how-to-crawl-large-websites
如何使用 SEO Spider 抓取大型网站
抓取网站和收集数据是一个内存密集型过程,抓取的越多,存储和处理数据所需的内存就越多。Screaming Frog SEO Spider 使用可配置的混合引擎,需要进行一些调整才能进行大规模抓取。
默认情况下,SEO Spider 使用 RAM 而不是硬盘来存储和处理数据。这提供了惊人的好处,例如速度和灵活性,但它也存在缺点,最明显的是大规模抓取。
SEO Spider 还可以配置为将抓取数据保存到磁盘,方法是选择“数据库存储”模式(在“文件 > 设置 > 存储模式”下),这使其能够以真正前所未有的规模进行抓取,同时保留相同的、熟悉的实时报告和可用性。
 (滚动显示的800万页面标题)
(滚动显示的800万页面标题)
TL;DR 版本
如果您不想阅读下面的完整指南,以下是抓取非常大的网站的两个主要要求。
-
使用带有内部 SSD 的机器,并切换到数据库存储模式(“文件 > 设置 > 存储模式”)。
-
分配 RAM(“文件 > 设置 > 内存分配”)。对于最多约 200 万个 URL 的抓取,仅分配 4gb 的 RAM。分配 8gb 将允许抓取约 500 万个 URL。
避免过度分配 RAM,没有必要,它只会降低您的机器性能。
下面的指南提供了更全面的概述,介绍了内存和数据库存储之间的差异、抓取大型网站的理想设置以及如何智能地抓取以避免不必要地浪费时间和资源。
内存和数据库存储有什么区别?
从根本上讲,两种存储模式仍然可以提供几乎相同的抓取体验,允许实时报告、过滤和调整抓取。但是,存在一些关键差异,理想的存储将取决于抓取场景和机器规格。
内存存储
内存存储模式允许几乎所有设置进行超快速和灵活的抓取。但是,由于机器的 RAM 比硬盘空间少,这意味着 SEO Spider 通常更适合在内存存储模式下抓取 50 万个 URL 以下的网站。
用户可以使用正确的设置抓取更多内容,具体取决于正在抓取的网站的内存密集程度。作为一个非常粗略的指南,具有 8gb RAM 的 64 位机器通常允许您抓取几十万个 URL。
除了是较小网站的更好选择之外,还建议没有 SSD 或磁盘空间不足的机器使用内存存储模式。
数据库存储
我们建议将此作为具有 SSD 的用户的默认存储,并用于大规模抓取。数据库存储模式允许为给定的内存设置抓取更多 URL,对于具有固态驱动器 (SSD) 的设置,抓取速度接近 RAM 存储。
默认抓取限制为 500 万个 URL,但这不是硬性限制——SEO Spider 能够抓取更多(使用正确的设置)。例如,具有 500gb SSD 和 16gb RAM 的机器应该允许您大约抓取多达 1000 万个 URL。
