如何查找孤立页面
连接到 Google Analytics 和 Search Console,集成 XML 站点地图,并发现未从网站内部链接的孤立页面。
如何使用 SEO Spider 查找孤立页面
孤立页面是指无法通过从起始页抓取网站内部链接找到的页面。用户可能难以访问这些页面,这也使得搜索引擎更难发现它们。
孤立页面可能由于多种原因而出现,例如旧页面被取消链接但仍保持发布状态、站点架构问题、产品缺货但仍然存在、CMS 创建了作为其页面模板一部分的其他未知 URL 等。
在 SEO Spider 中,我们将从抓取的起始点(通常是主页)没有观察到链接路径的任何 URL 分类为孤立页面。孤立页面可以具有来自其他孤立页面的内部链接。
要发现孤立页面,需要额外的 URL 来源,这些来源来自 XML 站点地图以及 Google Analytics 和 Search Console API 的集成。
为什么它们很重要?
查找孤立页面很有用,因为它可以帮助识别站点中没有内部链接的区域或重要页面。 这显然对用户来说是一个问题,并且对搜索引擎发现和索引这些页面也是一个问题。
孤立页面可能仍然会被索引,因为它们在历史上或来自其他来源(例如 XML 站点地图或外部链接)被链接,但是没有任何内部链接,它们将不会传递内部 PageRank,这将影响它们在搜索引擎中的评分和自然搜索表现。
少量孤立页面是常见的,通常不是大问题,但是,大规模的孤立页面可能会导致索引膨胀和抓取预算浪费,它们可能会导致竞争页面,或者如果用户通过自然搜索发现过时的页面,则会导�致糟糕的体验。
本教程将引导您了解如何使用 Screaming Frog SEO Spider 从三个来源(XML 站点地图、Google Analytics 和 Search Console)查找孤立页面。 要抓取整个网站并打开配置以与这三个来源集成,需要 SEO Spider 许可证。
准备就绪后,只需按照以下教程中概述的步骤操作即可。
