配置 > Spider > 首选项 > 低内容字数“调整为您自己的偏好。
- 软 404 页面 – 响应“200”状态代码的页面,表明它们是“OK”,但看起来像是错误页面 – 通常称为“404”或“找不到页面”。如果该页面不再可用,这些页面通常应响应 404 状态代码。通过查找页面上使用的常见错误文本来识别这些页面,例如“找不到页面”或“找不到 404 页面”。用于识别这些页面的文本可以在“配置 > Spider > 首选项”下配置。
- 拼写错误 – 此筛选器包含任何具有拼写错误的 HTML 页面。要填充此筛选器和相应的列,必须通过“配置 > 内容 > 拼写和语法“选择“启用拼写检查”。
- 语法错误 – 此筛选器包含任何具有语法错误的 HTML 页面。要填充此列,必须通过“配置 > 内容 > 拼写和语法“选择“启用语法检查”。
- 可读性困难 – 根据 Flesch 易读性评分公式,页面上的副本难以阅读,最好由大学毕业生理解。具有长句子并使用复杂单词的副本通常更难阅读和理解。考虑提高目标受众的副本可读性。使用较短句子和较少复杂单词的副本通常更容易阅读和理解。
- 可读性非常困难 – 根据 Flesch 易读性评分公式,页面上的副本非常难以阅读,最好由大学毕业生理解。具有长句子并使用复杂单词的副本通常更难阅读和理解。考虑提高目标受众的副本可读性。使用较短句子和较少复杂单词的副本通常更容易阅读和理解。
- Lorem Ipsum 占位符 – 包含“Lorem ipsum”文本的页面,该文本通常用作占位符来演示网页的视觉形式。这可能会错误地留在网页上,尤其是在新的网站构建期间。
请参阅我们的 Learn SEO 指南,了解 重复内容,以及我们的“如何检查重复内容“教程。
图片
“图片”选项卡显示与抓取中发现的任何图片相关的数据。这包括内部和外部图片,通过 <img src= 标签或 <a href= 标签发现。筛选器显示为图片及其 alt 文本发现的常见问题。
可以通过单击图片,然后在底部单击“图片详细信息”选项卡来查看图片 alt 属性(通常被错误地称为“alt 标签”),该选项卡会填充下部窗口选项卡。
Alt 属性应指定有关图片用途的相关且描述性的替代文本,并出现在 HTML 的源代码中,如下例所示。
<img src="screamingfrog-logo.jpg" alt="Screaming Frog" />
装饰性图片应提供空(空)alt 文本 (alt=””),以便辅助技术(例如屏幕阅读器)可以忽略它们,而不是根本不包含 alt 属性。
<img src="decorative-frog-space.jpg" alt="" />
列
此选项卡包括以下列。
- 地址 – 抓取的 URL。
- 内容 – 图片的内容类型(jpeg、gif、png 等)。
- 大小 – 图片的大小(以千字节为单位)。文件大小在导出中以字节为单位,因此除以 1,024 转换为千字节。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因��。例如,如果它被规范化到另一个 URL。
筛选器
此选项卡包括以下筛选器。
- 超过 100kb – 大于 100kb 的大型图片。页面速度对于用户和 SEO 至关重要,通常像图片这样的大型资源是减慢网页速度的最常见问题之一。此筛选器仅充当一般经验法则,以帮助识别文件大小相当大且可能需要更长时间加载的图片。应考虑优化这些图片,以及在 PageSpeed 选项卡中识别的机会,该选项卡使用 PSI API 和 Lighthouse 来审核速度。这可以帮助识别未优化大小、离屏加载、未优化等的图片。
- 缺少 Alt 文本 – 具有 alt 属性但缺少 alt 文本的图片。单击图片的地址 (URL),然后在下部窗口窗格中单击“图片详细信息”选项卡,以查看哪些页面上有该图片,以及哪些页面缺少该图片的 alt 文本。图片应具有关于其用途的描述性替代文本,这有助于盲人和视障人士以及搜索引擎理解它及其与网页的相关性。对于装饰性图片,应提供空(空)alt 文本 (alt=””),以便辅助技术(例如屏幕阅读器)可以忽略它们。
- 缺少 Alt 属性 – 完全缺少 alt 属性的图片。单击图片��的地址 (URL),然后在下部窗口窗格中单击“图片详细信息”选项卡,以查看哪些页面上有该图片,以及缺少 alt 属性。所有图片都应包含带有描述性文本的 alt 属性,或者在它是装饰性图片时为空白。
- Alt 文本超过 100 个字符 – alt 文本长度超过 100 个字符的图片。这并非严格来说是一个问题,但是图片 alt 文本应该简洁且具有描述性。它不应用于在页面上填充大量关键字或文本段落。
- 背景图片 – 在整个网站上发现的 CSS 背景和动态加载的图片,应用于非关键和装饰性目的。Google 通常不会索引背景图片,并且浏览器不会在背景图片上向辅助技术提供 alt 属性或文本。要填充此筛选器,必须启用 JavaScript 渲染,并且需要执行 抓取分析。
- 缺少大小属性 – HTML 中未指定尺寸(宽度和高度大小属性)的图片元素。这可能会导致页面加载时出现较大的布局偏移,并给用户带来令人沮丧的体验。它是导致高累积布局偏移 (CLS) 的主要原因之一。
- 大小不正确的�图片 – 识别出其实际尺寸 (WxH) 与渲染时显示的尺寸不匹配的图片。如果估计的文件大小差异为 4kb 或更多,则该图片将被标记为可能需要优化。特别是,这可以帮助识别过大的图片,这可能会导致页面加载速度慢。它还可以帮助识别在渲染时被拉伸的较小尺寸的图片。要填充此筛选器,必须启用 JavaScript 渲染,并且需要执行 抓取分析。
有关优化图片的更多信息,请阅读我们的指南 如何查看 Alt 文本并查找缺少的 Alt 文本,并考虑使用 PageSpeed Insights 集成。这具有“正确调整图片大小”、“延迟离屏图片”、“高效编码图片”、“以下一代格式提供图片”和“图片元素没有明确的宽度和高度”的机会和诊断。
Canonicals
“Canonicals”选项卡显示在抓取期间发现的规范链接元素和 HTTP canonicals。筛选器显示为 canonicals 发现的常见问题。
当页面可以通过多个 URL 访问时,rel=”canonical” 元素有助于指定页面的单个首选版本。它是搜索引擎的提示,通过将索引和链接属性合并到单个 URL 以用于排名,从而帮助防止重复内容。
规范链接元素应放置在文档的 head 中,并在 HTML 中如下所示:
<link rel="canonical" href="https://www.example.com/" >
您还可以使用 rel=”canonical” HTTP 标头,如下所示:
Link: <http://www.example.com>; rel="canonical"
列
此选项卡包括以下列。
- 地址 – 抓取的 URL。
- 出现次数 – 找到的 canonicals 数量(通过链接元素和 HTTP)。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- 规范链接元素 1/2 等 – URL 上的规范链接元素数据。如果有多个,SEO Spider 将找到所有实例。
- HTTP Canonical 1/2 等 – 通过 HTTP 发布的 Canonical。如果有多个,SEO Spider 将找到所有实例。
- Meta Robots 1/2 等 – 在 URL 上找到的 Meta robots。如果有多个,SEO Spider 将找到所有实例。
- X-Robots-Tag 1/2 等 – X-Robots-tag 数据。如果有多个,SEO Spider 将找到所有实例。
- rel=“next” 和 rel=“prev” – SEO Spider 收集这些 HTML 链接元素,旨在指示分页系列中 URL 之间的关系。
筛选器
此选项卡包括以下筛选器。
- 包含规范网址 – 页面已设置规范网址(通过 link 元素、HTTP 标头或两者)。这可以是自引用规范网址,其中页面 URL 与规范 URL 相同,也可以是“规范化”网址,其中规范 URL 与页面 URL 不同。
- 自引用 – 该 URL 具有一个规范网址,该网址与抓取的页面 URL 相同(因此,它是自引用的)。理想情况下,只有规范版本的 URL 才会在内部链接,并且每个 URL 都会有一个自引用规范网址,以帮助避免可能发生的任何潜在重复内容问题(即使在网络上自然发生,例如 URL 上的跟踪参数,其他网站错误地链接到解析的 URL 等)。
- 已规范化 – 页面具有与其自身不同的规范 URL。该 URL 已“规范化”到另一个位置。这意味着搜索引擎被指示不要索引该页面,并且索引和链接属性应合并到目标规范 URL。应仔细审查这些 URL。在一个完美的世界中,网站不需要规范化任何 URL,因为只会链接到规范版本,但通常由于无法控制的各种情况以及为了防止重复内容而需要规范化。
- 缺失 – 没有规范 URL 作为 link 元素或通过 HTTP 标头存在。如果页面未指示规范 URL,则 Google 将识别他们认为的最佳版本或 URL。这可能导致排名不可预测,因此通常所有 URL 都应指定规范版本。
- 多个 – 一个 URL 设置了多个规范网址(多个 link 元素、HTTP 标头或两者组合)。这可能导致不可预测性,因为对于一个页面,应该只有一个规范 URL 由单个实现(link 元素或 HTTP 标头)设置。
- 多个冲突 – 页面为一个 URL 设置了多个规范网址,这些规范网址指定了不同的 URL(通过多个 link 元素、HTTP 标头或两者组合)。这可能导致不可预测性,因为对于一个页面,应该只有一个规范 URL 由单个实现(link 元素或 HTTP 标头)设置。
- 不可索引的规范网址 – 规范 URL 是不可索引的页面。这将包括被 robots.txt 阻止、无响应、重定向 (3XX)、客户端错误 (4XX)、服务器错误 (5XX) 或“noindex”的规范网址。URL 的规范版本应始终是可索引的“200”响应页面。因此,应将转到不可索引页面的规范网址更正为解析的可索引版本。
- 规范网址是相对的 – 具有相对而非绝对 rel=”canonical” link 标签的页面。虽然该标签(如许多 HTML 标签一样)接受相对和绝对 URL,但很容易在相对路径中犯细微的错误,这可能会导致与索引相关的问题。
- 未链接 – 仅通过 rel=”canonical” 发现且未通过网站上的超链接链接到的 URL。这可能表明内部链接存在问题,或者规范网址中包含的 URL 存在问题。
- 注释中的属性无效 – 具有 rel=”canonical” 注释的页面,该注释包含使用 hreflang、lang、media 或 type 属性的备用版本。向 link 元素添加某些属性会更改注释的含义,以表示不同的设备或语言版本��。Google 会忽略这些注释,并且不会将其用于规范化。
- 包含片段 URL – 具有 rel=”canonical” 的页面,该页面在 href 属性中包含片段 URL。Google 通常不支持片段 URL。Google 会忽略这些注释,并且不会将其用于规范化。
- 在
<head>之外 – 具有规范 link 元素位于 HTML 中 head 元素之外的页面。规范 link 元素应位于 head 元素内,否则搜索引擎将忽略它。
请参阅我们的 Learn SEO 指南中的 规范网址,以及我们的“ 如何审核规范网址”教程。
分页
“分页”选项卡包含在抓取中发现的 rel=”next” 和 rel=”prev” HTML link 元素的信息,这些元素用于指示分页系列中组件 URL 之间的关系。过滤器显示了分页中发现的常见问题。
虽然 Google 在 2019 年 3 月 21 日宣布他们长期以来没有在索引中使用 rel=”next” 和 rel=”prev”,但其他搜索引擎(如 Bing(也为 Yahoo 提供支持))仍然将其用作发现和理解网站结构的提示。
分页属性应放置在文档的 head 中,并且在 HTML 中如下所示:
<link rel="prev" href="https://www.example.com/seo/"/> <link rel="next" href="https://www.example.com/seo/page/2/"/>
列
此选项卡包含以下列。
- 地址 – 抓取的 URL。
- 出现次数 – 找到的规范网址的数量(通过 link 元素和 HTTP)。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- rel=“next” – SEO Spider 收集这些 HTML link 元素,这些元素旨在指示分页系列中 URL 之间的关系。
- rel=“prev” – SEO Spider 收集这些 HTML link 元素,这些元素旨在指示分页系列中 URL 之间的关系。
- Canonical Link Element 1/2 etc – URI 上的规范 link 元素数据。如果有多个,SEO Spider 将找到所有实例。
- HTTP Canonical 1/2 etc – 通过 HTTP 发出的规范网址。如果有多个,SEO Spider 将找到所有实例。
- Meta Robots 1/2 etc – 在 URI 上找到的 Meta robots。如果有多个,SEO Spider 将找到所有实例。
- X-Robots-Tag 1/2 etc – X-Robots-tag 数据。如果有多个,SEO Spider 将找到所有实例。
过滤器
此选项卡包含以下过滤器。
- 包含分页 – URL 具有 rel=”next” 和/或 rel=”prev” 属性,表明它是分页系列的一部分。
- 第一页 – URL 仅具有 rel=“next” 属性,表明它是分页系列中的第一页。滚动浏览这些 URL 并确保它们已在系列中的父页面上准确实现非常容易且有用。
- 分页 2+ 页 – URL 上具有 rel=“prev”,表明它不是第一页,而是系列中的分页页面。同样,滚动浏览这些 URL 并确保只有分页页面出现在此过滤器下非常有用。
- 锚标记中没有分页 URL – 页面 rel=”next” 和 rel=”prev” 属性中包含的 URL 未在页面本身的 HTML 锚元素中找到作为超链接。分页页面应与常规链接链接,以允许用户单击并导航到系列中的下一页。它们还允许 Google 从一个页面爬到另一个页面,并允许 PageRank 在系列中的页面之间流动。Google 自己的网站站长趋势分析师 John Mueller 在 Google 网站站长中心环聊中也 推荐了用于分页的正确 HTML 链接。
- 非 200 分页 URL – rel=”next” 和 rel=”prev” 属性中包含的 URL 未以 200“OK”状态代码响应。这可能包括被 robots.txt 阻止的 URL、无响应、3XX(重定向)、4XX(客户端错误)或 5XX(服务器错误)。分页 URL 必须是可抓取和可索引的,因此非 200 URL 被视为错误,并被搜索引擎忽略。非 200 分页 URL 可以通过“报告 > 分页 > 非 200 分页 URL”导出批量导出。
- 未链接的分页 URL – rel=”next” 和 rel=”prev” 属性中包含的 URL 未在整个网站上链接。分页属性可能不会像传统的锚元素那��样传递 PageRank,因此这可能表明内部链接存在问题,或者分页属性中包含的 URL 存在问题。未链接的分页 URL 可以通过“报告 > 分页 > 未链接的分页 URL”导出批量导出。
- 不可索引 – 分页 URL 不可索引。通常,它们都应该是可索引的,除非设置了“查看全部”页面,或者分页 URL 上有额外的参数,并且它们需要规范化为单个 URL。最常见的错误之一是将第 2+ 页分页页面规范化为系列中的第一页。Google 不建议这样做,因为组件页面实际上并不包含重复内容。另一个常见的错误是使用“noindex”,这可能意味着 Google 从索引中完全删除分页 URL,并停止跟踪这些页面中的出站链接,这对于这些页面上的产品来说可能是一个问题。此过滤器将帮助识别这些常见的设置问题。
- 多个分页 URL – 页面上有多个 rel=”next” 和 rel=”prev” 属性(当不应超过单个 rel=”next” 或 rel=”prev” 属性时)。这可能意味着它们被搜索引擎忽略。
- 分页循环 – 这将显示具有 rel=”next” 和 rel=”prev” 属性的 URL,这些属性循环回到先前遇到的 URL。同样,这可能意味着搜索引擎只是忽略了表达的分页系列。
- 序列错误 – 这显示了 rel=”next” 和 rel=”prev” HTML link 元素序列中存在错误的 URL。此检查确保 rel=”next” 和 rel=”prev” HTML link 元素中包含的 URL 相互呼应并确认它们在系列中的关系。
有关分页的更多信息,请阅读我们的指南“ 如何审核 rel=”next” 和 rel=”prev” 分页属性”。
指令
“指令”选项卡显示与 meta robots 标签和 HTTP 标头中的 X-Robots-Tag 相关的数据。这些 robots 指令可以控制您的内容和 URL 在搜索引擎(如 Google)中的显示方式。
meta robots 标签应放置在文档的 head 中,并且“noindex”meta 标签的示例如下所示:
<meta name="robots" content="noindex"/>
可以使用 X-Robots-Tag 在 HTTP 标头中发出相同的指令,如下所示:
X-Robots-Tag: noindex
列
此选项卡包含以下列。
- 地址 – 抓取的 URL。
- Meta Robots 1/2 etc – 在 URL 上找到的 Meta robots 指令。如果有多个,SEO Spider 将找到所有实例。
- X-Robots-Tag 1/2 etc – URL 的 X-Robots-tag HTTP 标头指令。如果有多个,SEO Spider 将找到所有实例。
过滤器
此选项卡包含以下过滤器。
- Index – 这允许页面被索引。这是不必要的,因为搜索引擎会在没有它的情况下��索引 URL。
- Noindex – 这指示搜索引擎不要索引该页面。该页面仍将被抓取(以查看指令),但随后将从索引中删除。带有“noindex”的 URL 应仔细检查。
- Follow – 这指示抓取页面上的任何链接。这是不必要的,因为搜索引擎默认会跟踪它们。
- Nofollow – 这是一个“提示”,告诉搜索引擎不要跟踪页面上的任何链接进行抓取。这通常与“noindex”结合使用时会出错,因为没有必要包含此指令。要抓取带有 meta nofollow 标签的页面,必须在“Config > Spider”下启用配置“Follow Internal Nofollow”。