在数据库存储模式下,抓取也会自动存储,因此无需手动“保存”它们。另一个主要好处是,在数据��库存储模式下重新打开存储的抓取比在内存存储模式下加载 .seospider 文件快得多。
可以通过“文件 > 抓取”顶级菜单访问和打开数据库抓取。
 (抓取菜单)
(抓取菜单)
“抓取”菜单显示存储的抓取的概述,允许您打开它们、重命名、组织到项目文件夹中、复制、导出或批量删除。
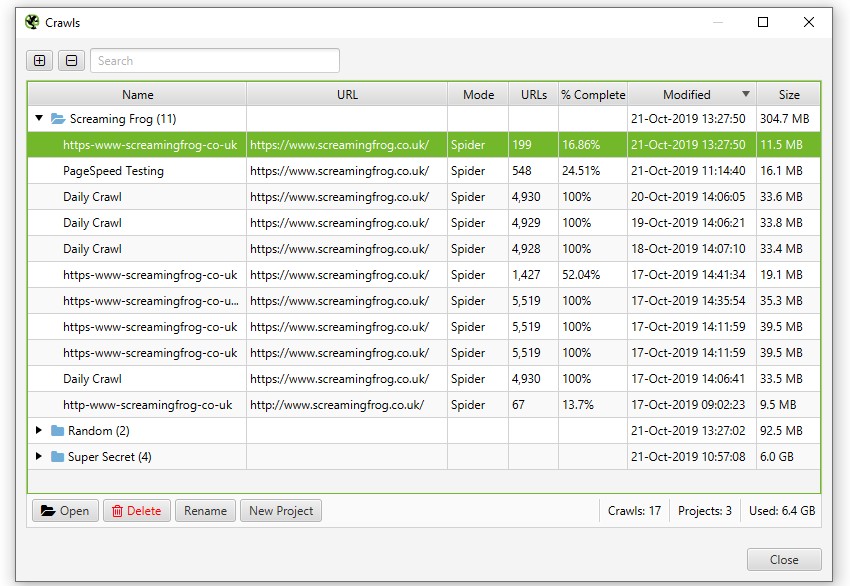 (抓取菜单详情)
(抓取菜单详情)
另一个好处是,由于抓取会自动存储,如果您确实遇到问题,例如 Windows 更新、断电或崩溃,仍然可以从“抓取”菜单中检索抓取以恢复。
虽然不推荐,但如果您有快速硬盘驱动器 (HDD),而不是固态磁盘 (SSD),那么此模式仍然允许您抓取更多 URL。但是,硬盘的写入和读取速度确实成为抓取的瓶颈——因此抓取速度和界面本身都会明显变慢。
如果您在抓取时正在使用机器,它也会影响机器性能,因此可能需要降低抓取速度以应对负载。SSD 非常快,它们通常没有这个问题,这就是为什么“数据库存储”可以用作小型和大型抓取的默认设置。
您真的需要抓取整个网站吗?
这是我们始终建议提出的问题。您是否需要抓取每个 URL 才能获得所需的�数据?
高级 SEO 人员知道通常不需要。通常网站是模板化的,并且从各个部分对页面类型进行样本抓取就足以对更广泛的网站做出明智的决策。
那么,当 5 万个 URL 足够时,为什么要抓取 500 万个 URL 呢?通过一些简单的调整,您可以避免在这些方面浪费资源和时间(稍后会详细介绍如何调整抓取)。
值得记住的是,抓取大型网站会占用资源,但也会占用大量时间(并且对于某些解决方案来说成本很高)。以平均每秒 5 个 URL 的抓取速度抓取一个 100 万页的网站将需要两天多的时间。您可以更快地抓取,但大多数网站和服务器都不希望以高于这种速度的速度进行抓取。
在考虑规模时,不仅需要考虑唯一的页面或收集的数据,还需要考虑网站的内部链接。SEO Spider 记录每个入站链接或出站链接(和资源),这意味着一个 10 万页的网站,每页有 100 个站点范围的链接,实际上意味着记录更像 1000 万个链接。
但是,话虽如此,有时完整的抓取是必不可少的。您可能需要完整地抓取一个大型网站,或者该网站可能处于企业级别,有 5000 万页,并且您需要抓取更多内容才能获得准确的样本。在这些情况下,我们建议采用以下方法来抓取更大的网站。