1) 在“Configuration > Spider > Crawl”下选择“Crawl Linked XML Sitemaps”
要抓取 XML 站点地图中的 URL,您可以选择通过 robots.txt 自动发现页面(这需要一个“Sitemap: https://www.example.com/sitemap.xml”条目),或者提供 XML 站点地图的目标地址。
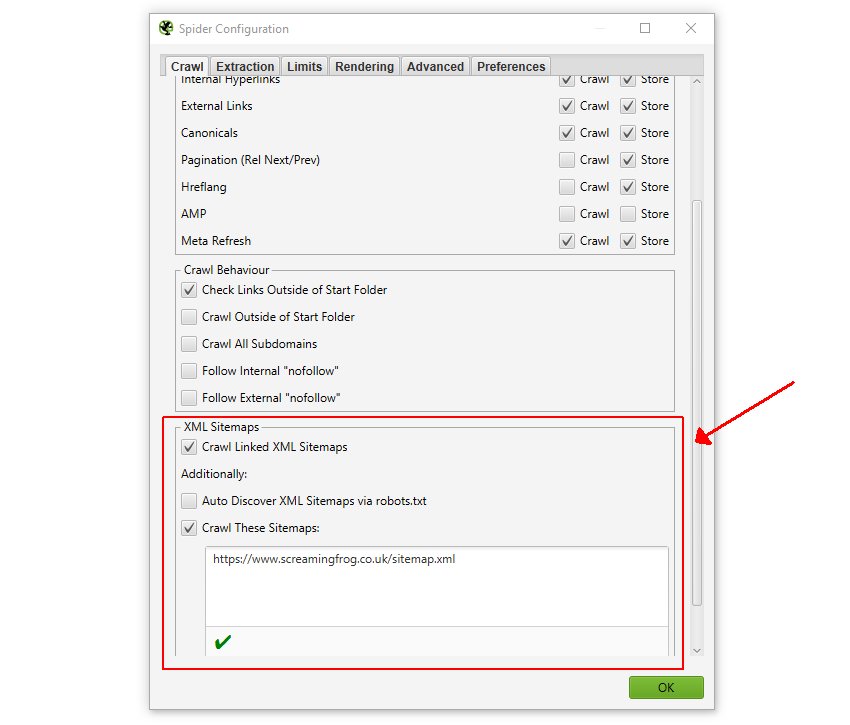
这意味着只会抓取通过 XML 站点地图发现的任何新的孤立 URL。
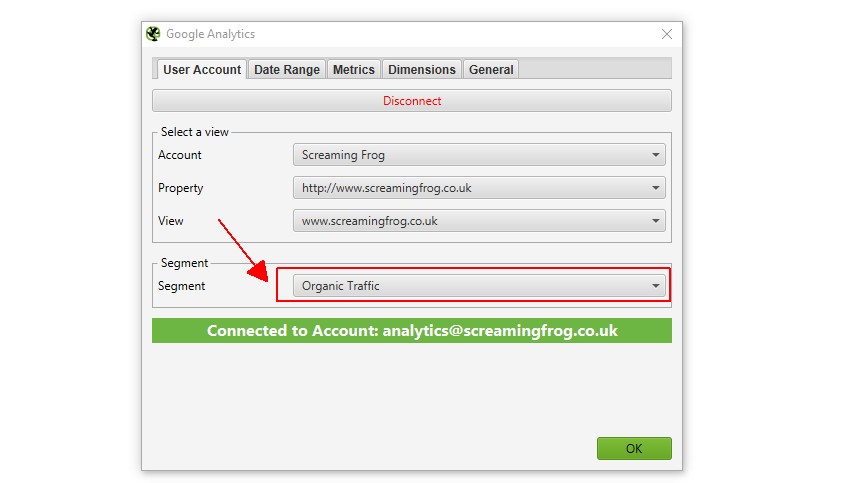
2) 在“Configuration > API Access”下连接到 Google Analytics
您可以连接到 Google Analytics API,并在抓取期间直接提取特定帐户、媒体资源、视图和细分的数据。 要从自然搜索中查找孤立页面,请记住选择“自然流量”细分。
您可以设置要分析的日期范围,理想情况下至少一个月,以及可以保留为默认值的指标和维度。 如果您有兴趣通过其他来源查找孤立页面,则可以将细分调整为“所有用户”或“付费流量”。
如果您之前没有连接到 GA,请阅读我们的 Google Analytics 集成 指南。
3) 选择“Crawl New URLs Discovered In Google Analytics”
此配置选项可以在 Google Analytics 配置窗口的“General”选项卡下找到(Configuration > API Access > Google Analytics)。
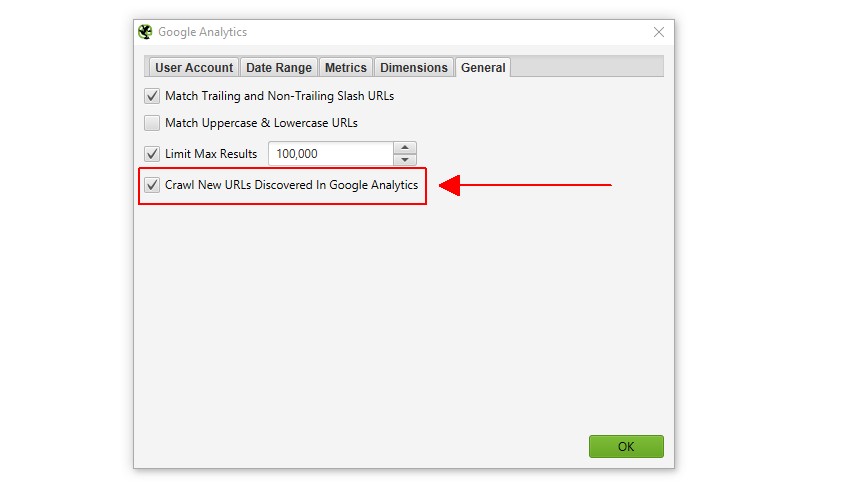
如果未启用此选项,则通过 Google Analytics 发现的新 URL 只能在“Orphan Pages”报告中查看。 它们不会��被添加到抓取队列中,无法在用户界面中查看,并且不会出现在相应的选项卡和过滤器下。