- None – 这并不意味着没有指令。这意味着正在使用 meta 标签“none”,这相当于“noindex, nofollow”。应仔细检查这些 URL,以确保它们被正确地排除在搜索引擎索引之外。
- NoArchive – 这指示 Google 不要显示搜索结果中页面的缓存链接。
- NoSnippet – 这指示 Google 不要显示搜索结果中的文本摘要或视频预览。
- Max-Snippet – 此值允许您将此页面的文本摘要长度限制为 Google 中的 [number] 个字符。特殊值包括 – 0 表示没有摘要,-1 表示允许任何摘要长度。
- Max-Image-Preview – 此值可以限制与 Google 中此页面关联的任何图像的大小。设置值可�以是“none”、“standard”或“large”。
- Max-Video-Preview – 此值可以将与 Google 中此页面关联的任何视频预览限制为 [number] 秒。您还可以指定 0 以仅允许静态图像,或 -1 以允许任何预览长度。
- NoODP – 这是一个旧的 meta 标签,用于指示 Google 不要使用开放目录项目作为其摘要。可以删除此标签。
- NoYDIR – 这是一个旧的 meta 标签,用于指示 Google 不要使用 Yahoo Directory 作为其摘要。可以删除此标签。
- NoImageIndex – 这告诉 Google 不要将该页面显示为图像搜索结果中图像的引用页面。这会阻止此页面上的所有图像在此页面中被索引。
- NoTranslate – 此值告诉 Google 您不希望他们为此页面提供翻译。
- Unavailable_After – 这允许您指定您希望 Google 停止在其搜索结果中显示该页面的确切时间和日期。
- Refresh – 这会在一定时间后将用户重定向到新的 URL。我们建议查看响应代码选项卡中的 meta refresh 数据。
- Outside
<head>– meta robots 位于 HTML 的 head 元素之外的页面。meta robots 应位于 head 元素内,否则搜索引擎可能会忽略它。即使在 head 元素之外,Google 通常仍然会识别 meta robots,例如“noindex”指令,但这不应依赖。
在此选项卡中,我们还显示 meta refresh 和 canonicals 的列。但是,我们建议查看响应代码选项卡和相关过滤器中的 meta refresh 数据,以及canonicals选项卡中的 canonicals。
hreflang
hreflang 选项卡包含由 SEO Spider 抓取的 hreflang 注释的详细信息,这些注释通过 HTML 链接元素、HTTP 标头或 XML Sitemap 传递。过滤器显示了 hreflang 的常见问题。
当您有多个针对不同语言或区域的页面版本时,Hreflang 非常有用。它会告诉 Google 这些不同的变体,并帮助他们按语言或区域显示您页面的最合适的版本。
Hreflang 链接元素应放置在文档的 head 中,并在 HTML 中如下所示:
<link rel="alternate" hreflang="en-gb" href="https://www.example.com" > <link rel="alternate" hreflang="en-us" href="https://www.example.com/us/" >
需要启用“Store Hreflang”和“Crawl Hreflang”选项(在“Config > Spider”下),才能填充此选项卡和相应的过滤器。要在常规抓取期间从 XML Sitemap 中提取 hreflang 注释,还必须选择“Crawl Linked XML Sitemaps”。
列
此选项卡包含以下列。
- Address – 抓取的 URL。
- Title 1/2 etc – 页面的页面标题元素。
- Occurrences – 在页面上发现的 hreflang 的数量。
- HTML hreflang 1/2 etc – 来自页面上任何 HTML 链接元素的 hreflang 语言和区域代码。
- HTML hreflang 1/2 URL etc – 来自页面上任何 HTML 链接元素的 hreflang URL。
- HTTP hreflang 1/2 etc – 来自 HTTP 标头的 hreflang 语言和区域代码。
- HTTP hreflang 1/2 URL etc – 来自 HTTP 标头的 hreflang URL。
- Sitemap hreflang 1/2 etc – 来自 XML Sitemap 的 hreflang 语言和区域代码。请注意,这仅在以列表模式抓取 XML Sitemap 时才会填充。
- Sitemap hreflang 1/2 URL etc – 来自 XML Sitemap 的 hreflang URL。请注意,这仅在以列表模式抓取 XML Sitemap 时才会填充。
过滤器
此选项卡包含以下过滤器。
- Contains Hreflang – 这些只是任何具有来自任何实现的 rel="alternate" hreflang 注释的 URL,无论是链接元素、HTTP 标头还是 XML Sitemap��。
- Non-200 Hreflang URLs – 这些是包含在 rel="alternate" hreflang 注释中的 URL,这些 URL 没有 200 响应代码,例如 robots.txt 阻止的 URL、无响应、3XX(重定向)、4XX(客户端错误)或 5XX(服务器错误)。Hreflang URL 必须可抓取和可索引,因此非 200 URL 被视为错误,并被搜索引擎忽略。可以在下部窗口“URL Info”窗格中看到带有“non-200”确认状态的非 200 hreflang URL。可以通过“Reports > Hreflang > Non-200 Hreflang URLs”导出批量导出它们。
- Unlinked Hreflang URLs – 这些是包含一个或多个 hreflang URL 的页面,这些 URL 只能通过其 rel="alternate" hreflang 链接注释发现。Hreflang 注释不会像传统的锚标记那样传递 PageRank,因此这可能表明内部链接存在问题,或者 hreflang 注释中包含的 URL 存在问题。要准确找出这些页面上的哪些 hreflang URL 未链接,请使用“Reports > Hreflang > Unlinked Hreflang URLs”导出。
- Missing Return Links – 这些是缺少来自其备用页面的返回链接(或 Google Search Console 中的“返回标记”)的 URL。Hreflang 是互惠的,因此所有备用版本都必须确认该关系。当页面 X 使用 hreflang 链接到页面 Y 以将其指定为备用页面时,页面 Y 必须具有返回链接。没有返回链接意味着 hreflang 注释可能会被忽略或无法正确解释。可以在下部窗口“URL Info”窗格中看到带有“missing”确认状态的缺少返�回链接的 URL。可以通过“Reports > Hreflang > Missing Return Links”导出批量导出它们。
- Inconsistent Language & Region Return Links – 此过滤器包括具有不一致的语言和区域返回链接的 URL。这是指返回链接具有与 URL 引用自身不同的语言或区域值。可以在下部窗口“URL Info”窗格中看到带有“Inconsistent”确认状态的不一致的语言返回 URL。可以通过“Reports > Hreflang > Inconsistent Language Return Links”导出批量导出它们。
- Non-Canonical Return Links – 具有非规范 hreflang 返回链接的 URL。Hreflang 应仅包含 URL 的规范版本。因此,此过滤器会拾取指向非规范版本的 URL 的返回链接。可以在下部窗口“URL Info”窗格中看到带有“Non Canonical”确认状态的非规范返回 URL。可以通过“Reports > Hreflang > Non Canonical Return Links”导出批量导出它们。
- Noindex Return Links – 具有“noindex”meta 标签的返回链接。集合中的所有页面都应该是可索引的,因此任何带有“noindex”的返回 URL 都可能导致 hreflang 关系被忽略。可以在下部窗口“URL Info”窗格中看到带有“noindex”确认状态的 noindex 返回链接的 URL。可以通过“Reports > Hreflang > Noindex Return Links”导出批量导出它们。
- Incorrect Language & Region Codes – 这只是验证语言(采用 ISO 639-1 格式)和可选区域(采用 ISO 3166-1 Alpha 2 格式)代码值是否有效。可以在下部窗口“URL Info”窗格中查看带有“invalid”状态的不受支持的 hreflang 值。
- Multiple Entries – 具有多个语言或区域代码条目的 URL。例如,如果页面 X 使用相同的“en”hreflang 值注释链接到页面 Y 和 Z。此过滤器还将拾取多个实现,例如,如果 hreflang 注释被发现为链接元素并通过 HTTP 标头发现。
- Missing Self Reference – 缺少其自身的自引用 rel="alternate" hreflang 注释的 URL。以前需要具有自引用 hreflang,但 Google 已更新其指南,称这是可选的。但是,包含自引用属性是一种很好的做法,而且通常更容易。
- Not Using Canonical – 未在其自身的 hreflang 注释中使用页面上的规范 URL 的 URL。Hreflang 应仅包含 URL 的规范版本。
- Missing X-Default – 缺少 X-Default hreflang 属性的 URL。这是可选的,不一定是错误或问题。
- Missing – 完全缺少 hreflang 属性的 URL。如果它们不是页面的多个版本,那么这些当然可能是有效的。
- Outside
<head>– 具有位于 HTML 的 head 元素之外的 hreflang 链接元素的页面。hreflang 链接元素应位于 head 元素内,否则搜索引擎将忽略它。
请注意 – SEO Spider 目前的 hreflang 注释限制为 500 个。如果超过此限制,则不会报告它们。超过 500 个 hreflang 注释是不寻常的,对于大多数设置来说可能属于极端情况。
有关 hreflang 的更多信息,请阅读我们的指南“ How to Audit Hreflang”。
JavaScript
JavaScript 选项卡包含与使用客户端 JavaScript 审核网站相关的常见问题的数据和过滤器。
此选项卡仅在 JavaScript 渲染模式下填充(“Configuration > Spider > Rendering tab > JavaScript”)。
在 JavaScript 渲染模式下,SEO Spider 将像在浏览器中一样渲染网页,并帮助识别 JavaScript 内容和链接以及其他依赖项。JavaScript 渲染模式仅在付费版本中可用。
列
此选项卡包含以下列。
- Address – URL 地址。
- Status Code – HTTP 响应代码。
- Status – HTTP 头部响应。
- HTML Word Count – 这是原始 HTML 的 body 标签内的所有“单词”,不包括 HTML 标记,在 JavaScript 执行之前。计数基于可以在“Config > Content > Area”下调整的内容区域。默认情况下,nav 和 footer 元素被排除在外。您可以包含或排除 HTML 元素、类和 ID,以计算更精确的字数。我们的数字可能与手动执行此计算的结果不完全相同,因为解析器会对无效 HTML 执行某些修复。您的渲染设置也会影响所考虑的 HTML。我们对单词的定义是获取文本并按空格分隔。不考虑内容的可见性(例如,div 设置为隐藏的文本)。
- Rendered HTML Word Count – 这是 JavaScript 执行后渲染的 HTML 的 body 标签内的所有“单词”,不包括 HTML 标记。计数基于可以在“Config > Content > Area”下调整的内容区域。默认情况下,nav 和 footer 元素被排除在外。您可以包含或排除 HTML 元素、类和 ID,以计算更精确的字数。我们的数字可能与手动执行此计算的结果不完全相同,因为解析器会对无效 HTML 执行某些修复。您的渲染设置也会影响所考虑的 HTML。我们对单词的定义是获取文本并按空格分隔。不考虑内容的可见性(例如,div 设置为隐藏的文本)。
- Word Count Change – 这是 HTML Word Count 和 Rendered HTML Word Count 之间的差异。本质上,有多少单词由于 JavaScript 而填充(或删除)。
- JS Word Count % – 这是由于 JavaScript 导致渲染的 HTML 中文本变化的比例。
- HTML Title – 在 JavaScript 执行之前,在原始 HTML 页面上发现的(第一个)页面标题。
- Rendered HTML Title – 在 JavaScript 执行后,在渲染的 HTML 页面上发现的(第一个)页面标题。
- HTML Meta Description – 在 JavaScript 执行之前,在原始 HTML 页面上发现的(第一个)meta description。
- Rendered HTML Meta Description- 在 JavaScript 执行后,在渲染的 HTML 页面上发现的(第一个)meta description。
- HTML H1 – 在 JavaScript 执行之前,在原始 HTML 页面上发现的(第一个)h1。
- Rendered HTML H1- 在 JavaScript 执行后,在渲染的 HTML 页面上发现的(第一个)h1。
- HTML Canonical – 在 JavaScript 执行之前,在原始 HTML 页面上发现的 canonical link 元素。
- Rendered HTML Canonical – 在 JavaScript 执行后,在渲染的 HTML 页面上发现的 canonical link 元素。
- HTML Meta Robots – 在 JavaScript 执行之前,在原始 HTML 页面上发现的 meta robots。
- Rendered HTML Meta Robots – 在 JavaScript 执行后,在渲染的 HTML 页面上发现的 meta robots。
- Unique Inlinks – 指向 URL 的“唯一”内部链接的数量。“内部链接”是指从正在抓取的同一子域中的锚元素指向给定 URL 的链接。例如,如果“页面 A”链接到“页面 B”3 次,这将计为 3 个内部链接和 1 个指向“页面 B”的唯一内部链接。
- Unique JS Inlinks – 仅在 JavaScript 执行后渲染的 HTML 中存在的指向 URL 的“唯一”内部链接的数量。“内部链接”是指从正在抓取的同一子域中的锚元素指向给定 URL 的链接。例如,如果“页面 A”链接到“页面 B”3 次,这将计为 3 个内部链接和 1 个指向“页面 B”的唯一内部链接。
- Unique Outlinks – 从 URL 发出的唯一内部外部链接的数量。“内部外部链接”是指从给定 URL 到正在抓取的同�一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,这将计为 3 个外部链接和 1 个指向“页面 B”的唯一外部链接。
- Unique JS Outlinks – 仅在 JavaScript 执行后渲染的 HTML 中存在的从 URL 发出的唯一内部外部链接的数量。“内部外部链接”是指从给定 URL 到正在抓取的同一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,这将计为 3 个外部链接和 1 个指向“页面 B”的唯一外部链接。
- Unique External Outlinks – 从 URL 发出的唯一外部外部链接的数量。“外部外部链接”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,这将计为 3 个外部外部链接和 1 个指向“页面 B”的唯一外部外部链接。
- Unique External JS Outlinks – 仅在 JavaScript 执行后渲染的 HTML 中存在的从 URL 发出的唯一外部外部链接的数量。“外部外部链接”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,这将计为 3 个外部外部链接和 1 个指向“页面 B”的唯一外部外部链接。
Filters
此选项卡包含以下过滤器。
- Pages with Blocked Resources – 具有被 robots.txt 阻止的资源(例如图像、JavaScript 和 CSS)的页面。这可能是一个问题,因为搜索引擎可能无法访问关键资源以准确地呈现页面。更新 robots.txt 以允许抓取所有关键资源并将其用于呈现网站内容。可以忽略非关键资源(例如 Google Maps 嵌入)。
- Contains JavaScript Links – 包含仅在 JavaScript 执行后在渲染的 HTML 中发现的超链接的页面。这些超链接不在原始 HTML 中。虽然 Google 能够呈现页面并查看仅客户端链接,但请考虑在原始 HTML 中的服务器端包含重要链接。
- Contains JavaScript Content – 包含仅在 JavaScript 执行后在渲染的 HTML 中发现的正文文本的页面。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- Noindex Only in Original HTML – 在原始 HTML 中包含 noindex,而在渲染的 HTML 中不包含 noindex 的页面。当 Googlebot 遇到 noindex 标签时,它会跳过渲染和 JavaScript 执行。由于 Googlebot 跳过 JavaScript 执行,因此使用 JavaScript 删除渲染的 HTML 中的“noindex”将不起作用。仔细检查原始 HTML 中包含 noindex 的页面是否预计不会被索引。如果页面应该被索引,请删除“noindex”。