1) 切换到数据库存储
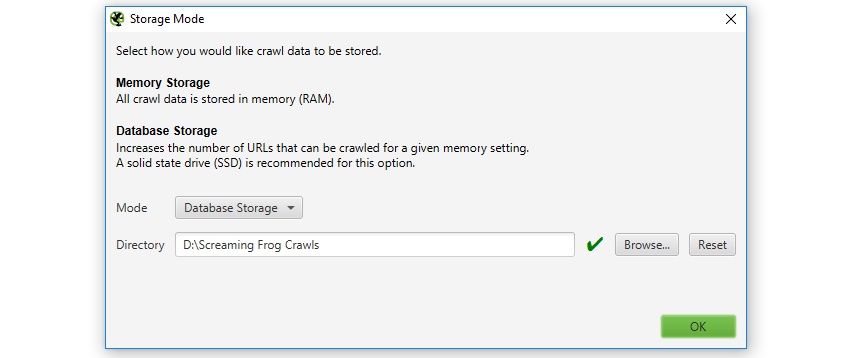
我们建议使用 SSD 并切换到数据库存储模式。如果您没有 SSD,我们强烈建议您投资。这是您可以对机器进行的单笔最大升级,投资相对较低,并且允许您以巨大的规模进行抓取,而不会影响性能。
用户可以通过在界面中选择“数据库存储模式”(�通过“文件 > 设置 > 存储模式”)来选择保存到磁盘。
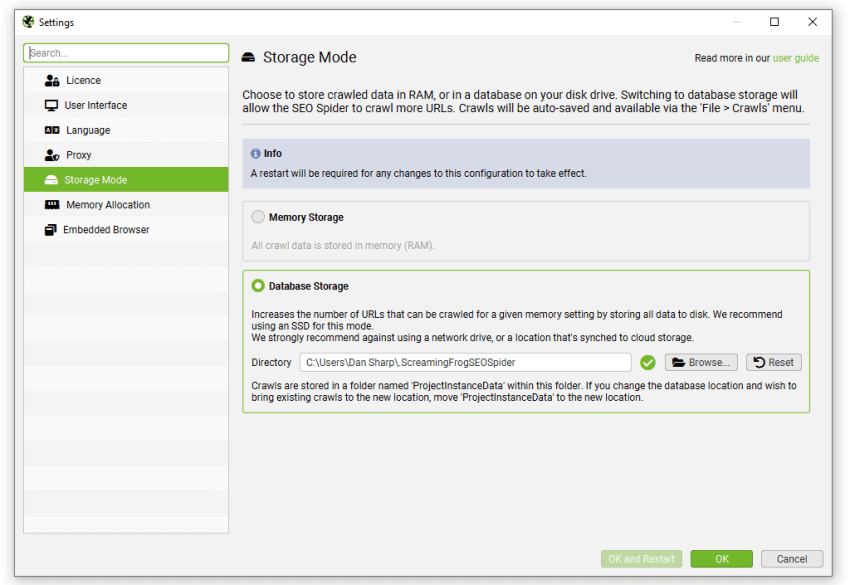 (数据库存储模式)
(数据库存储模式)
如果您没有 SSD(现在就买一个!),那么您可以忽略此步骤,只需按照本指南中的其余建议进行操作即可。值得注意的是,如果您的系统支持 UASP 模式,则可以使用带有 USB 3.0 的外部 SSD。
2) 增加内存分配
SEO Spider 作为标准,为 32 位机器分配 1gb 的 RAM,为 64 位机器分配 2gb 的 RAM。在内存存储模式下,这应该允许您抓取网站的 10-15 万个 URL。在数据库存储模式下,这应该允许您大约抓取 1-2 百万个 URL。
分配的 RAM 量将影响您可以在内存和数据库存储模式下抓取的 URL 数量,但在内存存储模式下影响更大。
对于 RAM 存储模式,我们通常建议至少 8gb 的 RAM 来抓取更大的网站,其中包含几十万页。但是,您拥有的 RAM 越多越好!
对于数据库存储,4gb 的 RAM 将允许您抓取 2-3 百万个 URL,8gb 的 RAM 将允许抓取多达 500 万个 URL,16gb 的 RAM 将允许抓取 1000 万个 URL。这些都是近似值,因为它取决于站点。
我们通常建议最初分配 4gb,因为 SEO Spider 会在使用您在内存中分配的量之前保存到磁盘。因此,如果您希望更早地保存到磁盘并保持 RAM 可用于其他应用程序和系统,请不要过度分配。
您可以通过单击“文件 > 设置 > 内�存分配”来调整 SEO Spider 中的内存分配。
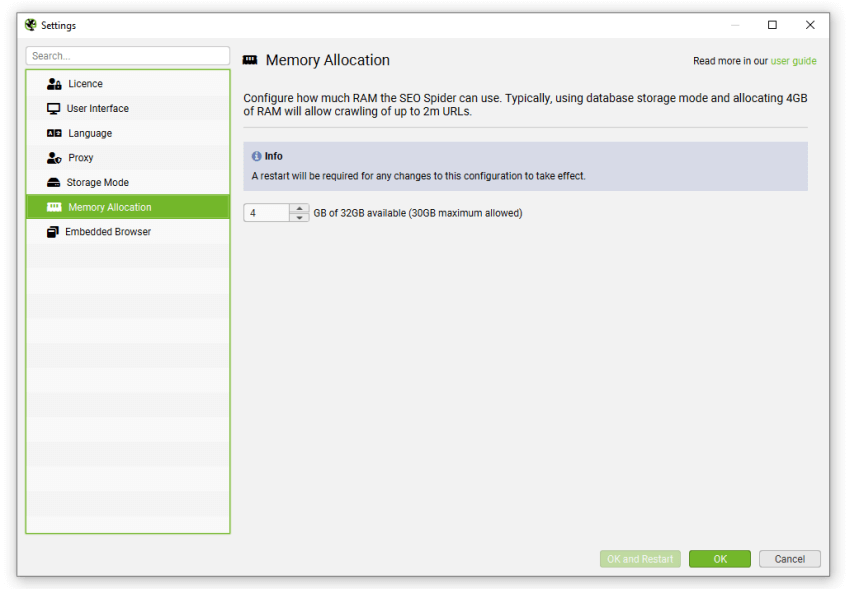 (内存分配)
(内存分配)
我们始终建议至少分配比您的可用总 RAM 少 2gb。如果您分配了您的总 RAM,您很可能会遇到崩溃,因为您的操作系统和其他应用程序也需要 RAM 才能运行。
SEO Spider 仅在需要时才使用内存,这仅意味着如果您需要它,您可以获得最大可用内存。
如果您没有调整内存并达到内存分配的限制,您将收到以下警告。
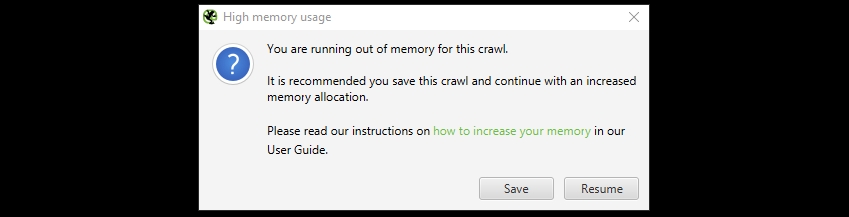 (SEO Spider 内存不足警告)