4) 在“Configuration > API Access”下连接到 Google Search Console
您可以连接到 Search Analytics API,并在抓取期间直接提取展示次数、点击次数、CTR 和排名指标等数据。 要查找在搜索下收到展示次数但未在内部链接的孤立页面,只需选择正确的媒体资源即可。
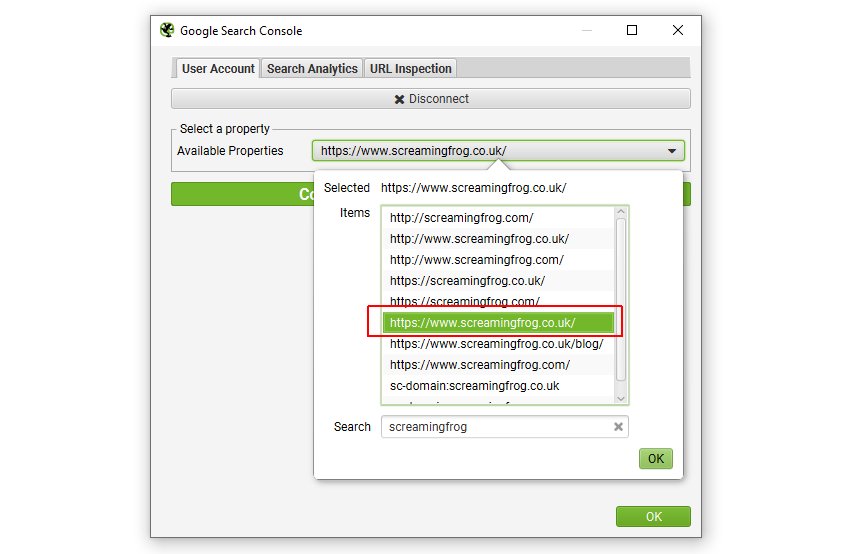
您可以设置要分析的数据的日期范围,理想情况下至少一个月,就像 Google Analytics 一样。
如果您之前没有连接到 GSC,请阅读我们的 Google Search Console 集成 指南。
5) 选择“Crawl New URLs Discovered In Google Search Console”
此配置选项可以在 Google Search Console 配置窗口的“Search Analytics”选项卡下找到(Configuration > API Access > Google Search Console)。
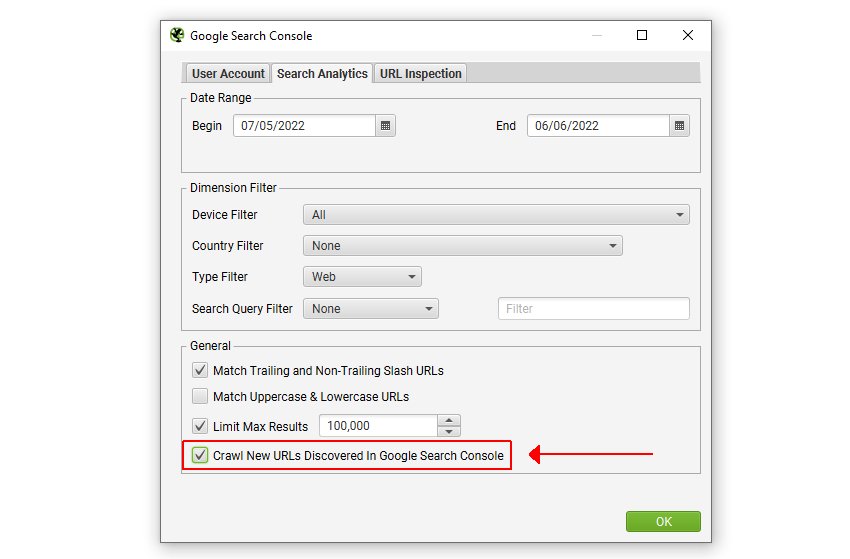
与 Google Analytics 相同,如果未启用此选项,则通过 Google Search Console 发现的新 URL 只能在“Orphan Pages”报告中查看。 它们不会被添加到抓取队列中,无法在用户界面中查看,并且不会出现在相应的选项卡和过滤器下。
6) 抓取网站
打开 SEO Spider,在“Enter URL to spider”框中键入或复制要抓取的网站,然后点击“Start”。
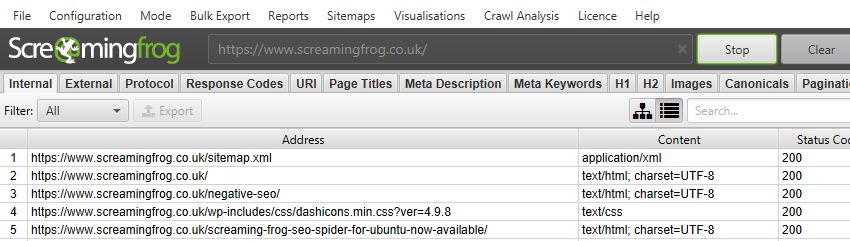