- Nofollow Only in Original HTML – 在原始 HTML 中包含 nofollow,而在渲染的 HTML 中不包含 nofollow 的页面。这意味着在 JavaScript 执行之前,原始 HTML 中的任何超链接都不会��被跟踪。仔细检查原始 HTML 中包含 nofollow 的页面是否预计不会被跟踪。如果链接应该被跟踪、抓取和索引,请删除“nofollow”。
- Canonical Only in Rendered HTML – 仅在 JavaScript 执行后在渲染的 HTML 中包含 canonical 的页面。Google 可以处理渲染的 HTML 中的 canonical,但是他们不建议依赖 JavaScript,而更喜欢在原始 HTML 中更早地使用它们。渲染问题、冲突或多个 rel=”canonical” 链接标签可能会导致意外结果。在原始 HTML(或 HTTP 标头)中包含 canonical 链接,以确保 Google 可以看到它,并避免仅依赖渲染的 HTML 中的 canonical。
- Canonical Mismatch – 在原始 HTML 中包含与 JavaScript 执行后渲染的 HTML 中不同的 canonical 链接的页面。Google 可以在 JavaScript 处理后处理渲染的 HTML 中的 canonical,但是冲突的 rel=”canonical” 链接标签可能会导致意外结果。确保正确的 canonical 在原始 HTML 和渲染的 HTML 中,以避免向搜索引擎发出冲突的信号。
- Page Title Only in Rendered HTML – 仅在 JavaScript 执行后在渲染的 HTML 中包含页面标题的页面。这意味着搜索引擎必须呈现页面才能看到它。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- Page Title Updated by JavaScript – 具有由 JavaScript 修改的页面标题的页面。这意味着原始 HTML 中的页面标题与渲染的 HTML 中的页面标题不同。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- Meta Description Only in Rendered HTML – 仅在 JavaScript 执行后在渲染的 HTML 中包含 meta description 的页面。这意味着搜索引擎必须呈现页面才能看到它。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- Meta Description Updated by JavaScript – 具有由 JavaScript 修改的 meta description 的页面。这意味着原始 HTML 中的 meta description 与渲染的 HTML 中的 meta description 不同。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- H1 Only in Rendered HTML – 仅在 JavaScript 执行后在渲染的 HTML 中包含 h1 的页面。这意味着搜索引擎必须呈现页面才能看到它。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- H1 Updated by JavaScript – 具有由 JavaScript 修改的 h1 的页面。这意�味着原始 HTML 中的 h1 与渲染的 HTML 中的 h1 不同。虽然 Google 能够呈现页面并查看仅客户端内容,但请考虑在原始 HTML 中的服务器端包含重要内容。
- Uses Old AJAX Crawling Scheme URLs – 仍然使用旧的 AJAX 抓取方案(包含 #! 哈希片段的 URL)的 URL,该方案已于 2015 年 10 月正式弃用。更新 URL 以遵循当今 Web 上的 JavaScript 最佳实践。尽可能考虑服务器端渲染或预渲染,并将动态渲染作为一种变通解决方案。
- Uses Old AJAX Crawling Scheme Meta Fragment Tag – URL 包含一个 meta fragment 标签,表明该页面仍在使用旧的 AJAX 抓取方案,该方案已于 2015 年 10 月正式弃用。更新 URL 以遵循当今 Web 上的 JavaScript 最佳实践。尽可能考虑服务器端渲染或预渲染,并将动态渲染作为一种变通解决方案。如果站点仍然错误地包含旧的 meta fragment 标签,则应将其删除。
- Pages with JavaScript Errors – 在页面渲染期间,在 Chrome DevTools 控制台日志中捕获到 JavaScript 错误的页面。虽然 JavaScript 错误很常见,并且通常对页面渲染影响很小,但它们可能会有问题——无论是在搜索引擎渲染中(这��会阻碍索引),还是在用户与页面交互时。在下方的“Chrome Console Log”选项卡中查看控制台错误消息,在“Rendered Page”选项卡中查看页面的渲染方式,并通过“Bulk Export > JavaScript > Pages With JavaScript Issues”批量导出。
有关 JavaScript SEO 的更多信息,请阅读我们的指南“如何抓取 JavaScript 网站”。
Links
“链接”选项卡包含有关抓取中发现的与链接相关的常见问题的数据和过滤器,例如具有高抓取深度的页面、没有任何内部外部链接的页面、在内部链接上使用 nofollow 的页面等等。
Columns
此选项卡包含以下列。
- 地址 – URL 地址。
- 索引性 – URL 是否可索引或不可索引。
- 索引性状态 – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- 抓取深度 – 页面从起始页面的深度(距离起始页面的“点击”次数)。请注意,目前在我们的页面深度计算中,重定向被算作一个层级。
- 链接评分 – 一个介于 0-100 之间的指标,它根据页面的内部链接计算页面的相对价值,类似于 Google 自己的 PageRank。要填充此列,需要进行“抓取分析”。
- 唯一内链 – 指向 URL 的“唯一”内部反向链接的数量。“内部反向链接”是指从正在抓取的同一子域指向给定 URL 的锚元素中的链接。例如,如果“页面 A”链接到“页面 B”3 次,则这将计为 3 个反向链接和 1 个指向“页面 B”的唯一反向链接。
- 唯一 JS 内链 – 仅在 JavaScript 执行后呈现的 HTML 中存在的指向 URL 的“唯一”内部反向链接的数量。“内部反向链接”是指从正在抓取的同一子域指向给定 URL 的锚元素中的链接。例如,如果“页面 A”链接到“页面 B”3 次,则这将计为 3 个反向链接和 1 个指向“页面 B”的唯一反向链接。
- 总百分比 – 指向 URL 的唯一内部反向链接(200 响应 HTML 页面)的百分比。“内部反向链接”是指从正在抓取的同一子域指向给定 URI 的锚元素中的链接。
- 外链 – 来自 URL 的内部外链的数量。“内部外链”是指从给定 URL 到正在抓取的同一子域上的其他 URL 的锚元素中的链接。
- 唯一外链 – 来自 URL 的唯一内部外链的数量。“内部外链”是指从给定 URL 到正在抓取的同一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,则这将计为 3 个外链和 1 个指向“页面 B”的唯一外链。
- 唯一 JS 外链 – 仅在 JavaScript 执行后呈现的 HTML 中存在的来自 URL 的唯一内部外链的数量。“内部外链”是指从给定 URL 到正在抓取的同一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,则这将计为 3 个外链和 1 个指向“页面 B”的唯一外链。
- 外部外链 – 来自 URL 的外部外链的数量。“外部外链”是指从给定 URL 到另一个子域的锚元素中的链接。
- 唯一外部外链 – �来自 URL 的唯一外部外链的数量。“外部外链”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,则这将计为 3 个外部外链和 1 个指向“页面 B”的唯一外部外链。
- 唯一外部 JS 外链 – 仅在 JavaScript 执行后呈现的 HTML 中存在的来自 URL 的唯一外部外链的数量。“外部外链”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,则这将计为 3 个外部外链和 1 个指向“页面 B”的唯一外部外链。
过滤器
此选项卡包含以下过滤器。
- 具有高抓取深度的页面 – 基于“配置 > 爬虫 > 首选项”下的“抓取深度”首选项,从爬网的起始页面具有高抓取深度的页面。 广义上讲,直接从热门页面(例如主页)链接的页面会传递更多的 PageRank,这可以帮助它们在自然搜索中表现更好。 网站中更深层的页面通常会传递较少的 PageRank,因此可能表现不佳。 这对于针对更广泛、更具竞争力的查询的关键页面非常重要,这些页面可能会受益于改进的链接和减少的抓取深度。 不重要的页面、针对竞争较少的查询的页面或大型网站上的页面通常会自然地位于更深的位置而没有问题。 最重要的是,考虑用户,哪些页面对于他们导航到哪里很重要,以及他们到达页面的旅程。
- 没有内部外链的页面 – 不包含指向其他内部页面的链接的页面。 这可能意味着没有指向其他页面的链接。 但是,这也通常是由于使用了 JavaScript,其中链接不存在于原始 HTML 中,而仅存在于 JavaScript 处理后呈现的 HTML 中。 启用 JavaScript 呈现模式(“配置 > 爬虫 > 呈现”)以抓取仅在客户端呈现的 HTML 中具有链接的页面。 如果没有使用带有 href 属性的锚标记链接到其他内部页面的链接,搜索引擎和 SEO Spider 将难以发现和索引它们。
- 内部 Nofollow 外链 – 在内部外链上使用 rel=”nofollow” 的页面。 带有 nofollow 链接属性的链接通常不会被搜索引擎跟踪。 请记住,链接的页面可以通过其他方式找到,例如其他跟踪的链接或 XML 站点地图等。 带有 nofollow 链接属性的链接可以在“外链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“跟踪”列为“假”。 通过“批量导出 > 链接 > 内部 Nofollow 外链”批量导出。
- 没有锚文本的内部外链 – 具有没有锚文本的内部链接或没有 alt 文本的超链接图像的页面。 锚文本是超链接中使用的可见文本和单词,可为用户和搜索引擎提供有关目标页面内容的上下文。 没有锚文本的内部外链可以在“外链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“锚文本”列为空,或者如果是图像,则“Alt 文本”列也为空。 通过“批量导出 > 链接 > �没有锚文本的内部外链”批量导出。
- 内部外链中非描述性锚文本 – 具有带有非描述性锚文本的内部外链的页面,例如基于“配置 > 爬虫 > 首选项”下的首选项的“单击此处”或“了解更多”。 锚文本是超链接中使用的可见文本和单词,可为用户和搜索引擎提供有关目标页面内容的上下文。 带有非描述性锚文本的内部外链可以在“外链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“锚文本”列包含诸如“单击此处”或“了解更多”之类的词。 通过“批量导出 > 链接 > 内部外链中非描述性锚文本”批量导出。
- 具有高外部外链的页面 – 基于“配置 > 爬虫 > 首选项”下的“高外部外链”首选项,具有大量跟踪的外部外链的页面。 外部外链是指向另一个子域或域的超链接(取决于您的配置)。 这可能是完全有效的,例如链接到同一根域的另一部分,或链接到其他有用的网站。 跟踪的外部外链可以在“外链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“跟踪”列为“真”。
- 具有高内部外链的页面 – 基于“配置 > 爬虫 > 首选项”下的“高内部外链”首选项,具有大量跟踪的内部外链的页面。 内部外链是指向同一子域或域的超链接(取决于您的配置)。 链接供用户用于浏览网站,而搜索引擎使用它们来发现和对页面进行排名。 过多的链接会降低可用性,并减少分配给每个页面的 PageRank 量。 跟踪的内部外链可以在“外链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“跟踪”列为“真”。
- 指向页面的跟踪和 Nofollow 内部内链 – 具有来自其他页面的 rel=”nofollow” 和跟踪链接的页面。 带有 nofollow 链接属性的链接通常不会被搜索引擎跟踪。 没有 nofollow 链接属性的链接通常会被跟踪。 因此,不一致地使用跟踪和 nofollow 链接可能是一个问题或错误的迹象,或者可以忽略的事情。 Nofollow 和跟踪内链可以在“内链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“跟踪”列为“真”和“假”。 通过“批量导出 > 链接 > 指向页面的跟踪和 Nofollow 内部内链”批量导出。
- 仅内部 Nofollow 内链 – 仅具有来自其他页面的 rel=”nofollow” 链接的页面。 带有 nofollow 链接属性的链接通常不会被搜索引擎跟踪,因此这会影响页面的发现和索引。 Nofollow 内链可以在“内链”选项卡中看到,其中“所有链接类型”过滤器设置为“超链接”,其中“跟踪”列为“真”和“假”。 通过“批量导出 > 链接 > 仅内部 Nofollow 内链”批量导出。
- 指向 Localhost 的外链 – 包含引用 localhost �或 127.0.0.1 环回地址的链接的页面。 Localhost 是本地计算机的地址,在开发中用于在浏览器中查看站点而无需连接到互联网。 这些链接不适用于实时网站上的用户。 这些链接可以在“外链”选项卡中看到,其中“到”地址包含“localhost”或 127.0.0.1 环回地址。 通过“批量导出 > 链接 > 指向 Localhost 的外链”批量导出。
- 仅非索引页面内链 – 仅从非索引页面链接的可索引页面,其中包括 noindex、规范化或 robots.txt 禁止的页面。 具有 noindex 的页面以及来自它们的链接最初将被抓取,但 noindex 页面将从索引中删除,并且随着时间的推移抓取次数会减少。 来自这些页面的链接也可能被抓取得更少,并且 Google 员工一直在争论链接是否会继续被计算在内。 来自规范化页面的链接最初可以被抓取,但如果索引和链接信号传递到规范中指示的另一个页面,则 PageRank 可能不会按预期流动。 这可能会影响发现和排名。 Robots.txt 页面无法抓取,因此看不到来自这些页面的链接。
AMP
“AMP”选项卡包含在抓取期间发现的加速移动页面 (AMP)。 这些通过 HTML AMP 标签和 rel=”amphtml” 内链识别。 该选项卡包含使用 AMP 验证器的常见 SEO 问题和验证错误的过滤器。
需要启用“存储”和“抓取”AMP 选项(在“配置 > 爬虫”下)才能填充此选项卡和相应的过滤器。
列
此选项卡包含以下列。
- 地址 – 抓取的 URL。
- 出现次数 – 找到的规范数量(通过链接元素和 HTTP)。
- 索引性 – URL 是否可索引或不可索引。
- 索引性状态 – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- 标题 1 – (第一个)页面标题。
- 标题 1 长度 – 页面标题的字符长度。
- 标题 1 像素宽度 – 页面标题的像素宽度。
- h1 – 1 – 页面上的第一个 h1(标题)。
- h1 – Len-1 – h1 的字符长度。
- 大小 – 大小以字节为单位,除以 1024 转换为千字节。 该值从 Content-Length 标头设置(如果提供),否则设置为零。 对于 HTML 页面,此值会更新为(未压缩)HTML 的大小(以字节为单位)。
- 字数 – 这是 body 标签内的所有“单词”。 这不包括 HTML 标记。 我们的数字可能与手动执行此操作找到的数字不完全相同,因为解析器会对无效的 html 执行某些修复。 您的渲染设置也会影响所考虑的 HTML。 我们对单词的定义是获取文本并按空格分隔。 不考虑内容的可见性(例如,设置为隐藏的 div 中的文本)。
- 文本比率 – 在页面上的 HTML body 标签中找到的非 HTML 字符数(文本),除以 HTML 页面组成的字符总数,并以百分比形式显示。
- 抓取深度 – 页面从起始页面的深度(�距离起始页面的“点击”次数)。请注意,目前在我们的页面深度计算中,重定向被算作一个层级。
- 响应时间 – 下载 URI 的时间(以秒为单位)。 更多详细信息可以在我们的 FAQ 中找到。
SEO 相关过滤器
此选项卡包含以下 SEO 相关过滤器。
- 非 200 响应 – AMP URL 没有返回 200 ‘OK’ 状态码。这些包括被 robots.txt 阻止的 URL、无响应、重定向、客户端和服务器错误。
- 缺少非 AMP 返回链接 – URL 的规范非 AMP 版本不包含返回到 AMP URL 的 rel=”amphtml” URL。这可能只是在非 AMP 版本中缺失,或者 AMP 规范可能存在配置问题。
- 缺少到非 AMP 的规范链接 – AMP URL 的规范链接没有指向非 AMP 版本,而是指向另一个 AMP URL。
- 不可索引的规范链接 – AMP 规范 URL 是一个不可索引的页面。通常,桌面版本应该是可索引的页面。
- 可索引 – AMP URL 是可索引的。具有桌面版本的 AMP URL 应该是不可索引的(因为它们应该具有指向桌面版本的规范链接)。独立的 AMP URL(没有对应版本)应该是可索引的。
- 不可索引 – AMP URL 是不可索引的。这通常是因为它们已正确规范化到桌面版本。
以下过滤器有助于识别与 AMP 规范 相关的常见问题。SEO Spider 使用官方 AMP 验证器来验证 AMP URL。
AMP 相关过滤器