(SEO Spider 内存不足警告)
此警告您 SEO Spider 已达到当前内存分配,需要增加内存分配才能抓取更多 URL,否则它将变得不稳定。
要增加内存,首先您应该通过“文件 > 保存”菜单保存抓取。然后,您可以调整内存分配,然后打开保存的抓取,然后再次恢复抓取。
您可以分配的内存越多,您可以抓取的越多。因此,如果您没有具有大量可用 RAM 的机器,我们建议使用更强大的机器或升级 RAM 量。
3) 调整配置中要抓取的内容
收集的数据越多,抓取的内容越多,内存密集程度就越高。因此,您可以考虑减少内存消耗以进行“更轻”抓取的选项。
取消选择“配置 > Spider > 抓取”下的以下资源链接选项将有助于节省内存 -
请注意,如果您在 JavaScript 渲染 模式下进行抓取,您可能需要启用大多数这些选项,否则会影响渲染。请参阅我们的“如何抓取 JavaScript 网站”指南。
取消选择“配置 > Spider > 抓取”下的任何以下页面链接也将有助于节省内存 -
您可以取消选择“配置 > Spider > 提取”下未存储的非必要属性,以帮助节省内存,例如元关键字。或者只是您未审核的项目,例如结构化数据。
 (可配置的元素)
(可配置的元素)
我们还建议通过“配置 > 自定义 > 链接位置”禁用自定义链接位置功能。这会占用更多内存,通过存储在抓取中找到的每个链接的 XPath 来对其位置(导航、侧边栏、页脚等)进行分类。
 (禁用自定义链接位置)
(禁用自定义链接位置)
如果使用,还有其他选项会使用内存,因此请考虑不要使用以下功能 -
- 自定义搜索。
- 自定义提取。
- Google Analytics 集成。
- Google Search Console 集成。
- PageSpeed Insights 集成。
- 拼写和语法。
- 近似重复项。
- 链接指标集成(Majestic、Ahrefs 和 Moz)。
这意味着更少的数据、更少的抓取和更低的内存消耗。
4) 排除不必要的 URL
使用排除功能以避免抓取不必要的 URL。这些可能包括整个部分、分面导航过滤器、特定的 URL 参数或具有重复目录等的无限 URL。
排除功能允许您通过提供正则表达式 (regex) 列表从抓取中完全排除 URL。与排除匹配的 URL 根本不会被抓取(它不仅仅是界面中“隐藏”的)。同样值得记住的是,这意味着其他不匹配排除的 URL,但只能从排除的页面访问的 URL 也不会被抓取。因此,请谨慎使用排除。