您可以通过进度条和 API 选项卡监控 API 和抓取的进度。
随后将抓取网站以及通过 XML 站点地图、Google Analytics 和 Search Console 发现的新 URL。 等待抓取完成并达到 100%。
7) 点击“Crawl Analysis > Start”以填充孤立 URL 过滤器
SEO Spider 中的大多数�过滤器都可以在抓取期间实时查看。 但是,在“Sitemaps”、“Analytics”和“Search Console”选项卡下有三个相应的“Orphan URLs”过滤器,只能在抓取结束时查看。
它们需要进行后“Crawl Analysis“才能填充数据(稍后会详细介绍)。 右侧的“overview”窗格针对需要进行抓取后分析才能填充数据的过滤器显示“(Crawl Analysis Required)”消息。 例如,“Sitemaps”下有五个过滤器需要进行抓取后分析。
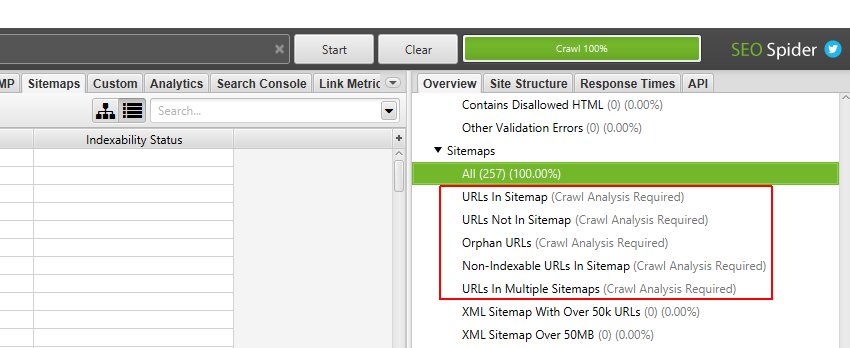
SEO Spider 只有在整个抓取完成后才知道哪些 URL 在 XML 站点地图中缺失,反之亦然。 要填充这三个孤立 URL 过滤器,您只需点击一个按钮。

但是,如果您之前配置了“Crawl Analysis”,您可能希望在“Crawl Analysis > Configure”下仔细检查是否勾选了“Sitemaps”、“Analytics”和“Search Console”。 您还可以取消勾选其他也需要进行抓取后分析的项目,以加快此步骤。
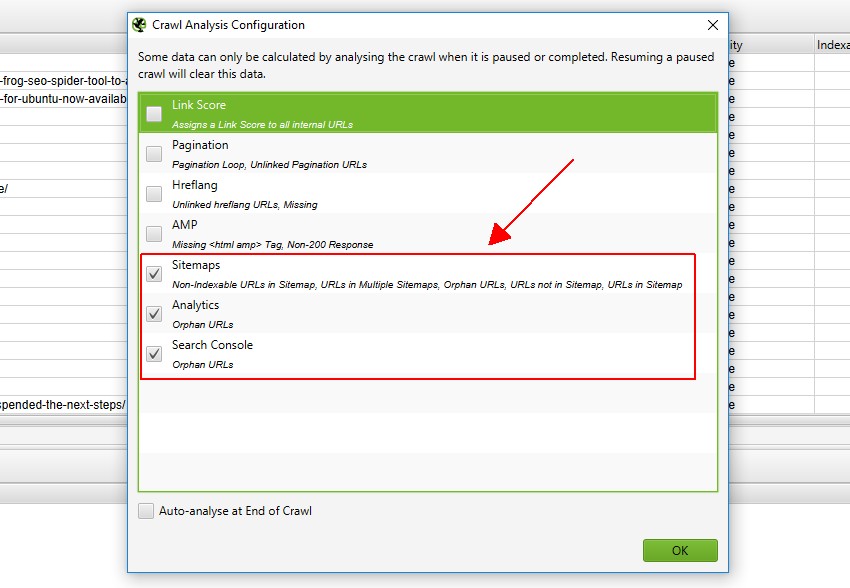
抓取分析完成后,“analysis”进度条将达到 100%,并且过滤器将不再显示“(Crawl Analysis Required)”消息。
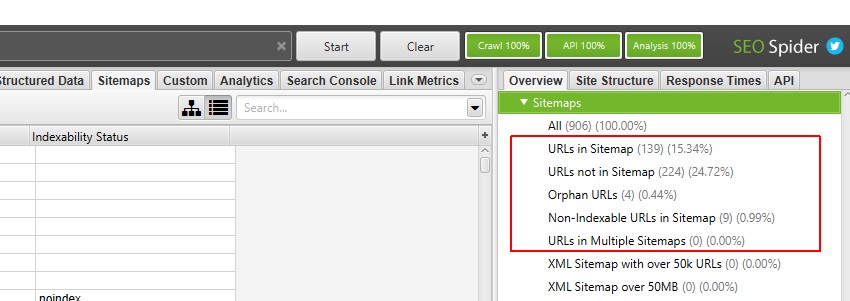
它们也将填充孤立 URL 数据!