此选项卡包括以下 AMP 特定过滤器。
- 缺少 HTML AMP 标签 – AMP HTML 文档必须包含顶级 HTML 或 HTML AMP 标签。
- 缺少/无效的 Doctype HTML 标签 – AMP HTML 文档必须以 doctype 开头,即 doctype HTML。
- 缺少 Head 标签 – AMP HTML 文档必须包含 head 标签(在 HTML 中是可选的)。
- 缺少 Body 标签 – AMP HTML 文档必须包含 body 标签(在 HTML 中是可选的)。
- 缺少规范链接 – AMP URL 必须在其 head 中包含一个规范标签,该标签指向 AMP HTML 文档的常规 HTML 版本,如果不存在这样的 HTML 版本,则指向自身。
- 缺少/无效的 Meta Charset 标签 – AMP HTML 文档必须包含一个 meta charset=”utf-8″ 标签,作为其 head 标签的第一个子标签。
- 缺少/无效的 Meta Viewport 标签 – AMP HTML 文档必须在其 head 标签中包含一个 meta name=”viewport” content=”width=device-width,minimum-scale=1″ 标签。还建议包含 initial-scale=1。
- 缺少/无效的 AMP 脚本 – AMP HTML 文档必须在其 head 标签中包含一个 script async src=”https://cdn.ampproject.org/v0.js” 标签。
- 缺少/无效的 AMP Boilerplate – AMP HTML 文档必须在其 head 标签中包含 AMP boilerplate 代码。
- 包含不允许的 HTML – 此标志标记任何包含 AMP 不允许的 HTML 的 AMP URL。
- 其他验证错误 – 此标志标记任何具有上述过滤器未涵盖的其他验证错误的 AMP URL。
有关 AMP 的更多信息,请阅读我们的指南“如何审核和验证 AMP”。
结构化数据
“结构化数据”选项卡包含从抓取中发现的结构化数据和验证问题的详细信息。
需要启用“JSON-LD”、“Microdata”、“RDFa”、“Schema.org 验证”和“Google 富媒体搜索结果功能验证”配置选项(在“配置 > Spider > 提取”下),才能完全填充此选项卡和相应的过滤器。
列
此选项卡包括以下列。
- 地址 – 抓取的 URL。
- 错误 – 为 URL 发现的验证错误总数。
- 警告 – 为 URL 发现的验证警告总数。
- 类型总数 – 为 URL 发现的 itemtype 总数。
- 唯一类型 – 为 URL 发现的唯一 itemtype 数。
- 类型 1 – 为 URL 发现的第一个 itemtype。
- 类型 2 等 – 为 URL 发现的第二个 itemtype。
过滤器
此选项卡包括以下过滤器。
- 包含结构化数据 – 这些只是包含结构化数据的任何 URL。您可以在上部窗口的列中查看不同的类型。
- 缺少结构化数据 – 这些是不包含任何结构化数据的 URL。
- 验证错误 – 这些是包含验证错误的 URL。这些错误可以是 Schema.org、Google 富媒体搜索结果功能,或两者兼而有之 – 具体取决于您的配置。Schema.org 问题将始终被归类为错误,而不是警告。Google 富媒体搜索结果功能验证将显示缺少必需属性或必需属性的实现存在问题的错误。必须包含 Google 的“必需属性”并且对于内容有效,才有资格显示为富媒体搜索结果。
- 验证警告 – 这些是包含 Google 富媒体搜索结果功能的验证警告的 URL。这些将始终是“推荐属性”,而不是必需属性。可以包含推荐属性以添加有关内容的更多信息,这可以提供更好的用户体验 – 但它们对于有资格获得富媒体摘要不是必不可少的,因此它们只是一个警告。Schema.org 验证问题没有“警告”,但是使用较旧的 data-vocabulary.org 模式会发出警告。
- 解析错误 – 这些是结构化数据未能正确解析的 URL。这通常是由于不正确的标记造成的。如果您使用的是 Google 首选的 JSON-LD 格式,那么 JSON-LD Playground 是一个出色的工具,可以帮助调试解析错误。
- Microdata URLs – 这些是包含 microdata 格式的结构化数据的 URL。
- JSON-LD URLs – 这些是包含 JSON-LD 格式的结构化数据的 URL。
- RDFa URLs – 这些是包含 RDFa 格式的结构化数据的 URL。
结构化数据和 Google 富媒体摘要功能验证
结构化数据验证包括根据 Schema.org 检查类型和属性是否存在,并将显示遇到的任何问题的“错误”。
例如,它会检查属性是否存在 https://schema.org/author,或者 https://schema.org/Book 是否作为类型存在。它根据 Schema.org 最新版本 中的主要和待处理的 Schema 词汇表 进行验证。
Schema.org 词汇表发布与在 SEO Spider 中更新之间可能存在短暂的时间间隔。
SEO Spider 还针对 Google 富媒体搜索结果功能 执行验证,以检查必需和推荐属性的�存在,以及它们的值是否准确。
SEO Spider 能够验证的完整列表包括 –
- 文章 和 AMP 文章
- 图书操作
- 面包屑
- 轮播
- 课程列表
- COVID-19 公告
- 数据集
- 雇主综合评分
- 预计薪资
- 活动
- 事实核查
- 常见问题解答
- 家庭活动
- 图像元数据
- 职位发布
- 学习视频
- 本地商家
- 徽标
- 数学求解器
- 电影轮播
- 练习题
- 产品
- 问答
- 食谱
- 评价摘要
- 站点链接搜索框
- 软件应用
- 可读
- 订阅和付费内容
- 车辆列表
- 视频
SEO Spider 当前无法验证的 Google 富媒体搜索结果功能列表是 –
- 我们目前支持所有 Google 功能。
有关结构化数据验证的更多信息,请阅读我们的指南“如何测试和验证结构化数据”。
站点地图
“站点地图”选项卡显示在抓取中发现的所有 URL,然后可以对其进行过滤以显示与 XML 站点地图相关的其他信息。
要在常规抓取中抓取 XML 站点地图并填充过滤器,需要启用“抓取链接的 XML 站点地图”配置(在“配置 > Spider”下)。
还需要在抓取结束时执行“抓取分析”,以填充某些过滤器。
列
此选项卡包括以下列。
- 地址 – 抓取的 URL。
- 内容类型 – URL 的内容类型。
- 状态代码 – HTTP 响应代码。
- 状态 – HTTP 标头响应。
- 可索引性 – URL 是否可索引或不可索引。
- 可索引性状态 – URL 不可索引的原因。例如,如果它已规范化到另一个 URL。
过滤器
此选项卡包括以下过滤器。
- 站点地图中的 URL – XML 站点地图中的所有 URL。这应包含重要 URL 的可索引和规范版本。
- 站点地图中没有的 URL – 不在 XML 站点地图中,但在抓取中发现的 URL。这可能是故意的(因为它们不重要),或者它们可能缺失,并且需要更新 XML 站点地图以包含它们。此过滤器不考虑不可索引的 URL,它假定它们是正确地不可索引的,因此不应标记为包含。
- 孤立 URL – 仅在 XML 站点地图中,但在抓取期间未发现的 URL。或者,仅从 XML 站点地图中的 URL 发现,但在抓取中未找到的 URL。这些可能被意外地包含在 XML 站点地图中,或者它们可能是您希望被索引的页面,并且实际上应该在内部链接到。
- 站点地图中不可��索引的 URL – 在 XML 站点地图中,但不可索引的 URL,因此应删除它们,或者需要修复它们的可索引性。
- 多个站点地图中的 URL – 在多个 XML 站点地图中的 URL。这不一定是问题,但通常一个 URL 只需要在一个 XML 站点地图中。
- 超过 5 万个 URL 的 XML 站点地图 – 这显示了任何具有超过允许的 5 万个 URL 的 XML 站点地图。如果您有更多 URL,则必须将列表分成多个站点地图,并创建一个站点地图索引文件来列出所有站点地图。
- 超过 50mb 的 XML 站点地图 – 这显示了任何大于允许的 50mb 文件大小的 XML 站点地图。如果站点地图超过 50MB(未压缩)限制,则必须将列表分成多个站点地图。
有关 XML 站点地图的更多信息,请阅读我们的指南“如何审核 XML 站点地图”,以及 Sitemaps.org 和 Google Search Console help。
PageSpeed
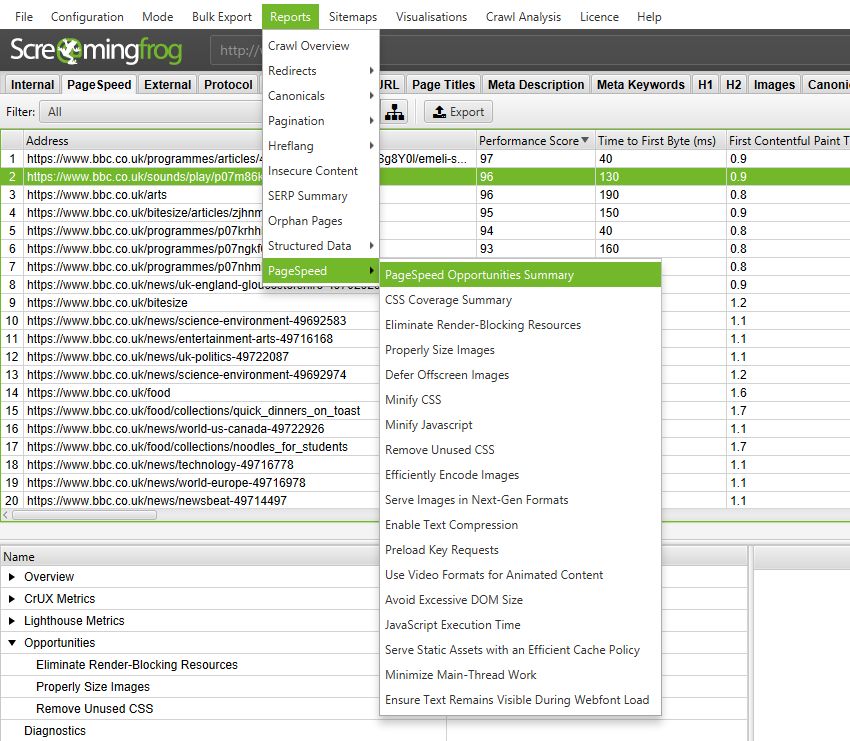
“PageSpeed”选项卡包含来自 PageSpeed Insights 的数据,该数据使用 Lighthouse 进行“实验室数据”速度审核,并且能够从 Chrome User Experience Report(CrUX,或“现场数据”)中查找真实数据。
要提取 PageSpeed 数据,只需转到“Configuration > API Access > PageSpeed Insights”,插入一个免费的 PageSpeed API key,连接并运行爬网。 然后,数据将开始针对已爬取的 URL 进行填充。
请阅读我们的 PageSpeed Insights integration guide,了解如何设置免费 API 并配置 SEO Spider。
列 & 指标
以下速度指标、机会和诊断数据可以配置为通过 PageSpeed Insights API 集成来收集。
概览指标
- 总大小节省
- 总时间节省
- 总请求数
- 页面总大小
- HTML 大小
- HTML 计数
- 图像大小
- 图像计数
- CSS 大小
- CSS 计数
- JavaScript 大小
- JavaScript 计数
- 字体大小
- 字体计数
- 媒体大小
- 媒体计数
- 其他大小
- 其他计数
- 第三方大小
- 第三方计数
CrUX 指标(PageSpeed Insights 中的“现场数据”)
- 核心网页指标评估
- CrUX 首次内容绘制时间(秒)
- CrUX 首次内容绘制类别
- CrUX 首次输入延迟时间(秒)
- CrUX 首次输入延迟类别
- CrUX 最大内容绘制时间(秒)
- CrUX 最大内容绘制类别
- CrUX 累积布局偏移
- CrUX 累积布局偏移类别
- CrUX 与下一次绘制的交互(毫秒)
- CrUX 与下一次绘制的交互类别
- CrUX 首字节时间(毫秒)
- CrUX 首字节时间类别
- CrUX 来源核心网页指标评估
- CrUX 来源首次内容绘制时间(秒)
- CrUX 来源首次内容绘制类别
- CrUX 来源首次输入延迟时间(秒)
- CrUX 来源首次输入延迟类别
- CrUX 来源最大内容绘制时间(秒)
- CrUX 来源最大内容绘制类别
- CrUX 来源累积布局偏移
- CrUX 来源累积布局偏移类别
- CrUX 来源与下一次绘制的交互(毫秒)
- CrUX 来源与下一次绘制的交互类别
- CrUX 来源首字节时间(毫秒)
- CrUX 来源首字节时间类别
Lighthouse 指标(PageSpeed Insights 中的“实验室数据”)
- 性能得分
- 首字节时间(毫秒)
- 首次内容绘制时间(秒)
- 首次内容绘制得分
- 速度指数时间(秒)
- 速度指数得分
- 最大内容绘制时间(秒)
- 最大内容绘制得分
- 可交互时间(秒)
- 可交互得分
- 首次有效绘制时间(秒)
- 首次有效绘制得分
- 最大潜在首次输入延迟(毫秒)
- 最大潜在首次输入延迟得分
- 总阻塞时间(毫秒)
- 总阻塞时间得分
- 累积布局偏移
- 累积布局偏移得分
机会
- 消除渲染阻塞资源节省(毫秒)
- 延迟屏幕外图像节省(毫秒)
- 延迟屏幕外图像节省
- 有效编码图像节省(毫秒)
- 有效编码图像节省
- 正确调整图像大小节省(毫秒)
- 正确调整图像大小节省
- 缩小 CSS 节省(毫秒)
- 缩小 CSS 节省
- 缩小 JavaScript 节省(毫秒)
- 缩小 JavaScript 节省
- 减少未使用的 CSS 节省(毫秒)
- 减少未使用的 CSS 节省
- 减少未使用的 JavaScript 节省(毫秒)
- 减少未使用的 JavaScript 节省
- 以下一代格式提供图像节省(毫秒)
- 以下一代格式提供图像节省
- 启用文本压缩节省(毫秒)
- 启用文本压缩节省
- 预连接到所需来源节省
- 服务器响应时间 (TTFB)(毫秒)
- 服务器响应时间 (TTFB) 类别(毫秒)
- 多个重定向节省(毫秒��)
- 预加载关键请求节省(毫秒)
- 将视频格式用于动画图像节省(毫秒)
- 将视频格式用于动画图像节省
- 图像总优化节省(毫秒)
- 避免向现代浏览器提供旧版 JavaScript 节省
诊断
- DOM 元素计数
- JavaScript 执行时间(秒)
- JavaScript 执行时间类别
- 有效的缓存策略节省
- 最小化主线程工作(秒)
- 最小化主线程工作类别
- 文本在 Webfont 加载期间保持可见
- 图像元素没有明确的宽度和高度
- 避免大型布局偏移
您可以根据 Lighthouse 阅读有关每个指标、机会或诊断定义的更多信息。
过滤器
此选项卡包括以下过滤器。
- 消除渲染阻塞资源 – 这会突出显示所有页面,这些页面具有阻止页面首次绘制的资源,以及潜在的节省。
- 正确调整图像大小 – 这会突出显示所有图像大小不正确的页面,以及在适当调整大小时的潜在节省。
- 延迟屏幕外图像 – 这会突出显示所有具有隐藏或屏幕外图像的页面,以及如果它们被延迟加载的潜在节省。
- 缩小 CSS – 这会突出显示所有具有未缩小 CSS 文件的页面,以及在正确缩小时的潜在节省。
- 缩小 JavaScript – 这会突出显示所有具有未缩小 JavaScript 文件的页面,以及在正确缩小时的潜在节省。
- 减少未使用的 CSS – 这会突出显示所有具有未使用 CSS 的页面,以及在删除不必要字节时的潜在节省。
- 减少未使用的 JavaScript – 这会突出显示所有具有未使用 JavaScript 的页面,以及在删除不必要字节时的潜在节省。
- 有效编码图像 – 这会突出显示所有具有未优化图像的页面,以及潜在的节省。
- 以下一代格式提供图像 – 这会突出显示所有具有旧图像格式的页面,以及潜在的节省。
- 启用文本压缩 – 这会突出显示所有具有未压缩的基于文本的资源的页面,以及潜在的节省。
- 预连接到所需来源 – 这会突出显示所有具有尚未优先考虑使用 link rel=preconnect 获取请求的关键请求的页面,以及潜在的节省。
- 减少服务器响应时间 (TTFB) – 这会突出显示所有浏览器必须等待超过 600 毫秒才能让服务器响应主文档请求的页面。
- 避免多个页面重定向 – 这会突出显示所有具有重定向资源的页面,以及通过使用直接 URL 实现的潜在节省。
- 预加载关键请求 – 这会突出显示所有具有关键请求链中第三级请求作为预加载候选者的页面。
- 将视频格式用于动画图像 – 这会突出显示所有具有动画 GIF 的页面,以及将它们转换为视频的潜在节省。
- 避免过度 DOM 大小 – 这会突出显示所有 DOM 大小超过建议的 1,500 个总节点的页面。
- 减少 JavaScript 执行时间 – 这会突出显示所有具有平均或缓慢 JavaScript 执行时间的页面。
- 使用有效的缓存策略提供静态资源 – 这会突出显示所有具有未缓存资源的页面,以及潜在的节省。
- 最小化主线程工作 – 这会突出显示所有在主线程上具有平均或缓慢执行时间的页面。
- 确保文本在 Webfont 加载期间保持可见 – 这会突出显示所有在页面加载期间可能闪烁或变得不可见的字体。
- 图像元素没有明确的宽度和高度 – 这会突出显示所有在 HTML 中未指定尺寸(宽度和高度大小属性)的图像的页面。 这可能是导致 CLS 不良的一个重要原因。
- 避免大型布局偏移 – 这会突出显示所有具有对页面 CLS 贡献最大的 DOM 元素的页面,并提供每个元素的贡献分数以帮助确定优先级。
- 避免向现代浏览器提供旧版 JavaScript – 这会突出显示所有具有旧版 JavaScript 的页面。 Polyfill 和转换使旧版浏览器可以使用新的 JavaScript 功能。 但是,许多对于现代浏览器来说是不必要的。 对于您捆绑的 JavaScript,采用使用模块/nomodule 功能检测的现代脚本部署策略,以减少运送到现代浏览器的代码量,同时保留对旧版浏览器的支持。
请阅读 Lighthouse 性能审核指南,以获取上述每个机会和诊断的更多定义和说明。
具有潜在节省的速度机会、源页面和资源 URL 可以通过“Reports > PageSpeed”菜单批量导出。
“CSS 覆盖率摘要”报告突出显示了每次爬网中每个 CSS 文件有多少未使用,以及通过删除在整个站点上加载的未使用代码可以实现的潜在节省。
“JavaScript 覆盖率摘要”报告突出显示了每次爬网中每个 JS 文件有多少未使用,以及通过删除在整个站点上加载的未使用代码可以实现的潜在节省。
PageSpeed Insights API 状态 & 错误
“PSI 状态”列显示 URL 的 API 请求是否“成功”并显示数据,或者是否存在错误且未显示数据。“错误”通常反映 Web 界面,您将在其中看到相同的错误和消息。
“PSI 错误”列显示从 PSI API 收到的完整消息,以提供有关原因的更多信息。 一些错误是由于 Lighthouse 审核本身失败,其他错误可能是由于在发出请求时 PSI API 不可用。
请阅读我们的常见问题解答,了解有关 PageSpeed Insights API 错误 的更多信息。
移动设备
“移动设备”选项卡包含来自 Lighthouse 的数据,该数据通过 PageSpeed Insights API 或在本地运行 Lighthouse 获得。
要审核移动设备可用性问题,则必须通过“Configuration > API Access > PageSpeed Insights”连接 PSI,并在“Metrics”选项卡下选择“Mobile Friendly”指标。
“Source”可以设置为“Remote”或“Local”。 Remote 表示数据是通过 PageSpeed Insights API 收集的,这需要一个免费的 PageSpeed API key。 如果选择“Local”,则 Lighthouse 将在无头 Chrome 中在本地计算机上运行。
无论选择哪个选项并连接 PSI,数据都将开始针对已爬取的 URL 进行填充。
列
此选项卡包括以下列。
- 地址 – 已爬取的 URL。
- PSI 状态 – “成功”检索数据或“错误”。