我们建议执行抓取并按字母顺序在“内部”选项卡中�对 URL 进行排序,并实时分析它们以查找模式和潜在排除区域。通常,通过实时滚动列表并分析 URL,您可以整理出要排除的 URL 列表。
例如,电商网站通常具有分面导航,允许用户进行筛选和排序,这可能导致大量的 URL。有时它们会以不同的顺序被抓取,从而导致大量甚至无限数量的 URL。
让我们以 John Lewis 这样的真实场景为例。如果使用标准设置抓取该网站,由于其众多的分面,您可以轻松地抓取到经过筛选的页面,如下所示。
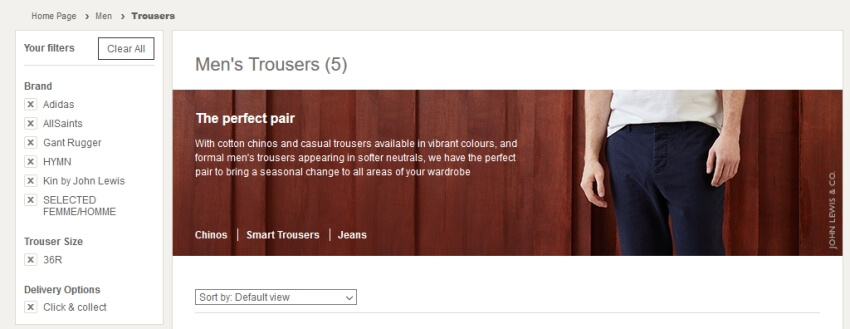
选择这些分面会生成如下 URL –
此 URL 选择了多个品牌、裤子尺寸和送货选项。还有颜色、裤型等分面!可以选择的不同组合数量几乎是无限的,应该考虑将其排除。
通过按字母顺序对“Internal(内部)”选项卡中的 URL 进行排序,可以很容易地发现这些 URL 模式,以便潜在地排除它们。我们还可以看到,John Lewis 上的分面中的 URL 无论如何都被设置为“noindex”。因此,我们可以简单地将它们排除在抓取范围之外。
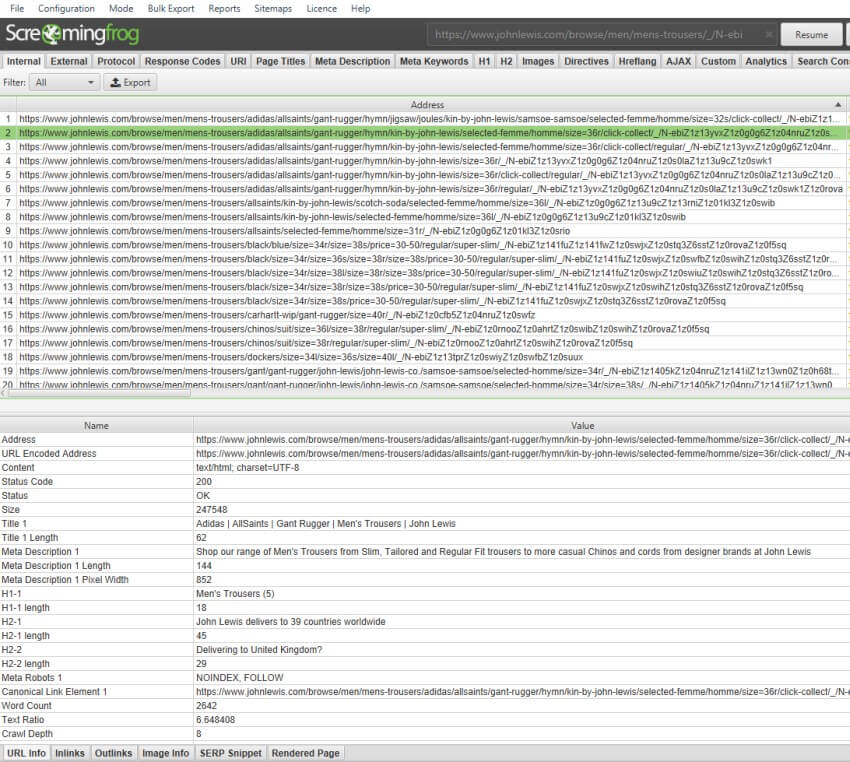
一旦您有了 URL 样本,并且已经确定了问题,通常就没有必�要再抓取每个分面和组合了。它们可能也已经被规范化、禁止或 noindex,因此您知道它们已经被“修复”了,并且可以简单地将它们排除在外。
5) 分区抓取(子域名或子目录)
如果网站非常大,您可以考虑分区抓取。默认情况下,SEO Spider 只会抓取输入的子域名,遇到的所有其他子域名都将被视为外部域名(并出现在“external(外部)”选项卡下)。您可以选择抓取所有子域名,但显然这会占用更多的内存。
SEO Spider 还可以通过简单地输入带有文件路径的子目录 URI,并确保在“Configuration(配置)> Spider(爬虫)”下取消选择“check links outside of start folder(检查起始文件夹之外的链接)”和“crawl outside of start folder(抓取起始文件夹之外的内容)”来配置为抓取子目录。例如,要抓取我们的博客,您只需输入 https://www.screamingfrog.co.uk/blog/ 并点击开始。
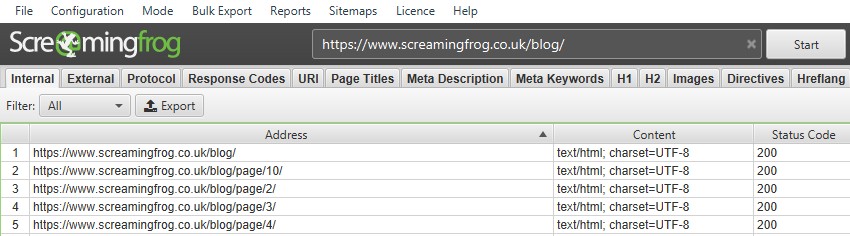
请注意,如果子目录的末尾没有尾部斜杠,例如“/blog”而不是“/blog/”,则 SEO Spider 目前不会将其识别为子文件夹并在其中抓取。如果子文件夹的尾部斜杠版本重定向到非尾部斜杠版本,则同样适用��。