8) 分析 Sitemaps、Analytics 和 Search Console 选项卡下的“Orphan URLs”过滤器
您现在可以浏览每个选项卡和相应的“Orphan URLs”过滤器以查看找到的孤立页面。 例如,在 Screaming Frog 网站上,有一些来自 XML 站点地图的孤立 URL 出现错误并重定向。

虽然这些不是存在的页面,但它们是在网站上未在内部链接的孤立 URL。 在此示例中,这些旧 URL 应该已从 XML 站点地图中删除。
孤立页面可以具有来自其他孤立页面的内部链接。
从 Search Console 数据来看,有一些页面存在于网站上并以 200 状态代码响应,但未在内部链接。 其中之一是一个指南,实际上应该在内部链接,而另一个是已从我们的招聘页面中删除的旧职位空缺,但仍然有效并收到自然展示次数和点击次数。

与上面的示例相同,也可以查看“Analytics”选项卡和“orphan URLs”过滤器。 可以通过界面上的“Export”按钮导出每个选�项卡和过滤器中的数据。
9) 通过“Reports > Orphan Pages”导出组合的孤立 URL
最后,如果您希望导出所有发现的孤立页面的组合列表,请使用“Orphan Pages”报告。
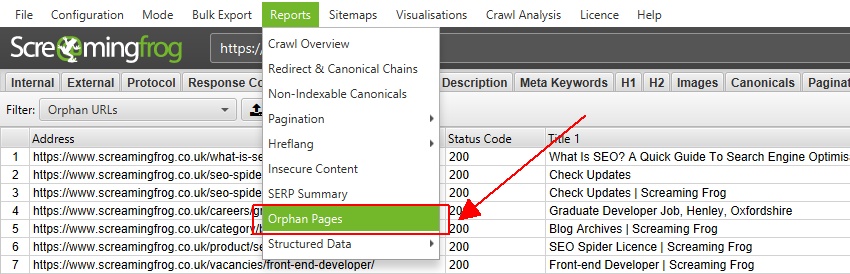
每个孤立 URL 旁边都有一个“Source”列,该列提供了发现的来源。 这些已缩写为 Google Analytics 的“GA”、Google Search Console 的“GSC”和 XML 站点地图的“Sitemaps”。
如果您在抓取中集成了 Google Analytics 和 Search Console,但未勾选“Crawl New URLs Discovered In GA/GSC”配置,则此报告仍将包含这些 URL 的数据。 它们只是没有被抓取,并且不会出现在相应的选项卡和过滤器下。
最后的提示! 通过空白抓取深度识别“Internal”选项卡中的孤立页面
“Internal”选项卡包含在抓取中找到的每个 URL,包括孤立 URL。 要识别哪些 URL 是孤立页面,请过滤空白“crawl depth”。
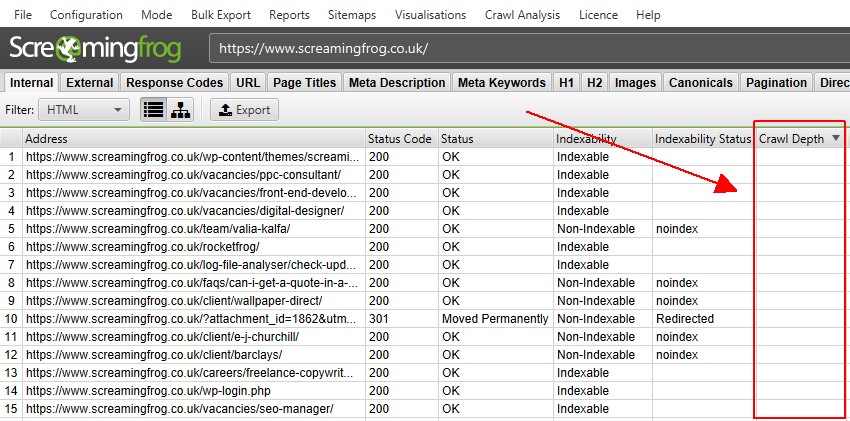
在抓取期间未通过内部链接自然发现的 URL 将没有“crawl depth”。
进一步支持
上面的指南应有助于说明使用 SEO Spider 查找孤立页面所需的简单步骤。
另请阅读我们的 Screaming Frog SEO Spider 常见问题解答 和完整的 用户指南,以获取有关该工具的更多信息。
如果您对上面概述的过程有任何其他疑问,请通过 support 与我们联系。