- PSI 错误 – 如果有错误,则显示错误响应。
- 视口 – 此审核的 Lighthouse 性能得分(满分 100 分)。
- 点击目标 – 此审核的 Lighthouse 性能得分(满分 100 分)。
- 内容宽度 – 此审核的 Lighthouse 性能得分(满分 100 分)。
- 字体显示 – 此审核的 Lighthouse 性能得分(满分 100 分)。
- 插件 – 此审核的 Lighthouse 性能得分(满分 100 分)。
- 移动设备备用链接 – 包含指向移动设备版本的 rel=”alternate” 链接元素的任何桌面 URL。
过滤器
此选项卡包括以下过滤器。
- 未设置视口 – 页面缺少视口 meta 标签,或者视口 meta 标签缺少包含文本
width=的 content 属性。设置视口 meta 标签可以使宽度和缩放比例在所有设备上正确调整。如果没有设置,移动设备将以桌面屏幕宽度渲染页面并缩小,导致文本难以阅读。 - 目标尺寸 – 页面上的点击目标太小或周围空间不足,导致在移动设备上难以交互。点击目标(也称为“触摸目标”)是触摸设备用户可以使用的按钮、链接或表单元素。尺寸或间距不足也会给行动不便的用户或任何难以控制精细动作的用户带来挑战。点击目标必须至少为 24 x 24 CSS 像素大小。
- 内容尺寸不正确 – 页面上的内容小于或大于视口宽度,这意味着它可能无法在移动设备上正确渲染。Lighthouse 会标记宽度与视口宽度不相等的页面。这仅在“本地”Lighthouse 中可用,��由于已被弃用,因此不再通过“远程”PSI API 提供。
- 难以辨认的字体大小 – 页面上的字体大小太小,导致移动设备用户难以阅读。Lighthouse 会标记字体大小小于 12px 且占页面文本 40% 以上的页面。
- 不支持的插件 – 页面包含浏览器插件,例如 Flash、Silverlight 或 Java Applets,这些插件大多数移动设备和浏览器都不支持,搜索引擎也无法索引。
- 移动版替代链接 – 页面包含指向移动版本的
rel="alternate"链接元素。虽然这是一个可接受的设置,但这意味着在单独的 URL 上为每个设备提供不同的 HTML。这通常不如响应式设计方法有效。
移动问题的批量导出,包括来自 Lighthouse 的详细信息,可在“报告”菜单下找到。
请阅读我们的教程“如何审核移动可用性”。
PageSpeed Insights API 状态和错误
“PSI 状态”列显示 URL 的 API 请求是否“成功”并显示数据,或者是否存在错误且未显示数据。“错误”通常反映 Web 界面,您会在其中看到相同的错误和消息。
“PSI 错误”列显示从 PSI API 收到的完整消息,以提供有关原因的更多信息。一些错误是由于 Lighthouse 审核本身失败,其他错误可能是由于发出请求时 PSI API 不可用。
请阅读我们的常见问题解答 PageSpeed Insights API 错误 以获取更多信息。
可访问性
“可访问性”选项卡显示与运行来自 Deque University 的开源 AXE 可访问性规则集 以进行自动化可访问性验证相关的数据。这有助于网站变得更具包容性、用户友好性,并为残疾人士提供可访问性。
这与 Lighthouse 和 PageSpeed Insights 中看到的可访问性最佳实践所使用的可访问性引擎相同。
可以通过“配置 > 爬网 > 提取”(在“页面详细信息”下)启用可访问性,并且还需要通过“配置 > 爬网 > 渲染”启用 JavaScript 渲染模式,以填充“可访问性”选项卡、过滤器和问题。
(可选)要填充可访问性分数和可访问性分数列的“概述”过滤器,则必须通过“配置 > API 访问 > PSI”启用 PSI,并在“指标”选项卡中选择“可访问性分数”指标。
列
此选项卡包含以下列。
- Address – 爬取的 URL。
- Content Type – URL 的�内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- All Violations – URL 的可访问性违规总数。
- Best Practice Violations – URL 的最佳实践可访问性违规数量。
- WCAG 2.0 A Violations – URL 的 WCAG 2.0 A 可访问性违规数量。
- WCAG 2.0 AA Violations – URL 的 WCAG 2.0 AA 可访问性违规数量。
- WCAG 2.0 AAA Violations – URL 的 WCAG 2.0 AAA 可访问性违规数量。
- WCAG 2.1 AA Violations – URL 的 WCAG 2.1 AA 可访问性违规数量。
- WCAG 2.2 AA Violations – URL 的 WCAG 2.2 AA 可访问性违规数量。
- PSI Status – 要么是检索数据“成功”,要么是“错误”。
- PSI Error – 如果存在错误,则为错误响应。
- Accessibility Score – 来自 Lighthouse 审核的 URL 的 可访问性分数,范围为 0-100。
过滤器
此选项卡包含以下过滤器作为概述。
- Accessibility Score Poor – 页面的可访问性分数在 0-49 之间。为了提供良好的用户体验,网站应努力获得良好的分数 (90-100)。
- Accessibility Score Needs Improvement – 页面的可访问性分数在 50-89 之间。为了提供良好的用户体验,网站应努力获得良好的分数 (90-100)。
- Accessibility Score Good – 页面的可访问性分数在 90-100 之间。为了提供良好的用户体验,网站应努力获得良好的分数 (90-100)。
此选项卡包含以下 最佳实践规则 违规的过滤器。
- Accesskey Attribute Value Must Be Unique – 确保每个 accesskey 属性值都是唯一的。
- Ensure Elements Marked Presentational Are Ignored – 标记为 presentational 的元素不应具有全局 ARIA 或 tabindex,以确保所有屏幕阅读器都忽略它们。
- Elements Must Not Have Tabindex Greater Than Zero – 确保 tabindex 属性值不大于 0。
- Skip-link Target Should Exist & Be Focusable – 确保所有跳过链接都有一个可聚焦的目标。
- Role=text Should Have No Focusable Descendants – 确保 role=”text” 用于没有可聚焦后代的元素。
- ARIA Dialog & Alertdialog Require Accessible Name – 确保每个 ARIA 对话框和警报对话框节点都有一个可访问的名称。
- ARIA Role Should Be Appropriate For Element – 确保 role 属性具有适合元素的值。
- ARIA Treeitem Nodes Require Accessible Name – 确保每个 ARIA treeitem 节点都有一个可访问的名称。
- All Page Content Must Be Contained By Landmarks – 确保所有页面内容都包含在地标中。
- Page Requires One Main Landmark – 确保文档有一个主要地标。
- Page Must Not Have More Than One Banner Landmark – 确保文档最多有一个 banner 地标。
- Banner Landmark Must Not Be In Another Landmark – 确保 banner 地标位于顶层。
- Page Must Not Have Multiple Contentinfo Landmarks – 确保文档最多有一个 contentinfo 地标。
- Page Requires At Most One Main Landmark – 确保文档最多有一个主要地标。
- Complementary Landmarks & Asides Must Be Top Level – 确保补充地标或 aside 位于顶层。
- Contentinfo Landmark Must Be Top Level Landmark – 确保 contentinfo 地标位于顶层。
- Main Landmark Must Not Be In Another Landmark – 确保主要地标位于顶层。
- Landmarks Require Unique Role Or Accessible Name – 确保地标是唯一的。
- Form Elements Should Have Visible Label – 确保每个表单元素都有一个可见的标签,并且不仅仅使用隐藏标签或 title 或 aria-describedby 属性进行标记。
- Frames Should Be Tested With axe-core – 确保
<iframe>和<frame>元素包含 axe-core 脚本。 - Page Must Contain
<h1>– 确保页面或至少其一个框架包含一级标题。 - Heading Levels Should Only Increase By One – 确保标题的顺序在语义上是正确的。
- Headings Should Not Be Empty – 确保标题具有可辨别的文本。
- Meta Viewport Should Allow Zoom & Scale Up to 500% – 确保
<meta name=”viewport”>可以缩放很大的量。 - Alt Text Should Not Be Repeated As Text – 确保图像替代文本不会作为文本重复。
- Table Headers Require Discernible Text – 确保表头具有可辨别的文本。
- Table With Identical Summary & Caption Text – 确保
<caption>元素不包含与 summary 属性相同的文本。 - Scope Attribute Should Be Used Correctly On Tables – 确保 scope 属性在表上正确使用。
此选项卡包含以下 WCAG 2.0 A 规则 违规的过滤器。
- 滚动区域需要键盘访问 – 确保具有可滚动内容的元素可以通过键盘访问。
- 必须提供必需的 ARIA 属性 – 确保具有 ARIA 角色的元素具有所有必需的 ARIA 属性。
- ARIA 属性必须按照角色规范使用 – 确保 ARIA 属性按照元素角色规范中的描述使用。
- ARIA 属性需要有效值 – 确保所有 ARIA 属性都具有有效值。
- ARIA 属性需要有效名称 – 确保以 aria- 开头的属性是有效的 ARIA 属性。
- ARIA 命令需要可访问的名称 – 确保每个 ARIA 按钮、链接和菜单项都有一个可访问的名称。
- ARIA 输入字段需要可访问的名称 – 确保每个 ARIA 输入字段都有一个可访问的名称。
- ARIA 计量节点需要可访问的名称 – 确保每个 ARIA 计量节点都有一个可访问的名称。
- ARIA 进度条节点需要可访问的名称 – 确保每个 ARIA 进度条节点都有一个可访问的名称。
- ARIA 角色必须包含在必需的父级中 – 确保具有需要父角色的 ARIA 角色的元素包含在其中。
- ARIA 角色需要有效值 – 确保具有 role 属性的所有元素都使用有效值。
- ARIA 切换字段需要可访问的名称 – 确保每个 ARIA 切换字段都有一个可访问的名称。
- ARIA 工具提示节点需要可访问的名称 – 确保每个 ARIA 工具提示节点都有一个可访问的名称。
- 某些 ARIA 角色必须包含特定的子角色 – 确保具有需要子角色的 ARIA 角色的元素包含它们。
- 不得使用已弃用的 ARIA 角色 – 确保元素不使用已弃用�的角色。
- Aria-braille 需要非盲文等效项 – 确保 aria-braillelabel 和 aria-brailleroledescription 具有非盲文等效项。
- Aria-hidden 元素包含可聚焦元素 – 确保 aria-hidden 元素不可聚焦,也不包含可聚焦元素。
- Aria-hidden=true 不得在
<body>中使用 – 确保 aria-hidden=”true” 不存在于文档主体中。 - 元素只能使用允许的 ARIA 属性 – 确保 ARIA 属性不禁止用于元素角色。
- 元素必须使用允许的 ARIA 属性 – 确保元素角色支持其 ARIA 属性。
- ARIA 和标签中使用的 ID 必须是唯一的 – 确保 ARIA 和标签中使用的每个 id 属性值都是唯一的。
- 页面需要绕过重复块的方法 – 确保每个页面至少有一种机制,供用户绕过导航并直接跳转到内容。
- 表单
<input>元素需要标签 – 确保每个表单元素都有一个标签。 - 表单字段不得有多个标签元素 – 确保表单字段没有多个标签元素。
- 框架需要标题属性 – 确保
<iframe>和<frame>元素具有可访问的名称。 - 框架需要唯一的标题属性 – 确保
<iframe>和<frame>元素包含唯一的标题属性。 - 具有可聚焦内容的框架不得使用 tabindex=-1 – 确保具有可聚焦内容的
<frame>和<iframe>元素没有 tabindex=-1 - 页面必须包含
<title>– 确保每个 HTML 文档都包含一个非空的<title>元素。 - HTML 元素 Lang 属性值必须有效 – 确保
<html>元素的 lang �属性具有有效值。 - HTML 元素需要 Lang 属性 – 确保每个 HTML 文档都有一个 lang 属性。
- HTML Lang 和 XML Lang 值应匹配 – 确保具有有效 lang 和 xml:lang 属性的 HTML 元素在页面的基本语言上达成一致。
- 不得存在定时 Meta 刷新 – 确保
<meta http-equiv=”refresh”>不用于延迟刷新。 - 图像按钮需要替代文本 – 确保
<input type=”image”>元素具有替代文本。 - 图像需要替代文本 – 确保
<img>元素具有替代文本或 none 或 presentation 角色。 <object>元素需要替代文本 – 确保<object>元素具有替代文本。- 活动的
<area>元素需要替代文本 – 确保图像映射的<area>元素具有替代文本。 - 标记为 role=img 的元素需要替代文本 – 确保 [role=”img”] 元素具有替代文本。
- SVG 图像和图形需要可访问的文本 – 确保具有 img、graphics-document 或 graphics-symbol 角色的
<svg>元素具有可访问的文本。 - 不得使用服务器端图像映射 – 确保不使用服务器端图像映射。
<video>元素需要<track>用于字幕 – 确保<video>元素具有字幕。<video>或<audio>元素不得自动播放 – 确保<video>或<audio>元素在没有停止或静音音频的控制机制的情况下,自动播放音频的时间不超过 3 秒。- 按钮需要可辨别的文本 – 确保按钮具有可辨别�的文本。
- 输入按钮需要可辨别的文本 – 确保输入按钮具有可辨别的文本。
- 链接必须可区分 – 确保链接与周围文本的区分方式不依赖于颜色。
- 链接需要可辨别的文本 – 确保链接具有可辨别的文本。
- Select 元素需要可访问的名称 – 确保 select 元素具有可访问的名称。
- Summary 元素需要可辨别的文本 – 确保 summary 元素具有可辨别的文本。
- 不得使用已弃用的
<marquee>元素 – 确保不使用<marquee>元素。 <blink>元素已弃用且不得使用 – 确保不使用<blink>元素。- 交互式控件不得嵌套 – 确保交互式控件不嵌套,因为屏幕阅读器并不总是宣布它们,或者可能导致辅助技术出现焦点问题。
- 列表项必须包含在列表元素中 – 确保
<li>元素以语义方式使用。 - 列表只能包含
<li>内容元素 – 确保列表结构正确。 <dl>只能有排序的<dt>和<dd>组 – 确保<dl>元素结构正确。<dt>和<dd>元素必须包含在<dl>中 – 确保<dt>和<dd>元素包含在<dl>中。<th>元素需要关联的数据单元格 – 确保<th>元素和具有 role=columnheader/rowheader 的元素具有它们描述的数据单元格。- 表头 Attr 必须引用同一表中的单元格 – 确保表中每个使用 headers 属性的单元格仅引用该表中的其他单元格。
此选项卡包含以下 WCAG 2.0 AA 规则 违规的过滤器。
- Meta Viewport 缩放和缩放已禁用 – 确保
<meta name=”viewport”>不会禁用文本缩放和缩放。 - Lang 属性需要有效值 – 确保 lang 属性具有有效值。
- 文本需要更高的颜色对比度才能显示背景 – 确保前景和背景颜色之间的对比度符合 WCAG 2 AA 的最低对比度阈值。
此选项卡包含以下 WCAG 2.0 AAA 规则 违规的过滤器。
- 不得使用延迟的 Meta 刷新 – 确保
<meta http-equiv=”refresh”>不用于延迟刷新。 - 具有相同可访问名称的链接 – 确保具有相同可访问名称的链接具有相似的用途。
- 文本需要更高的颜色对比度 – 确保前景和背景颜色之间的对比度符合 WCAG 2 AAA 的增强对比度阈值。
此选项卡包含以下 WCAG 2.1 AA 规则 违规的过滤器。
- 必须正确使用自动完成属性 – 确保自动完成属性正确且适合表单字段。
- 必须可调整内联文本间距 – 确保可以通过自定义样式表调整通过样式属性设置的文本间距。
此选项卡包含以下 WCAG 2.2 AA 规则 违规的过滤器。
- 触摸目标需要足够的尺寸和间距 – 确保触摸目标具有足够的尺寸和空间。
可批量导出可访问性问题,包括位置的详细信息,可在“批量导出 > 可访问性”下找到。
请阅读我们的教程“如何执行 Web 可访问性审核”。
自定义搜索
自定义搜索选项卡与自定义搜索配置一起使用。自定义搜索功能允许您搜索 HTML 页面的源代码,并且可以通过单击“配置 > 自定义 > 搜索”进行配置。
您可以在自定义搜索配置中配置多达 100 个搜索过滤器,这些过滤器允许您输入正则表达式并查找“包含”或“不包含”您选择的输入的页面。结果将显示在自定义搜索选项卡中,如下所述。
列
此选项卡包含以下列。