要抓取此子文件夹,您需要使用 include feature(包含功能) 并输入该子文件夹的正则表达式(在本例中为 .*blog.*)。
6) 通过使用 Include 缩小抓取范围
您可以使用 include feature(包含功能) 通过正则表达式控制 SEO Spider 将抓取的 URL 路径。它通过仅抓取与正则表达式匹配的 URL 来缩小默认搜索范围,这对于较大的网站或 URL 结构不太直观的网站特别有用。
匹配是在 URL 的 URL 编码版本上执行的。您从中开始抓取的页面必须具有与此功能配合使用的正则表达式匹配的出站链接。显然,如果起始页面中没有与正则表达式匹配的 URL,则 SEO Spider 将不会抓取任何内容!
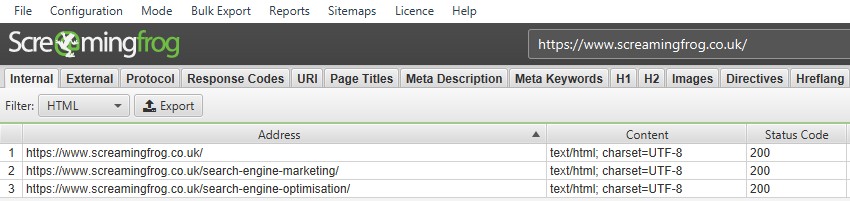
例如,如果您想从 https://www.screamingfrog.co.uk 中抓取 URL 字符串中包含“search”的页面,您只需在“include(包含)”功能中包含正则表达式:.*search.*。
这将找到 /search-engine-marketing/ 和 /search-engine-optimisation/ 页面,因为它们都包含“search”。
7) 限制抓取以获得更好的抽样
有各种限制可用,这些限制有助于控制 SEO Spider 的抓取,并允许您从整个网站获取页面样本,而无需抓取所有内容。这些包括 –
- Limit Crawl Total(限制抓取总数) – 限制抓取的总页数。浏览网站,大致估计抓取广泛的模板和页面类型可能需要多少。
- Limit Crawl Depth(限制抓取深度) – 将抓取深度限制为关键页面,允许足够的深度以获取所有模板的样本。
- Limit Max URI Length To Crawl(限制要抓取的最大 URI 长度) – 通过限制 URL 字符串的长度,避免抓取不正确的相对链接或非常深的 URL。
- Limit Max Folder Depth(限制最大文件夹深度) – 按文件夹深度限制抓取,这对于具有直观结构的网站可能更有用。
- Limit Number of Query Strings(限制查询字符串的数量) – 通过查询字符串的数量限制抓取大量分面和参数。通过将查询字符串限制设置为“1”,您可以允许 SEO Spider 抓取带有单个参数(例如 ?=colour)的 URL,但不能再多了。当可以将各种参数以不同的组合附加到 URL 时,这会很有帮助!
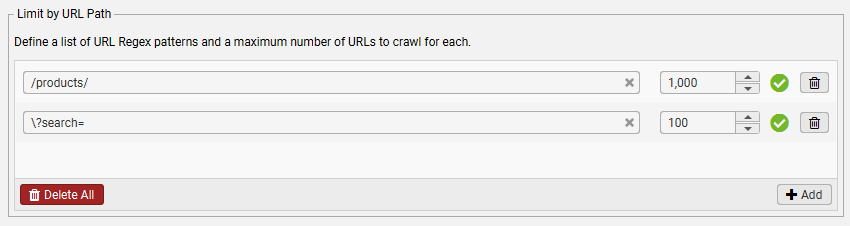
- Limit by URL Path(按 URL 路径限制) – 除了对整体抓取的限制之外,本节中的其他设置也适用,还可以限制与特定正则表达式匹配的 URL 总数。例如,在“Configuration(配置)> Spider(爬虫)> Limits(限制)> Limit by URL Path(按 URL 路径限制)”中使用“/products/”,限制 Spider 将抓取的包含“/products/”的 URL 总数。默认情况下,此值设置为 1,000,但可以调整。可以在本节中设置具有不同限制的多个规则。
8) 使用带有 USB 3.0(+) 的外部 SSD
如果您没有内部 SSD,并且想使用数据库存储模式抓取大型网站,那么外部 SSD 会有所帮助。
重要的是要确保您的机器具有 USB 3.0 端口,并且您的系统支持 UASP 模式。 如果您已经拥有 USB 3.0 硬件,则大多数新系统都会自动执行此操作。连接外部 SSD 时,请确保连接到 USB 3.0 端口,否则读取和写入速度会非常慢。
USB 3.0 端口通常�具有蓝色内部(如其规范中所建议的那样),但并非总是如此;您通常需要将蓝色端 USB 电缆连接到蓝色 USB 3.0 端口。之后,您需要切换到数据库存储模式,然后选择外部 SSD 上的数据库位置(在下面的示例中为“D”驱动器)。
简单!
9) 在云端使用带有 SSD 和大量 RAM 的 SEO Spider
如果您需要抓取更多内容,但没有带有 SSD 的强大机器,请考虑在云端运行 SEO Spider。只需确保它具有 SSD 和足够的 RAM。
请查看我们的教程 How to Run the Screaming Frog SEO Spider in the Cloud(如何在云端运行 Screaming Frog SEO Spider) 以获取分步说明。
还有一些用户编写的优秀指南 –
- How To Run Screaming Frog On Google Cloud(如何在 Google Cloud 上运行 Screaming Frog) – By Fili Weise
- How to Crawl Enterprise Sites in the Cloud with Screaming Frog�(如何在云端使用 Screaming Frog 抓取企业网站) – By Jordan Lowry
- How To Run Screaming Frog On AWS(如何在 AWS 上运行 Screaming Frog) – By Mike King
- Postavte si SEO stroj v Amazon Cloudu (AWS) – A Czech language guide, by Zdeněk Dvořák
10) 在内存存储中定期保存
如果您在内存存储模式下将 SEO Spider 推送到内存限制,我们建议定期保存抓取项目。如果出现问题,这意味着您不会丢失所有抓取。
您可以通过单击“Stop(停止)”,然后单击“File(文件)> Save(保存)”来保存抓取。抓取完成保存后,只需点击“resume(恢复)”即可再次继续抓取!