- 地址 – 抓取的 URI。
- 内容 – URI 的内容类型。
- 状态代码 – HTTP 响应代码。
- 状态 – HTTP 标头响应。
- 包含:[x] – [x] 在 URL 的源代码中出现的次数。[x] 是在自定义搜索配置中输入的查询字符串。
- 不包含:[y] – 该列将返回“包含”或“不包含”[y]。[y] 是在自定义搜索配置中输入的查询字符串。
过滤器
此选项卡包含以下过滤器。
- [搜索过滤器名称] – 过滤器是动态的,将与自定义配置的名称和相关列匹配。它们显示包含或不包含输入的查询字符串的 URL。
请阅读我们的教程“如何使用自定义搜索”。
自定义提取
自定义提取选项卡与自定义提取配置一起使用。此功能允许您从抓取的页面的 HTML 中抓取任何数据,并且可以在“配置 > 自定义 > 提取”下进行配置。
您可以在自定义提取配置中配置多达 100 个提取器,这些提取器允许您输入 XPath、CSSPath 或正则表达式来抓取所需的数据。提取仅针对具有 HTML 内容类型的 URL 执行。
结果将显示在自定义提取选项卡中,如下所述。
列
此选项卡包含以下列。
- 地址 – 抓取的 URI。
- 内容 – URI 的内容类型。
- 状态代码 – HTTP 响应代码。
- 状态 – HTTP 标头响应。
- [提取器名称] – 列标题名称是动态的,基于提供给每个提取器的名称。每个提取器将有一个单独的命名列,其中包含针对每个 URL 提取的数��据。
过滤器
此选项卡包含以下过滤器。
- [提取器名称] – 过滤器是动态的,将与提取器的名称和相关列匹配。它们显示针对 URL 的相关提取列。
请阅读我们的教程“Web 抓取和自定义提取”。
自定义 JavaScript
自定义 JavaScript 选项卡与自定义 JavaScript配置一起使用。此功能允许您执行自定义 JS 代码段以在抓取时执行操作或提取数据,并且可以在“配置 > 自定义 > 自定义 JavaScript”下进行配置。
您可以在自定义 JavaScript 配置中配置多达 100 个 JS 代码段。自定义 JS 代码段仅针对内部 URL 运行。
结果将显示在自定义 JavaScript 选项卡中,如下所述。
列
此选项卡包含以下列。
- 地址 – 抓取的 URL。
- 内容类型 – URL 的内容类型。
- 状态代码 – HTTP 响应代码。
- 状态 – HTTP 标头响应。
- [代码段名称] – 列标题名称是动态的,基于提供给每个代码段的名称。每个代码段将有一个单独的命名列,其中包��含针对每个 URL 提取的数据。
过滤器
此选项卡包含以下过滤器。
- [代码段名称] – 过滤器是动态的,将与代码段的名称和相关列匹配。它们显示针对 URL 的相关代码段列。
请注意:只有设置为“提取”类型的代码段才会显示在自定义 JavaScript 选项卡中,并且具有过滤器或列。“操作”代码段执行操作,而不是提取数据,因此不会显示。
请阅读我们的教程“如何调试自定义 JavaScript 代码段”。
分析
当 SEO Spider 在“配置 > API 访问 > Google Analytics(分析)”下与 Google Analytics(分析)集成时,分析选项卡包含来自 Google Analytics(分析)的数据。请阅读我们的 Google Analytics(分析)集成 指南以获取更多详细信息。
SEO Spider 目前允许您一次选择最多 30 个指标,但默认情况下,它将收集以下 10 个 Google Analytics(分析)指标。
列
此选项卡包含以下列。
- 会话数
- % 新会话
- 新用户数
- 跳出率
- 每次会话浏览页数
- 平均会话时长
- 页面价值
- 目标转化率
- 所有目标完成次数
- 所有目标价值
您可以从 Google 获取有关每个指标的定义的更多信息。
请阅读我们的 Google Analytics(分析)集成 用户指南,以获取有关配置您的帐户、媒体资源、视图、细分、日期范围、指标和维度的更多信息。
过滤器
此选项卡包含以下过滤器。
- Sessions Above 0 – 这仅仅意味着相关的 URL 拥有 1 个或多个会话。
- Bounce Rate Above 70% – 这意味着该 URL 的跳出率超过 70%,您可能希望对此进行调查。但在某些情况下,这是正常的!
- No GA Data – 这意味着对于查询的指标和维度,Google API 没有返回爬取中 URL 的任何数据。因此,这些 URL 要么没有收到任何会话,要么爬取中的 URL 由于某种原因与 GA 中的 URL 不同。
- Non-Indexable with GA Data – 被归类为不可索引,但拥有 Google Analytics 数据的 URL。
- Orphan URLs – 通过 Google Analytics 发现的 URL,而不是在爬取期间通过内部链接发现的。此过滤器要求在 Google Analytics 配置窗口的“常规”选项卡(Configuration > API Access > Google Analytics)下启用“Crawl New URLs Discovered In Google Analytics”,并在填充“爬取分析”之后启用。请参阅我们的如何查找孤立页面指南。
Search Console
当 SEO Spider 与 Google Search Console 集成时,“Search Console”选项卡包含来自 Search Analytics 和 URL Inspection API 的数据,集成路径为“Configuration > API Access > Google Search Console”。
请阅读我们的 Google Search Console 集成 指南以获取更多详细信息。 集成后,将收集以下数据。
Columns
默认情况下,此选项卡包含来自 Search Analytics 的以下列。
- Clicks
- Impressions
- CTR
- Position
您可以阅读更多关于 Google 对每个指标的定义。
或者,您可以选择在 Search Analytics 数据旁边“启用 URL 检查”,这将每天为每个属性提供最多 2,000 个 URL 的 Google 索引状态数据。 这包括 URL Inspection API 的以下列。
- Summary – 关于 URL 是否已编入索引并有资格显示在 Google 搜索结果中的顶级判断。“URL is on Google”表示该 URL 已编入索引,可以出现在 Google 搜索结果中,并且在页面中发现的任何增强功能(富媒体搜索结果、移动设备、AMP)都没有发现问题。“URL is on Google, but has Issues”表示它已编入索引并且可以出现在 Google 搜索结果中,但移动设备可用性、AMP 或富媒体搜索结果存在一些问题,这可能意味着它不会以最佳方式显示。“URL is not on Google”表示它未被 Google 编入索引,也不会出现在搜索结果中。此过滤器可以包括不可索引的 URL(例如那些“noindex”的 URL)以及能够被索引的可索引 URL。
- Coverage – URL 状态的简短描述性原因,解释了 URL 为何在或不在 Google 上。
- Last Crawl – Google 上次抓取此页面的时间,以您的当地时间为准。此工具中显示的所有信息均来自上次抓取的版本。
- Crawled As – 用于抓取的用户代理类型(桌面或移动设备)。
- Crawl Allowed – 指示您的网站是否允许 Google 抓取(访问)该页面,或者是否使用 robots.txt 规则阻止了它。
- Page Fetch – Google 是否真的可以从您的服务器获取该页面。 如果不允许抓取,则此字段将显示失败。
- Indexing Allowed – 您的页面是否明确禁止索引。 如果禁止索引,则会解释原因,并且该页面不会出现在 Google 搜索结果中。
- User-Declared Canonical – 如果您的页面明确声明了规范 URL,它将在此处显示。
- Google-Selected Canonical – 当 Google 在您的网站上找到相似或重复的页面时,Google 选择作为规范(权威)URL 的页面。
- Mobile Usability – 页面是否适合移动设备。
- Mobile Usability Issues – 如果“页面不适合移动设备”,则此列将显示移动设备可用性错误的列表。
- AMP Results – 关于 AMP URL 是否有效、无效或有警告的判断。“Valid”表示 AMP URL 有效且已编入索引。“Invalid”表示 AMP URL 存在错误,这将阻止它被编入索引。“Valid with warnings”表示 AMP URL 可以被编入索引,但存在一些问题可能会阻止它获得完整功能,或者它使用已弃用的标签或属性,并且将来可能会失效。
- AMP Issues – 如果 URL 存在 AMP 问题,则此列将显示 AMP 错误的列表。
- Rich Results – 关于在页面上找到的富媒体搜索结果是否有效、无效或有警告的判断。“Valid”表示已找到富媒体搜索结果并且有资格进行搜索。“Invalid”表示页面上的一个或多个富媒体搜索结果存在错误,这将阻止它有资格进行搜索。“Valid with warnings”表示页面上的富媒体搜索结果有资格进行搜索,但存在一些问题可能会阻止它获得完整功能。
- Rich Results Types – 在页面上发现的所有富媒体搜索结果增强功能的逗号分隔列表。
- Rich Results Types Errors – 在页面上发现的所有带有错误的富媒体搜索结果增强功能的逗号分隔列表。 要导出发现的特定错误,请使用“Bulk Export > URL Inspection > Rich Results”导出。
- Rich Results Warnings – 在页面上发现的所有带有警告的富媒体搜索结果增强功能的逗号分隔列表。 要导出发现的特定警告,请使用“Bulk Export > URL Inspection > Rich Results”导出。
您可以阅读更多关于 Google 的索引 URL 结果。
Filters
此选项卡包括以下过滤器。
- Clicks Above 0 – 这仅仅意味着相关的 URL 拥有 1 个或多个点击。
- No Search Analytics Data – 这意味着 Search Analytics API 没有返回爬取中 URL 的任何数据。因此,这些 URL 要么没有收到任何展示,要么爬取中的 URL 由于某种原因与 GSC 中的 URL 不同。
- Non-Indexable with Search Analytics Data – 被归类为不可索引,但拥有 Google Search Analytics 数据的 URL。
- Orphan URLs – 通过 Google Search Analytics 发现的 URL,而不是在爬取期间通过内部链接发现的。此过滤器要求在 Google Search Console 配置的“Search Analytics”选项卡(“Configuration > API Access > Google Search Console > Search Analytics”)中启用“Crawl New URLs Discovered In Google Search Console”,并在填充“爬取分析”之后启用。请参阅我们的如何查找孤立页面指南。
- URL Is Not on Google – 该 URL 未被 Google 编入索引,也不会出现在搜索结果中。此过滤器可以包括不可索引的 URL(例如那些“noindex”的 URL)以及能够被索引的可索引 URL。 它是根据 API 抓取所有不在 Google 上的内容的过滤器。
- Indexable URL Not Indexed – 在爬取中发现的、未被 Google 编入索引且不会出现在搜索结果中的可索引 URL。 这可以包括 Google 未知的 URL,或已发现但未编入索引的 URL 等等。
- URL is on Google, But Has Issues – 该 URL 已编入索引,可以出现在 Google 搜索结果中,但移动设备可用性、AMP 或富媒体搜索结果存在一些问题,这可能意味着它不会以最佳方式显示。
- User-Declared Canonical Not Selected – Google 已选择索引与用户在 HTML 中声明的 URL 不同的 URL。 规范是提示��,有时 Google 在这方面做得很好,有时则不太理想。
- Page Is Not Mobile Friendly – 该页面在移动设备上存在问题。
- AMP URL Is Invalid – AMP 存在错误,这将阻止它被编入索引。
- Rich Result Invalid – 该 URL 在一个或多个富媒体搜索结果增强功能中存在错误,这将阻止富媒体搜索结果显示在 Google 搜索结果中。 要导出发现的特定错误,请使用“Bulk Export > URL Inspection > Rich Results”导出。
有关使用 URL Inspection API 的更多信息,请阅读我们的指南“如何自动化 URL Inspection API”。
Validation
“Validation”选项卡执行一些基本的最佳实践验证,这些验证可能会在抓取和索引时影响抓取工具。 这不是 W3C HTML 验证,它有点过于严格,此选项卡的目的是识别可能影响搜索机器人可靠地解析和理解页面的问题。
Columns
此选项卡包括以下列。
- Address – URL 地址。
- Content – URL 的内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。 例如,如果它被规范化到另一个 URL。
Filters
此选项卡包括以下过滤器。
<head>中无效的 HTML 元素 –<head>中包含无效 HTML 元素的页面。当在<head>中使用无效元素时,Google 会假定<head>元素结束,并忽略出现在无效元素之后的任何元素。这意味着出现在无效元素之后的关键<head>元素将不会被看到。根据 HTML 标准,<head>元素仅保留用于 title、meta、link、script、style、base、noscript 和 template 元素。<body>元素位于<html>之前 – 页面中 body 元素位于 opening html 元素之前。浏览器和 Googlebot 会自动假定 body 的开始,并在其之前生成一个空的 head 元素。这意味着下面的预期 head 元素及其元数据将在 body 中被看到并被忽略。<head>不是<html>元素中的第一个元素 – HTML 元素位于 HTML 中的<head>元素之前的页面。<head>应该是<html>元素中的第一个元素。如果<head>不是 HTML 中的第一个元素,浏览器和 Googlebot 将自动生成一个<head>元素。虽然理想情况下<head>元素应该在<head>中,但如果有效的<head>元素是<html>中的第一个元素,它将被视为生成的<head>的一部分。但是,如果在预期的<head>元素及其元数据之前使用了非<head>元素(例如<p>、<body>、<img>等),则 Google 会假定<head>元素结束。这意味着预期的<head>元素及其元数据可能只会在<body>中被看到并被忽略。- 缺少
<head>标签 – HTML 中缺少<head>元素的页面。<head>元素是页面元数据的容器,位于<html>和<body>标签之间。元数据用于定义页面标题、字符集、样式、脚本、视口以及对页面至关重要的其他数据。如果标记中省略了<head>元素,浏览器和 Googlebot 将自动生成一个<head>元素,但是它可能不包含对页面有意义的元数据,因此不应依赖它。 - 多个
<head>标签 – HTML 中包含多个<head>元素的页面。HTML 中应该只有一个<head>元素,其中包含文档的所有关键元数据。如果随后的<head>元素都在<body>之前,浏览器和 Googlebot 将合并其中的元数据,但是不应依赖此行为,并且可能会出现混淆。<body>开始后的任何<head>标签都将被忽略。 - 缺少
<body>标签 – HTML 中缺少<body>元素的页面。<body>元素包含页面的所有内容,包括链接、标题、段落、图像等。页面的 HTML 中应该有一个<body>元素。如果标记中省略了<body>元素,浏览器和 Googlebot 将自动生成一个<body>元素,但是不应依赖此行为。 - 多个
<body>标签 – HTML 中包含多个<body>元素的页面。HTML 中应该只有一个<body>元素,其中包含文档的所有内容。浏览器和 Googlebot 将尝试合并随后的<body>元素中的内容,但是不应依赖此行为,并且可能会出现混淆。 - HTML 文档超过 15MB – 文档大小超过 15MB 的页面。这一点很重要,因为 Googlebot 将其抓取和索引限制为 HTML 文件或受支持的基于文本的文件的第一个 15MB。此大小不包括 HTML 中引用的资源,例如图像、视频、CSS 和 JavaScript,这些资源是单独获取的。Google 仅考虑文件的前 15MB 进行索引,并在之后停止抓取。文件大小限制应用于未压缩的数据。HTML 文件的中位数大小约为 30 千字节 (KB),因此页面不太可能达到此限制。
- 资源超过 15mb – JavaScript 和 CSS 文件大小超过 15mb。这一点很重要,因为 Googlebot 将其抓取和索引限制为文件的第一个 15MB。这意味着 JavaScript 或 CSS 中超出此限制的任何内容都可能无法处理。Google 仅考虑文件的前 15MB 进行索引,并在之后停止抓取。文件大小限制应用于未压缩的数据。
- 高碳评级 – 使用 Sustainable Web Design 的数字碳评级系统,碳评级为 F 的页面。此比例将 HTTP Archive 跟踪的页面权重与每次页面浏览的 CO2 估算值相关联。CO2 计算使用“可持续 Web 设计模型”来计算排放量,该模型在计算中考虑了数据中心、网络传输和设备使用情况。
有关 <head> 中无效 HTML 元素的更多信息,请阅读我们的指南“ 如何调试 Head 中无效的 HTML 元素”。
链接指标
当 SEO Spider 与 Majestic、Ahrefs 和 Moz 的 API 集成时,“链接指标”选项卡包含来自这些工具的数据。