如果您使用的是推荐的数据库存储模式,则无需担心。抓取会自动存储,如果遇到问题,则抓取仍然可以在“File(文件)> Crawls(抓取)”下恢复。
11) 管理大型导出
SEO Spider 能够抓取数百万个 URI,虽然这对于处理大型网站的人来说很棒,但当您想要导出并深入研究数据时,可能会导致问题。
Microsoft Excel 的限制为 1,048,576 行乘以 16,384 列,如果文件(例如 .csv)超过此限制,则只会打开到该行数。
Google Sheets 的 单元格 限制为 10,000,000,虽然这听起来很多,但 SEO Spider 报告通常有很多列。例如,我们的默认 Internal(内部)选项卡导出包含 65 列,这意味着在 153,845 行数据后将达到 10,000,000 个单元格的限制。
因此,有时需要执行其他步骤才能使数据更易于管理。
拆分 CSV
第一种方法是最简单的,涉及将大型 CSV 拆分为更易于管理的部分。例如,如果您的 .csv 文件有 12,000,000 行,您可以简单地将其拆分为两个 6,000,00 行的文件。
有很多免费方法,快速 Google 搜索将返回多个网站,允许您上传 .csv 并以各种方式拆分它。但是,如果您需要定期拆分 .csv,则在您的机器上本地运行某些东西可能更有意义。
下面的 python 脚本非常基本,并使用 pandas 库:
import pandas as pd
import math
import warnings
# Specifically ignore the DtypeWarning
warnings.filterwarnings('ignore', category=pd.errors.DtypeWarning)
def count_rows(file_path):
""" Count the number of rows in the CSV file. """
with open(file_path, 'r', encoding='utf-8') as file:
row_count = sum(1 for row in file) - 1 # Subtract 1 for the header
return row_count
def split_csv(file_path, output_base_path, chunk_size):
""" Split the CSV file into multiple parts. """
reader = pd.read_csv(file_path, chunksize=chunk_size, iterator=True)
for i, chunk in enumerate(reader):
output_path = f'{output_base_path}_part{i+1}.csv'
header = True if i == 0 else False
chunk.to_csv(output_path, index=False, header=header)
print(f"CSV file has been split into {i+1} parts.")
if __name__ == "__main__":
file_path = 'C:\\path\\to\\your\\file.csv' # Replace with your file path
output_base_path = 'C:\\path\\to\\output\\split' # Replace with your output base path
total_rows = count_rows(file_path)
print(f"Total rows in file (excluding header): {total_rows}")
# Calculate the number of splits based on Excel's row limit
excel_row_limit = 1000000
num_splits = math.ceil(total_rows / excel_row_limit)
suggested_chunk_size = math.ceil(total_rows / num_splits)
print(f"Suggested number of rows per split file: {suggested_chunk_size}")
# Get user input
user_input = input("Enter number of rows per split file or press Enter to accept the suggestion: ")
chunk_size = int(user_input) if user_input.isdigit() else suggested_chunk_size
# Perform the split
split_csv(file_path, output_base_path, chunk_size)
此脚本执行以下几项操作:
- 首先,它计算 .csv 文件中的行数,因此您可以轻松地查看您正在处理的内容。
- 然后,它根据 Excel 的 1,048,576 行的上限,建议要创建的拆分文件数。
- 您可以选择使用建议的拆分,也可以输入所需的自定义行数。
- 然后,脚本将创建拆分文件,维护第一行标题(对于使用 SEO Spider 导出非常有用!)
注意:此脚本由 ChatGPT 编写,因此可能有点粗糙。
如果您不想拆分电子表格,则需要探索其他选项。这些包括:
- Power Query & Power Pivot
- Google BigQuery
- Gigasheet
- SQL Databases such as MySQL and PostgreSQL
祝您抓取愉快!
网站确实是独一无二的,但上面概述的基本原则应该可以使您更有效地抓取大型网站。
如果您对我们的抓取大型网站指南有任何疑问,请与我们的 support(支持) 团队联系。