要提取链接指标,只需转到“Configuration > API Access”。选择一个工具后,您需要生成并插入一个 API 密钥。连接后,运行抓取,数据将针对 URL 进行填充。
请阅读以下指南,了解有关分别使用每个工具设置 API 的更多详细信息:
列和指标
- Address – URL 地址
- Status Code – HTTP 响应代码
- Title 1 – 在 URL 上发现的(第一个)页面标题
集成后,可以为以下指标组收集链接数据:
- Exact URL
- Exact URL (HTTP + HTTPS)
- Subdomain
- Domain
Majestic 指标
- External Backlinks
- Referring Domains
- Trust Flow
- Citation Flow
- Referring IPs
- Referring Subnets
- Indexed URLs
- External Backlinks EDU
- External Backlinks GOV
- Referring Domains EDU
- Referring Domains GOV
- Trust Flow Topics
- Anchor Text
您可以阅读更多关于 Majestic 中每个指标的定义。
Ahrefs 指标
- Backlinks
- RefDomains
- URL Rating
- RefPages
- Pages
- Text
- Image
- Site Wide
- Not Site Wide
- NoFollow
- DoFollow
- Redirect
- Canonical
- Gov
- Edu
- HTML Pages
- Links Internal
- Links External
- Ref Class C
- Refips
- Linked Root Domains
- GPlus
- Facebook Likes
- Facebook Shares
- Facebook Comments
- Facebook Clicks
- Facebook Comments Box
- Total Shares
- Medium Shares
- Keywords
- Keywords Top 3
- Keywords Top 10
- Traffic
- Traffic Top 3
- Traffic Top 10
- Value
- Value Top 3
- Value Top 10
您可以阅读更多关于 Ahrefs 中每个指标的定义。
Moz 指标
- Page Authority
- MozRank
- MozRank External Equity
- MozRank Combined
- MozTrust
- Time Last Crawled (GMT)
- Total Links (Internal or External)
- External Equity-Passing Links
- Total Equity-Passing Links (internal or External)
- Subdomains Linking
- Total Linking Root Domains
- Total External Links
- Spam Score
- Links to Subdomain
- Root Domains Linking to Subdomain
- External Links to Subdomain
- Domain Authority
- Root Domains Linking
- Linking C Blocks
- Links to Root Domain
- External Links to Root Domain
您可以阅读更多关于 Moz 中每个指标的定义。
AI
“AI”选项卡与 OpenAI、Gemini 和 Ollama 的 AI API 配置一起工作。
此功能允许您直接连接到这些 AI API,并使用抓取数据设置自定义提示,这些提示可以在“Config > API Access > AI”下进行配置。
您最多可以配置 100 个自定义 AI 提示。结果将显示在“AI”选项卡中,如下所述。
列
此选项卡包含以下列。
- Address – 抓取的 URL。
- Content Type – URL 的内容类型。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Indexability – URL 是否可索引或不可索引。
- Indexability Status – URL 不可索引的原因。例如,如果它被规范化到另一个 URL。
- [Prompt Name] – 列标题名称是动态的,基于提供给每个提示的名称。每个提示将有一个单独的命名列,其中将包含每个 URL 的提示结果。
过滤器
此选项卡包含以下过滤器。
- [Prompt Name] – 过滤器是动态的,并将匹配提示的名称和相关列。它们显示针对 URL 的相关提示列。
变更检测
“变更检测”选项卡包含有关当前和先前抓取之间变更的数据和过滤器。
只有在执行 抓取比较时处于 “比较”模式时,此选项卡才可用。
在“比较”模式下,通过“Config > Compare”(或顶部的“齿轮”图标)单击比较配置,然后选择要识别变更的元素和指标。
运行抓取比较后,“变更检测”选项卡将出现在主视图和“概述”选项卡中,其中包含针对所选任何元素和指标的过滤器,以及发现的变更的详细信息。
列
此选项卡包含当前和先前抓取的以下列。
- Address – URL 地址。
- Indexability – URL 是否 可索引或不可索引。
- Title 1 – 在页面上发现的(第一个)页面标题。
- Meta Description 1 – 页面上的(第一个)元描述。
- h1 – 1 – 页面上的第一个 h1(标题)。
- Word Count – 这是 body 标签内的所有“单词”,不包括 HTML 标记。计数基于可以在“Config > Content > Area”下调整的 内容区域。默认情况下,nav 和 footer 元素被排除。您可以包含或排除 HTML 元素、类和 ID 以计算精细的字数统计。我们的数字可能与手动执行此计算所找到的数字不完全相同,因为解析器会对无效 HTML 执行某些修复。您的 渲染设置也会影响考虑的 HTML。我们对单词的定义是获取文本并按空格分隔。不考虑内容的可见性(例如,设置为隐藏的 div 中的文本)。
- Crawl Depth – 页面与起始页面的深度(与起始页面的“点击”次数)。请注意,目前在我们的页面深度计算中,重定向被计为一个级别。
- Inlinks – 指向 URL 的内部超链接的数量。“内部入站链接”是指从正在抓取的同一子域指向给定 URL 的锚元素中的链接。
- Unique Inlinks – 指向 URL 的“唯一”内部入站链接的数量。“内部入站链接”是指从正在抓取的同一子域指向给定 URL 的锚元素中的链接。例如,如果“页面 A”链接到“页面 B”3 次,则这将计为 3 个入站链接和 1 个指向“页面 B”的唯一入站链接。
- Outlinks – 来自 URL 的内部出站链接的数量。“内部出站链接”是指从给定 URL 到正在抓取的同一子域上的其他 URL 的锚元素中的链接。
- Unique Outlinks – 来自 URL 的唯一内部出站链接的数量。“内部出站链接”是指从给定 URL 到正在抓取的同一子域上的其他 URL 的锚元素中的链接。例如,如果“页面 A”在同一子域上链接到“页面 B”3 次,则这将计为 3 个出站链接和 1 个指向“页面 B”的唯一出站链接。
- External Outlinks – 来自 URL 的外部出站链接的数量。“外部出站链接”是指从给定 URL 到另一个子域的锚元素中的链接。
- Unique External Outlinks – 来自 URL 的唯一外部出站链接的数量。“外部出站链接”是指从给定 URL 到另一个子域的锚元素中的链接。例如,如果“页面 A”在不同的子域上链接到“页面 B”3 次,则这将计为 3 个外部出站链接和 1 个指向“页面 B”的唯一外部出站链接。
- Unique Types – 为 URL 发现的结构化数据 itemtype 的唯一数量。
过滤器
此选项卡包含以下过滤器。
- Indexability – 索引性已更改的页面(可索引或不可索引)。
- Page Titles – 页面标题元素已更改的页面。
- Meta Description – 元描述已更改的页面。
- H1 – h1 已更改的页面。
- Word Count – 字数统计已更改的页面。
- Crawl Depth – 抓取深度已更改的页面。
- Inlinks – 入站链接已更改的页面。
- Unique Inlinks – 唯一入站链接已更改的页面。
- Internal Outlinks – 内部出站链接已更改的页面。
- Unique Internal Outlinks – 唯一内部出站链接已更改的页面。
- External Outlinks – 外部出站链接已更改的页面。
- Unique External Outlinks – 唯一外部出站链接已更改的页面。
- Structured Data Unique Types – 结构化数据 itemtype 的唯一数量已更改的页面。
- Content – 内容更改超过 10% 的页面(或在“Config > Compare”下配置的相似度更改)。
有关变更检测的更多信息,请阅读�我们的教程“ 如何比较抓取”。
URL 详情
如果在顶部窗口中突出显示一个 URL,则会填充此底部窗口选项卡。其中包含有关所讨论 URL 的概述。这是从顶部窗口 内部选项卡 中报告的列中选择的数据,包括:
- URL – 抓取的 URL。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Content – URL 的内容类型。
- Size – 文件或网页大小。
- Crawl Depth – 页面从主页或起始页的深度(距离起始页的“点击”次数)。
- Inlinks – 指向该 URL 的内部链接数量。
- Outlinks – 从该 URL 指出的内部链接数量。
内部链接
如果在顶部窗口中突出显示一个 URL,则会填充此底部窗口选项卡。其中包含指向该 URL 的内部链接列表。
- Type – 抓取的 URL 类型(超链接、JavaScript、CSS、图像等)。
- From – 引用页面的 URL。
- To – 在主窗口中选择的当前 URL。
- Anchor Text – 使用的锚文本或链接文本(如果有)。
- Alt Text – 使用的 alt 属性(如果有)。
- Follow – “True”表示链接被跟踪。“False”表示链接包含“nofollow”、“UGC”或“sponsored”属性。
- Target – 关联的目标属性(_blank、_self、_parent 等)。
- Rel – 关联的链接属性(仅限于“nofollow”、“sponsored”和“ugc”)。
- Status Code – HTTP 响应代码。
- Status – HTTP 标头响应。
- Path Type – 链接的 href 属性是绝对链接、协议相对链接、根相对链接还是路径相对链接
- Link Path – 详细说明页面中链接位置的 XPath。
- Link Position – 链接位于代码中的哪个位置(Head、Nav、Footer 等),可以使用 自定义链接位置 配置进行自定义。
- Link Origin – 链接是在 HTML 中(仅原始 HTML)、渲染的 HTML 中(仅在 JavaScript 处理后渲染的 HTML)、HTML 和渲染的 HTML 中(原始 HTML 和渲染的 HTML)还是动态加载的(没有链接,并且 JavaScript 动态加载到页面上)找到的。
外部链接
如果在顶部窗口中突出显示一个 URL,则会填充此底部窗口选项卡。其中包含 URL 上指向外部的内部和外部链接列表。
- Type – 抓取的 URL 类型(超链接、JavaScript、CSS、图像等)。
- From – 在主窗口中选择的当前 URL。
- To – 在主窗口中选择的当前 URL 上存在的 URL。
- Anchor Text – 使用的锚文本或链接文本(如果有)。
- Alt Text – 使用的 alt 属性(如果有)。
- Follow – “True”表示链接被跟踪。“False”表示链接包含“nofollow”、“UGC”或“sponsored”属性。
- Target – 关联的目标属性(_blank、_self、_parent 等)。
- Rel – 关联的链接属性(仅限于“nofollow”、“sponsored”和“ugc�”)。
- Status Code – “To”URL 的 HTTP 响应代码。需要抓取“To”URL 才能显示数据。
- Status – “To”URL 的 HTTP 标头响应。需要抓取“To”URL 才能显示数据。
- Path Type – 链接的 href 属性是绝对链接、协议相对链接、根相对链接还是路径相对链接
- Link Path – 详细说明页面中链接位置的 XPath。
- Link Position – 链接位于代码中的哪个位置(Head、Nav、Footer 等),可以使用 自定义链接位置 配置进行自定义。
- Link Origin – 链接是在 HTML 中(仅原始 HTML)、渲染的 HTML 中(仅在 JavaScript 处理后渲染的 HTML)、HTML 和渲染的 HTML 中(原始 HTML 和渲染的 HTML)还是动态加载的(没有链接,并且 JavaScript 动态加载到页面上)找到的。
图像详情
如果在顶部窗口中突出显示一个页面 URL,则底部窗口选项卡会填充页面上找到的图像列表。
如果在顶部窗口中突出显示一个图像 URL,则底部窗口选项卡会显示图像的预览以及以下图像详细信息。
- From – 在顶部窗口中选择的 URL。
- To – 在 URL 上找到的图像链接。
- Alt Text – 使用的 alt 属性(如果有)。
- Real Dimensions (WxH) – 下载的图像的实际尺寸。这需要 JavaScript 渲染模式,并且实际尺寸仅显示基于视口在浏览器中渲染的图像。
- Dimensions in Attributes (WxH) – 根据 width 和 height 属性在 HTML 中设置的图像尺寸。如果在 HTML 中未设置尺寸,则该图像会被标记为在 图像选项卡 中的“缺少尺寸属性”过滤器中进行潜在优化。
- Display Dimensions (WxH) – 在 Chrome 中渲染时显示的图像尺寸(可以基于 CSS,而不是 HTML 中的尺寸属性)。这需要 JavaScript 渲染模式。
- Potential Savings – 与渲染时显示尺寸相比,具有不同实际尺寸的图像的潜在文件大小节省。如果估计的文件大小差异为 4kb 或更多,则该图像会被标记为在 图像选项卡 中的“尺寸不正确的图像”过滤器中进行潜在优化。
- Path Type – 链接的 href 属性是绝对链接、协议相对链接、根相对链接还是路径相对链接
- Link Path – 详细说明页面中链接位置的 XPath。
- Link Position – 链接位于代码中的哪个位置(Head、Nav、Footer 等),可以使用 自定义链接位置 配置进行自定义。
- Link Origin – 链接是在 HTML 中(仅原始 HTML)、渲染的 HTML 中(仅在 JavaScript 处理后渲染的 HTML)、HTML 和渲染的 HTML 中(原始 HTML 和渲染的 HTML)还是动态加载的(没有链接,并且 JavaScript 动态加载到页面上)找到的。
重复详情
如果在顶部窗口中突出显示一个 URL,则会填充此底部窗口选项卡。其中包含有关所讨论 URL 的任何完全重复项和近似重复项的详细信息。
对于近似重复项,必须在抓取之前 启用,并且必须运行抓取后的 抓取分析。
这将显示识别出的每个近似重复 URL 及其相似度匹配。
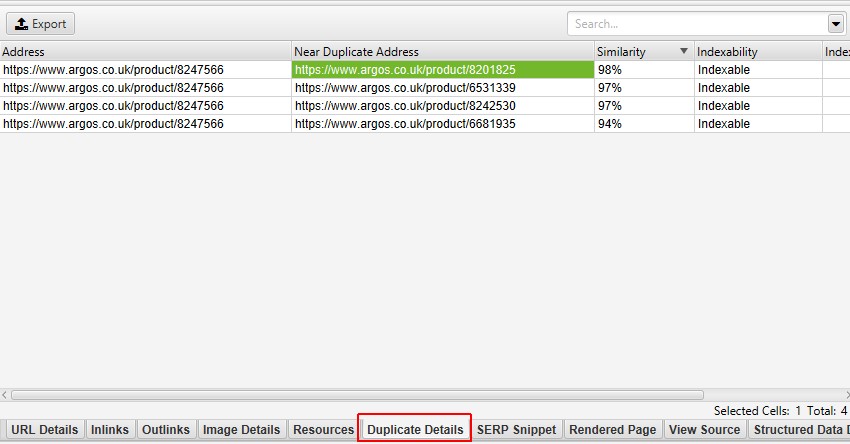
单击“重复详情”选项卡中的“近似重复地址”也将显示在页面之间发现的近似重复内容,并突出显示差异。
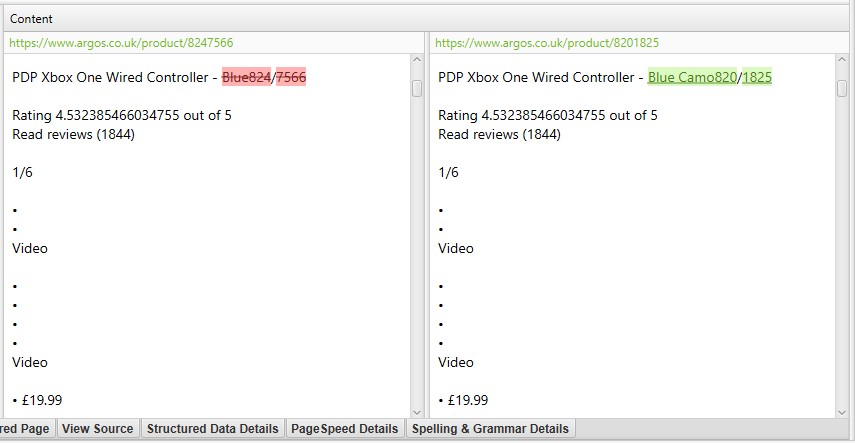
资源
在顶部窗口中突出显示一个 URL 将填充此底部窗口选项卡。此选项卡包含在 URL 上找到的资源列表。
- Type – 资源类型(JavaScript、CSS、图像等)。
- From – 在主窗口中选择的当前 URL。
- To – 在上述“From”页面 URL 上找到的资源链接。
- Anchor Text – 使用的锚文本或链接文本(如果有)。
- Alt Text – 使用的 alt 属性(如果有)。
- Follow – “True”表示链接被跟踪。“False”表示链接包含“nofollow”、“UGC”或“sponsored”属性。
- Target – 关联的目标属性(_blank、_self、_parent 等)。
- Rel – 关联的链接属性(仅限于“nofollow”、“sponsored”和“ugc”)。
- Status Code – “To”URL 的 HTTP 响应代码。需要抓取“To”URL 才能显示数据。
- Status – “To”URL 的 HTTP 标头响应。需要抓取“To”URL 才能显示数据。
- Path Type – 链接的 href 属性是绝对链接、协议相对链接、根相对链接还是路径相对链接
- Link Path – 详细说明页面中链接位置的 XPath。
- Link Position – 链接位于代码中的哪个位置(Head、Nav、Footer 等),可以使用 自定义链接位置 配置进行自定义。
- Link Origin – 链接是在 HTML 中(仅原始 HTML)、渲染的 HTML 中(仅在 JavaScript 处理后渲染的 HTML)、HTML 和渲染的 HTML 中(原始 HTML 和渲染的 HTML)还是动态加载的(没有链接,并且 JavaScript 动态加载到页面上)找到的。
SERP 片段
如果在顶部窗口中突出显示一个 URL,则会填充此底部窗口选项卡。
“SERP 片段”选项卡显示 URL 在 Google 搜索结果中的显示方式。截断点(Google 显示省略号 (…) 并截断单词的位置)是根据像素宽度而不是字符数计算的。SEO Spider 使用最新的像素宽度截断点,并计算每个字符的页面标题和元描述中使用的像素数,以显示模拟的 SERP 片段,从而提高准确性。
当前限制显示在页面标题和元描述选项卡以及过滤器“超过 X 像素”中,以及下面的“可用”像素列中。
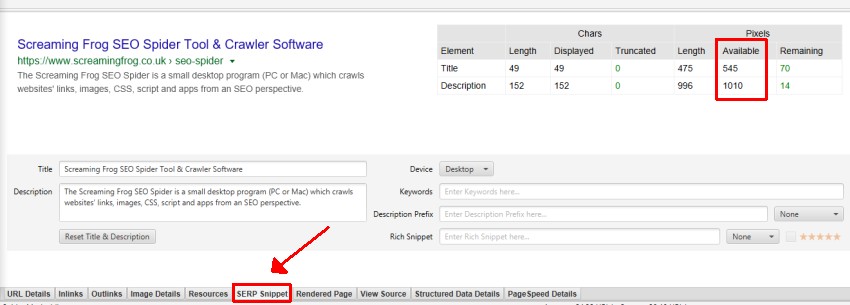
Google 会定期更改 SERP,我们在之前的博客文章中介绍了其中的一些更改,此处 和 此处。
Google 不提供像素宽度或字符长度建议,因此 SEO Spider 中的 SERP 片段模拟器基于我们在 SERP 中的研究。Google 可能会使用比显示的字符更多的字符进行评分,但是将关键信息包含在用户可见的 SERP 中非常重要。
SEO Spider 的 SERP 片段模拟器默认为桌面,并且移动设备和平板电脑的像素宽度截断点不同。您可以在“Config > Spider > Preferences”下将最大描述首选项更新为移动设备或平板电脑的长度。您可以在 SERP 片段模拟器中切换“设备”类型,以查看这些设备与桌面设备的不同之处以及我们当前估计的移动设备像素长度。
编辑 SERP 片段
您可以直接在界面中编辑页面标题和描述,以查看 SERP 片段在 Google 中的显示方式。
默认情况下,SEO Spider 会记住您对页面标题和描述所做的编辑,除非您单击“重置标题和描述”按钮。这使您可以根据需要使用模拟器进行尽可能多的更改,以完善您的 SERP 片段,导出(“Reports > SERP Summary”)并发送给客户或开发团队,以对实时站点进行更改。
请注意 - SEO Spider 不会更新您的网站,这需要单独执行。
渲染的页面
您可以在“渲染的页面”选项卡中查看 SEO Spider 抓取的渲染页面,该选项�卡在 JavaScript 渲染 模式下抓取时会填充。仅当在顶部窗口中选择 URL 时,此选项卡才会填充下部窗口窗格。
使用 JavaScript 渲染功能时,默认情况下会启用此功能,并且它与配置的 user-agent、AJAX 超时 和 视口大小 一起工作。
在左侧的下部窗口中,还可以查看渲染页面的“阻止的资源”。默认情况下,过滤器设置为“阻止的资源”,但也可以将其更改为显示页面使用的“所有资源”。
渲染的屏幕截图可在“C:\Users\User Name\.ScreamingFrogSEOSpider\screenshots-XXXXXXXXXXXXXXX”文件夹中查看,并且可以通过“批量导出 > 屏幕截图”顶级菜单导出,以节省导航、复制和粘贴的时间。
如果您正在使用 JavaScript 渲染模式,请参阅我们的 如何抓取 JavaScript 网站 指南。
查看源代码
当使用启用了“存储 HTML”或“存储渲染的 HTML”进行抓取时,此处会显示存储的 HTML 和渲染的 HTML。仅当在顶部窗口中选择 URL 时,此选项卡才会填充下部窗口窗格。
要启用存储 HTML,只需转到“Configuration > Spider > Extraction > Store HTML / Store Rendered HTML”。请注意,存储渲染的 HTML 需要在 JavaScript 渲染 模式下进行抓取。
原始 HTML 显示在左侧,而渲染的 HTML(如果已启用)显示在右侧。两个字段都有一个搜索字段并且可以导出。
更多详细信息可以在 此处 找到。
HTTP 标头
您可以查看任何突出显示的 URL 的完整 HTTP 响应和请求标头,前提是您的抓取设置为提取 HTTP 标头。仅当在顶部窗口中选择 URL 时,此选项卡才会填充下部窗口窗格。
要启用 HTTP 标头提取,请单击“Configuration > Spider > Extraction > HTTP Headers”。
该选项卡的左侧显示 HTTP 请求标头。该选项卡的右侧列出了 HTTP 响应标头。此右侧窗��口中列出的列包括:
- Header Name – 来自服务器的响应标头的名称。
- Header Value – 来自服务器的响应标头的值。
提取后,HTTP 标头会附加到“内部”选项卡中的单独的唯一列中,可以在其中与抓取数据一起查询它们。
它们也可以通过“批量导出 > Web > 所有 HTTP 标头”批量导出,或者通过“报告 > HTTP 标头 > HTTP 标头摘要”进行汇总导出。
Cookies
你可以查看在抓取任何突出显示的 URL 时发现的 Cookie,前提是你的抓取设置已提取 Cookie。你可以在顶部窗口中选择单个或多个 URL,这些 URL 会填充到下方的窗口窗格中。
要启用 Cookie 提取,请点击“Configuration > Spider > Extraction > Cookies”。需要使用 JavaScript 渲染 模式才能准确查看使用 JavaScript 或像素图像标签加载到页面上的 Cookie。
Cookies 选项卡中列出的列包括:
- Cookie Type – Cookie 的发现位置。可以是“HTTP”,也可以是“On-Page”(如果是通过 JavaScript 或像素标签)。
- Cookie Name – Cookie 的名称。
- Cookie Value – Cookie 的值。
- Domain – 发布 Cookie 的域,可以是第一方或第三方。
- Expiration Time – Cookie 的过期时间。
- Secure – Cookie 安全属性的详细信息。
- HttpOnly – Cookie HttpOnly 属性的详细信息。
- Address – 发现 Cookie 的 URL。
可以通过“Bulk Export > Web > All Cookies”批量导出 Cookie,并且可以通过“Reports > Cookies > Cookie Summary”导出聚合报告。
请注意,当你选择存储 Cookie 时,SEO Spider 对 Google Analytics 跟踪代码执行的自动排除将被禁用,以便准确查看所有已发布的 Cookie。
这意味着它会影响你的分析报告,除非你选择使用 排除 配置(“Config > Exclude”)排除任何跟踪脚本的触发,或者过滤掉类似于 排除 PSI 的“Screaming Frog SEO Spider”用户代理。
结构化数据详情
你可以查看任何突出显示的 URL 的结构化数据详情,前提是你的抓取设置已提取结构化数据。仅当在顶部窗口中选择 URL 时,此选项才会填充到下方的窗口窗格中。
要启用结构化数据提取,只需转到“Configuration > Spider > Extraction > JSON-LD/Microdata/RDFa & Schema.org Validation/Google Validation”。
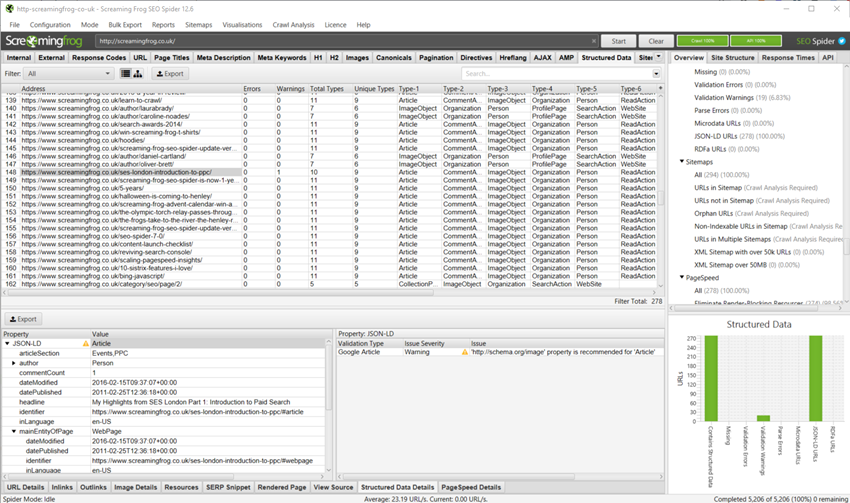
选项卡的左侧显示属性值以及错误和/或警告图标。点击其中一个值将在右侧窗口中提供有关验证错误/警告的特定详细信息。此右侧窗口中列出的列包括:
- Validation Type – 具有验证问题的结构化数据字段(文章、人物、产品等)。
- Issue Severity – 问题值是建议的还是验证所需的�。
- Issue – 有关特定问题的详细信息。
有关更多详细信息,请阅读我们的“如何测试和验证结构化数据指南”。
Lighthouse 详情
集成后,你可以查看任何突出显示的 URL 的页面速度和移动设备可用性详细信息。这将需要将抓取连接到 PageSpeed Insights API。
要提取这些指标,只需转到“Configuration > API Access > PageSpeed Insights”,插入一个免费的 PageSpeed API 密钥,或者选择在本地运行 Lighthouse,然后连接并运行抓取。
在数据可用时,在顶部窗口中选择一个 URL 将在下方的窗口选项卡中提供更多详细信息。
左侧窗口提供有关提取的指标和突出显示的 URL 特有的可用机会的特定信息。点击一个机会将在右侧窗口中显示更多信息。这包括以下列:
- The Source Page – 在顶部窗口中选择的 URL。
- URL – 具有可用机会的链接资源。
- Size (Bytes) – 列出的资源的当前大小。
- Potential Savings – 通过实施突出显示的机会可以节省的潜在大小。
有关可用速度指标和机会的完整详细信息,请参阅我们的 PageSpeed Insights 集成指南。
无障碍详情
当启用无障碍和 JavaScript 渲染时,你可以查看任何突出显示的 URL 的无障碍违规详细信息。
要查看此数据,请启用“Accessibility”(“Config > Spider > Extraction”)和“JavaScript rendering”模式(“Config > Spider > Rendering”)。
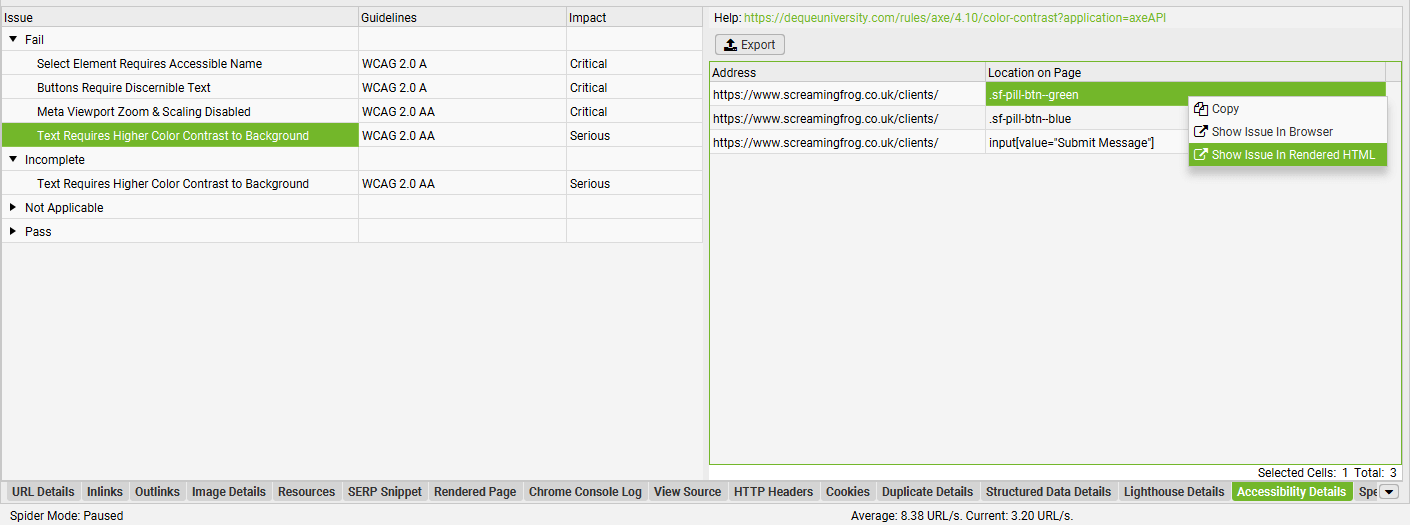
在数据可用时,在顶部窗口中选择一个 URL 将在下方的窗口选项卡中提供更多详细信息。
左侧窗口提供与突出显示的 URL 的违规(以及可能不完整、不适用或已通过的规则)、指南和每个违规的影响相关的特定信息。点击一个违规将在右侧窗口中显示更多信息。这包括以下列:
- Address – 在顶部窗口中选择的 URL。你可以在顶部窗口中突出显示多个 URL,因此这也可能显示多个 URL。
- Location on Page – 确切的无障碍问题的位置。你可以右键单击以“Show Issue in Browser”或“Show Issue In Rendered HTML”。
拼写和语法详情
如果你在顶部窗口中突出显示一个 URL,则会填充此下方的窗口选项卡。其中包含有关相关 URL 的任何拼写和语法问题的详细信息。
必须在抓取之前 启用 拼写检查和/或语法检查,才能填充此选项卡。
下方的窗口“拼写和语法详情”选项卡显示错误、类型(拼写或语法)、详细信息,并提供更正问题的建议。详细信息选项卡的右侧还显示页面文本的视觉效果以及已识别的错误。
N 元语法
N 元语法选项卡包含短语序列及其在 HTML 页面内容中的频率的详细信息。
要启用此功能,需要在“Config > Spider > Extraction”下启用“Store HTML / Store Rendered HTML”。然后在顶部窗口中突出显示一个 URL 或一组 URL,并且 N 元语法选项卡将填充聚合的 N 元语法数据。
左侧显示所有突出显示的 URL 的聚合 N 元语法。可以调整过滤器以显示一系列 N 元语法,从 1 元语法到 6 元语法。
右侧显示所选 N 元语法所在的 URL 的详细信息。在上面的示例中,突出显示了 2 元语法“broken links”,并显示在 3 个页面上。
概述
概述选项卡实时更新,以提供抓取的顶级视图。它提供 URL 数据的摘要以及每个选项卡和过滤器的总计。
- Summary – 抓取中遇到的 URL 的摘要。
- SEO Elements – 每个顶级选项卡和相应过滤器中找到的 URL 数量的摘要。此数据可用于发现问题,而无需在选项卡和过滤器中单击。它也可以用作 Spider 主窗口中选项卡和过滤器的快捷方式。
问题
问题选项卡实时更新,以提供在抓取中发现的潜在问题、警告和机会的详细信息。此数据基于概述选项卡和过滤器中的现有数据,但仅显示潜在的“问题”。
数据按问题类型、优先级进行分类,并具有应用内问题描述和提示。
- Issue Name – 基于选项卡和过滤器的issue名称。
- Issue Type – 它是“问题”、“机会”还是“警告”。
- Issue Priority – 基于潜在影响的“高”、“中”或“低”,可能需要更多关注。
- URLs – 具有该问题的 URL 数量。
- % of Total – 具有该问题的 URL 占总数的比例。
每个问题都有一个“类型”和一个基于潜在影响的估计“优先级”。
- Issues 是理想情况下应该修复的错误或问题。
- Opportunities 是优化的“潜在”领域。
- Warnings 不一定是问题,但应该检查 - 并可能修复。
优先级基于可能需要更多关注的潜在影响,而不是明确的操作 - 来自广泛接受的 SEO 最佳实践。它们不是应该在你的 SEO 策略中优先考虑或在你的 SEO 审核中“修复”的硬性规则,因为没有工具可以提供这些,因为它们缺乏上下文。
但是,它们可以帮助用户比手动过滤数据更有效地发现潜在问题。
例如 - “Directives: Noindex”将被归类为“警告”,但具有“高”优先级,因为它可能会对 URL 错误地 noindex 产生重大影响。
可以通过“Bulk Export > Issues > All”批量导出所有问题。这将导出发现的每个问题(包括其“内链”变体,例如断开的链接)作为文件夹中的单独电子表格(作为 CSV、Excel 和 Sheets)。
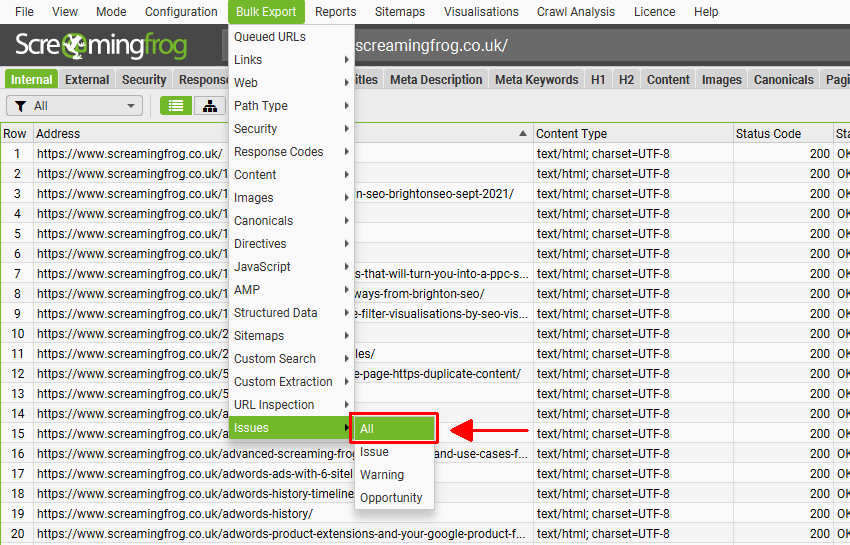
重要的是要理解,问题选项卡不能替代具有业务、SEO 和优先考虑重要事项的细微差别的专业知识和 SEO 专业人员。
问题选项卡充当指南,以帮助为可以理解数据并将其解释为与每个唯一网站和场景相关的适当优先操作的用户提供指导。
简单地导出“问题”数据本身并不是我们建议的没有专家指导和优先考虑真正重要事项的“SEO 审核”。
站点结构
站点结构选项卡实时更新,以提供网站的聚合目录树视图。这有助于可视化站点架构,并一目了然地识别问题所在,例如不同路径的可索引性。
顶部表格实时更新,以显示网站每个路径中的路径、URL 总数、可索引和不可索引的 URL。
- Path – 抓取的网站的 URL 路径。
- URLs – 在路径中找到的唯一子 URL 的总数。
- Indexable – 在路径中找到的唯一可索引子 URL 的总数。
- Non-Indexable – 在路径中找到的唯一不可索引子 URL 的总数。
你可以调整聚合站点结构的“视图”,以查看每个路径中 URL 的“可索引性状态”、“响应代码”和“抓取深度”。
下方的表格和图表显示了基于其响应代码,在 1-10+ 之间的抓取深度处的 URL 数量。
- Depth (Clicks from Start URL) – 页面与主页或起始页面的距离(与起始页面的“点击”次数)。
- Number of URLs – 在抓取中遇到的具有特定深度的 URL 数量。
- % of Total – 抓取中具有特定深度的 URL 百分比。
每个 URL 的“抓取深度”数据可以在“内部”选项卡的“抓取深度”列中找到并导出。
分段
你可以对抓取进行分段,以更好地识别和监控来自不同模板、页面类型或优先领域的issue和机会。
仅当你使用数据库 存储模式 时,分段配置和右侧选项卡才可用。如果你尚未使用数据库存储模式,我们强烈建议你使用它。
可以通过“File > Settings > Storage Mode”进行调整,并且有很多好处。
分段选项卡实时更新,以提供分段数据和 URL 的聚合视图。如果 未设置分段,则该选项卡将为空白。可以通过单击齿轮图标或通过“Config > Segments”设置分段。
为分段显示的数据包括以下内容:
- Segment – 分段名称。除非排序,否则此顺序遵循分段配置中选择的顺序。
- URLs – 分段中的 URL 数量。
- % Segmented – 从 URL 总数中分段的 URL 比例。
- Indexable – 分段中可索引的 URL 数量。
- Non-Indexable – 分段中不可索引的 URL 数量。
- Issues – 理想情况下应该修复的错误或问题。
- Warnings – 不一定是问题,但应该检查 - 并可能修复。
- Opportunities – 优化的潜在领域。
- High – 基于潜在影响的优先级,可能需要更多关注。
- Medium – 基于潜在影响的优先级,可能需要一些关注。
- Low – 基于潜在影响的优先级,可能需要较少关注。
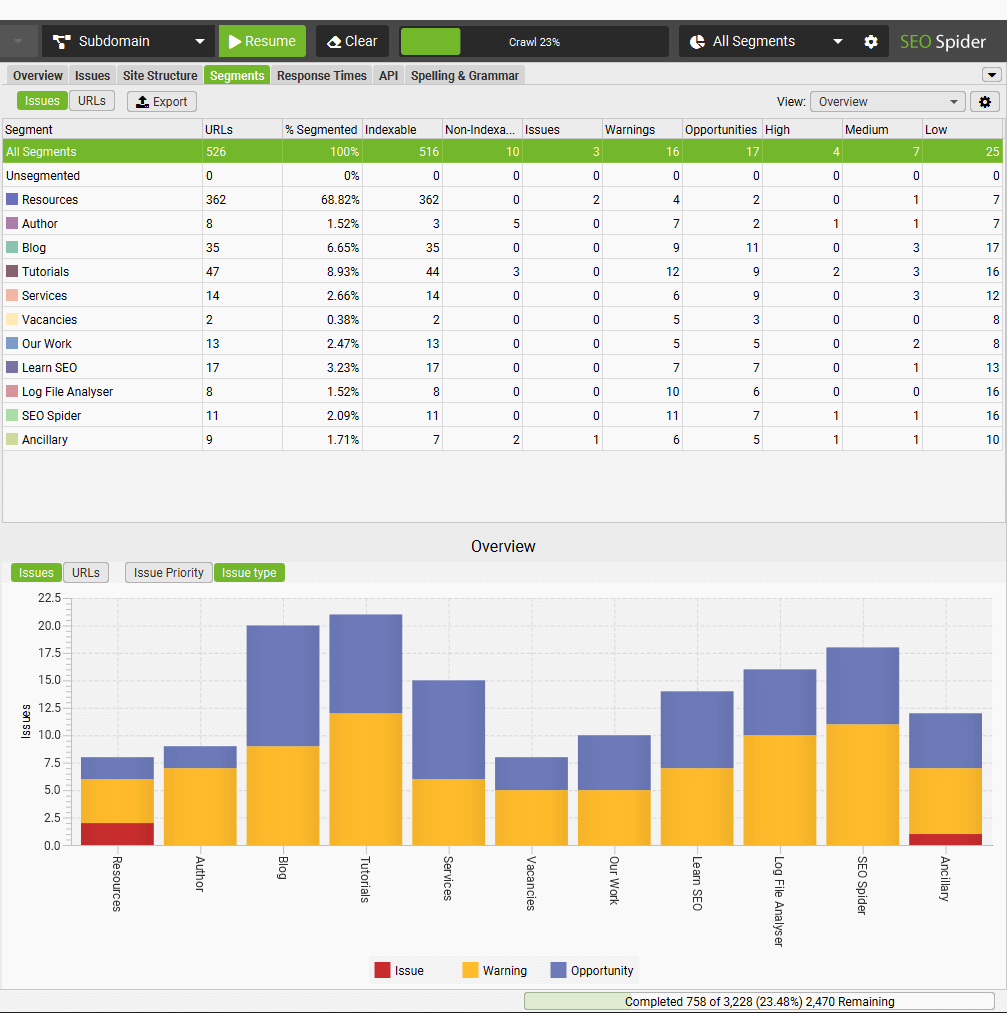
可以调整分段选项卡的“视图”过滤器,以更好地按分段分析问题、可索引性状态、响应代码和抓取深度。
响应时间
响应时间选项卡实时更新,以提供抓取期间 URL 响应时间的顶级视图。
- Response Times – 下载 URL 的时间范围(以秒为单位)。
- Number of URLs – 在特定响应时间范围内抓取中遇到的 URL 数量。
- % of Total – 在特定响应时间范围内抓取中的 URL 百分比。
响应时间是从发出 HTTP 请求并从服务器获取完整 HTTP 响应所花费的时间计算得出的。SEO Spider 界面上显示的数字以秒为单位。请注意,此数字可能无法 100% 重现,因为它很大程度上取决于服务器负载和发出请求时的客户端网络活动。
此数字不包括在 JavaScript 渲染模式下下载其他资源所花费的时间。每个资源都以其自己的单独响应时间单独显示在用户界面中。
对于彻底的 PageSpeed 分析,我们建议使用 PageSpeed Insights API 集成。
API
查看来自所有 API 的数据收集进度以及各个错误计数。
这些 API 可以通过此选项卡上的“齿轮”图标连接。 也可以通过“配置 > API 访问”并选择 API 集成来连接 API。
请通过我们用户指南中的以下链接查看有关每个集成的更多详细信息 –
拼写和语法
右侧窗格的“拼写和语法”选项卡显示了发现的前 100 个唯一错误以及它影响的 URL 数量。 这有助于查找模板中的错误,以及构建您的字典或忽略列表。 您可以右键单击并选择“忽略语法规则”、“全部忽��略”或“添加到字典”(如果适用)。
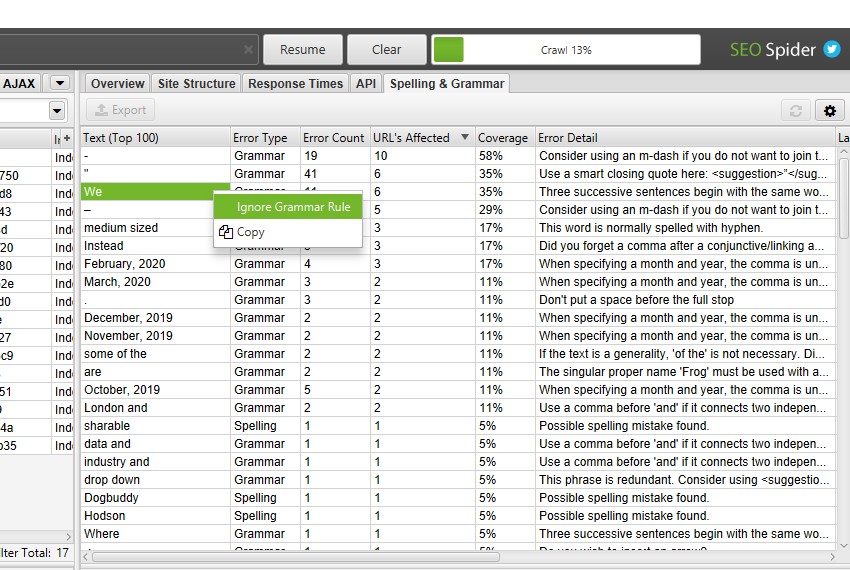
语义搜索
“语义搜索”选项卡允许您输入搜索查询以返回抓取中最相关的页面。 它需要连接到 AI 提供商以生成 embeddings,然后才能使用。
语义搜索功能对使用的搜索查询进行向量化,并使用向量 embeddings 而不是关键字来计算查询与抓取中的页面之间的余弦相似度。
它可以帮助量化抓取中所有页面的内容与查询的相关性,并且更类似于现代搜索引擎和 LLM 今天返回内容的方式,而不是更简单的关键字存在和文本中的匹配。
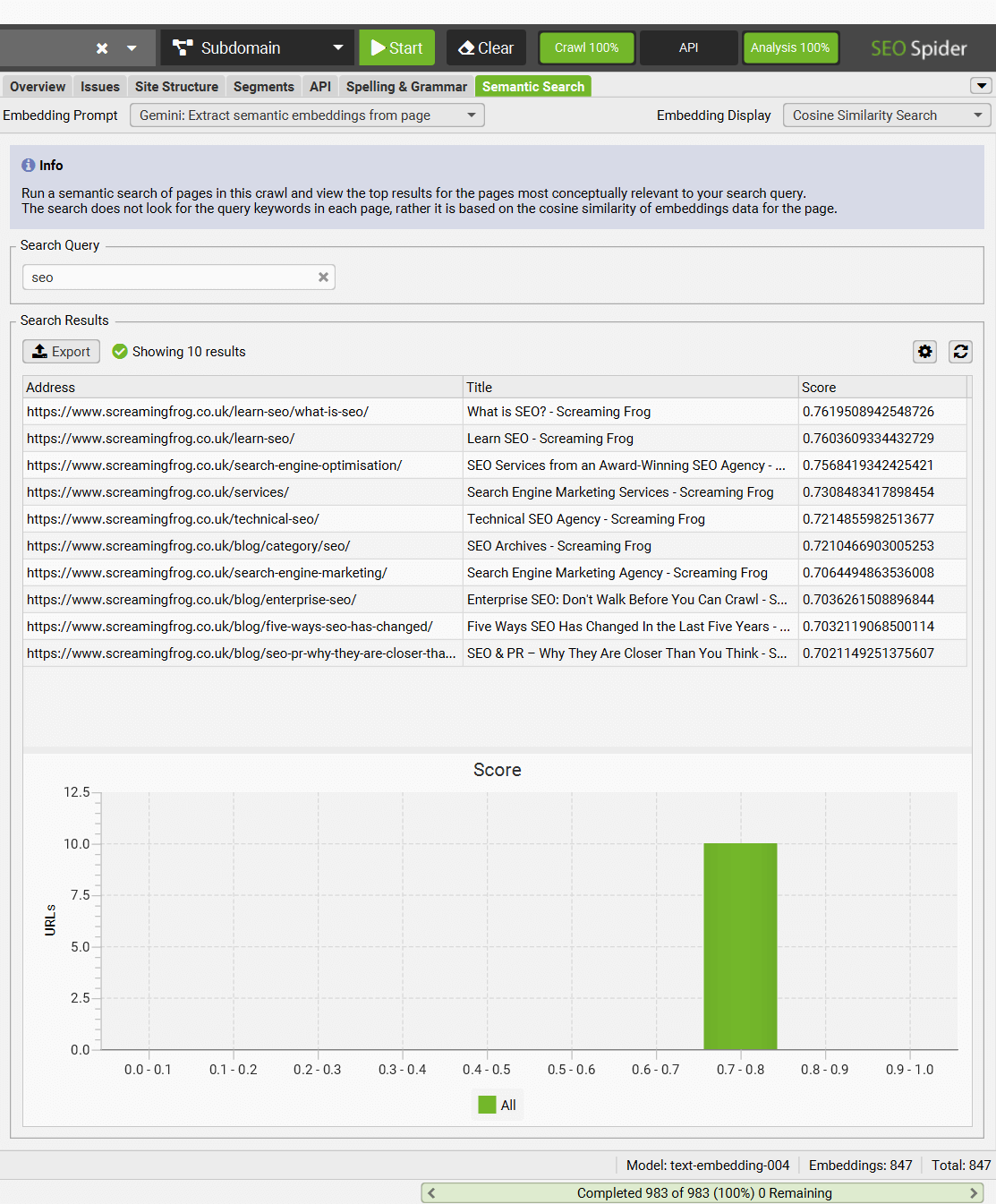
此功能可用于查找以下相关页面 –
- 关键词映射 – 识别查询最相关的页面,并优化页面以提高相关性。
- 内部链接 – 识别语义相似的页面以进行潜在的内部链接。
- 竞争对手分析 – 分析 SERP 中竞争对手针对给定查询的分数,以了解最相关的。
可以将“Embedding Display”过滤器调整为“Centroid”,以查看有关网站上发现的异常值以及“最具代表性的页面”(即最接近整个网站平均 embedding 的页面)的更多详细信息。
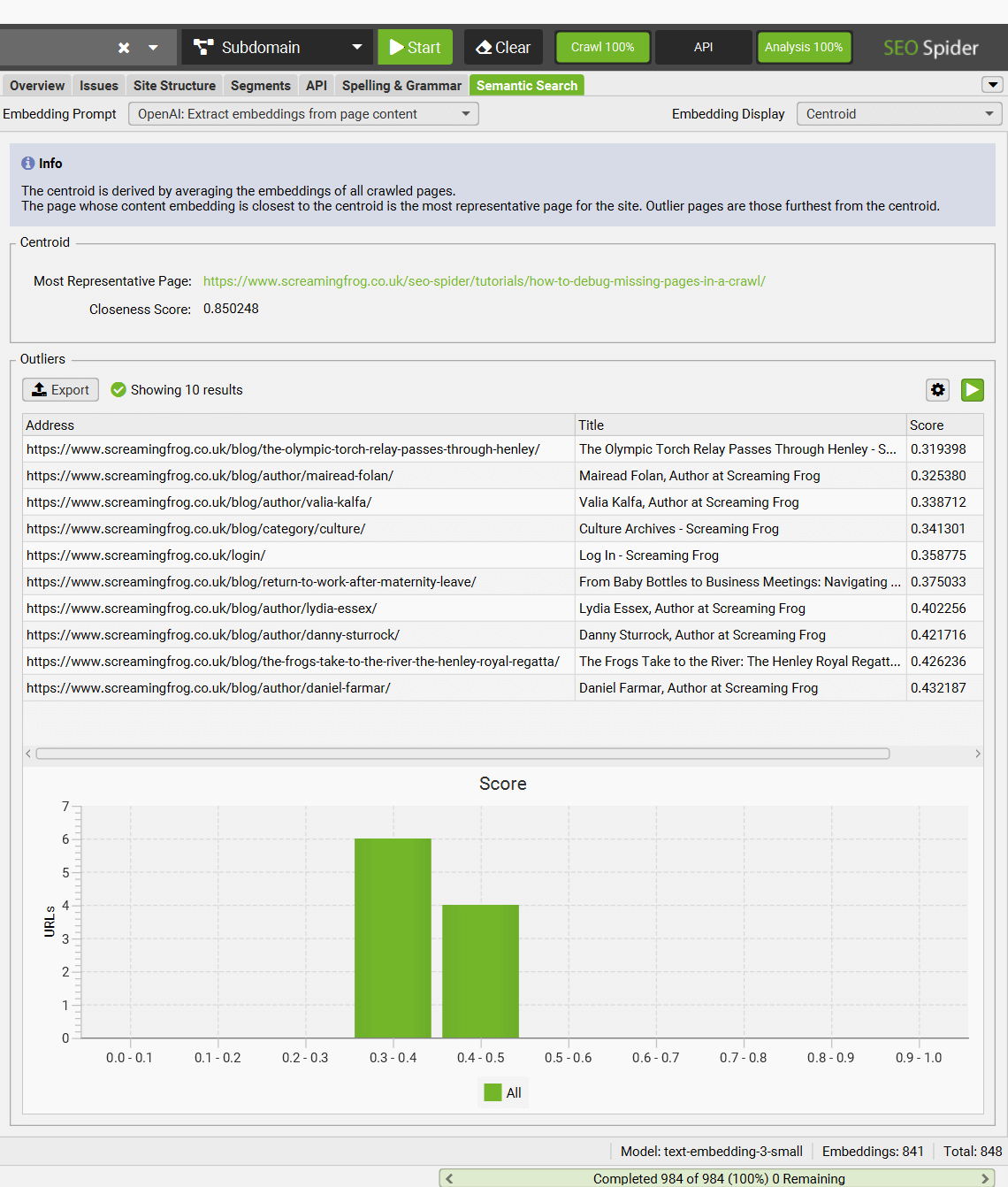
如果您从各种 LLM 中提取了 embeddings,您可以调整顶部的过滤器以查看不同的结果。