如何审核 PDF(用于 SEO 和合规性!)
抓取、解析和审核 PDF,以查找常见问题和用例,例如断链或文档标题。
PDF 审核简介
Screaming Frog SEO Spider 能够抓取和解析 PDF,从而提取文档属性、内容和链接,用于 SEO 审核和一般合规性。
虽然 PDF 不是搜索引擎排名的理想格式,但它们通常用于政府、教育和企业环境中,以保证完整性、兼容性和一致性。
确保它们是最新的且没有错误至关重要。有时,需要针对搜索引擎或内部搜索系统对其进行优化。
PDF 由 Google 和 Bing 等搜索引擎抓取,并转换为 HTML 进行索引。PDF 中的内容和链接会被解析,在某些情况下,文档属性会被用于评分。
本教程解释了如何设置 SEO Spider 以审核常见问题和用例,例如 –
- 审核 PDF 中的链接,查找断链或其他错误。
- 提取和分析 PDF 属性。
- 审查内容,例如字数、可读性,并检查拼写和语法。
- 下载并保存 PDF。
- 批量提取和导出 PDF 内容。
请继续阅读,了解上述每个项目的详细信息。
审核 PDF 中的链接
可以以类似于常规 HTML 页面的方式发现和抓取 PDF 中的链接。但是,设置可能会略有不同,具体取决于您是抓取网站以查找 PDF,还是已经有一个 PDF URL 列表。
抓取网站
在常规的“Spider”模式下,如果 PDF 在内部链接到,则会被发现。然后将抓取它们,并且它们中的链接将被发现、抓取和报告。
只�需在顶部的 URL 栏中输入主页,然后单击“Start”。

在抓取过程中,任何链接到的 PDF 都将被发现,并显示在 Internal 选项卡和“PDF”过滤器下。
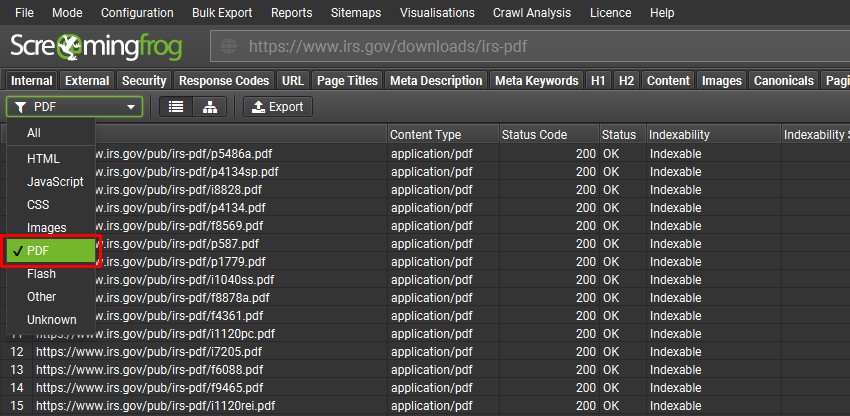
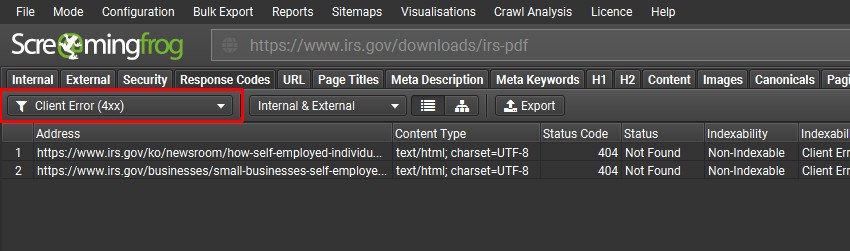
它们中的链接将被抓取,并且常见问题(例如断链)可以像往常一样在“Response Codes”选项卡和“Client Error (4xx)”过滤器下查看。
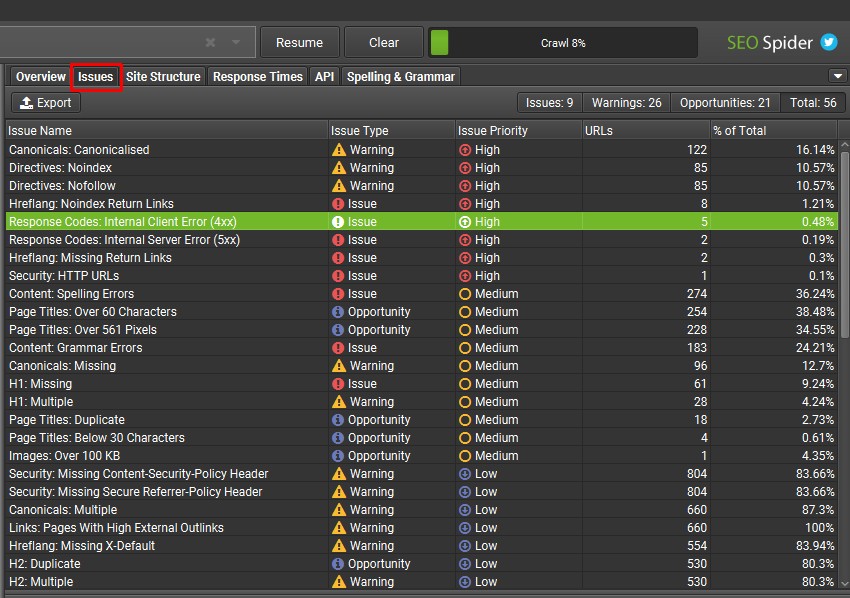
或者,使用“Issues“选项卡,其中问题、警告或机会会自动标记给您。
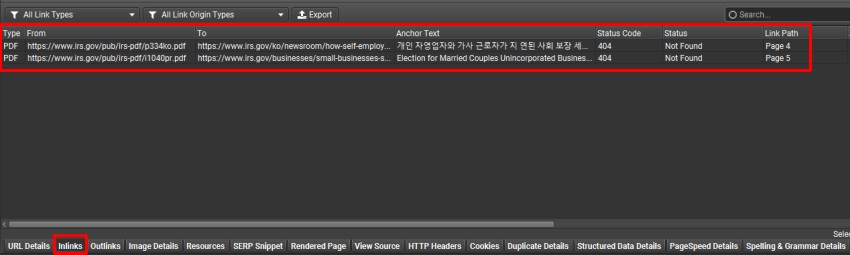
可以使用下方的“Inlinks”选项卡查看断链的来源。单击下面的图片放大。
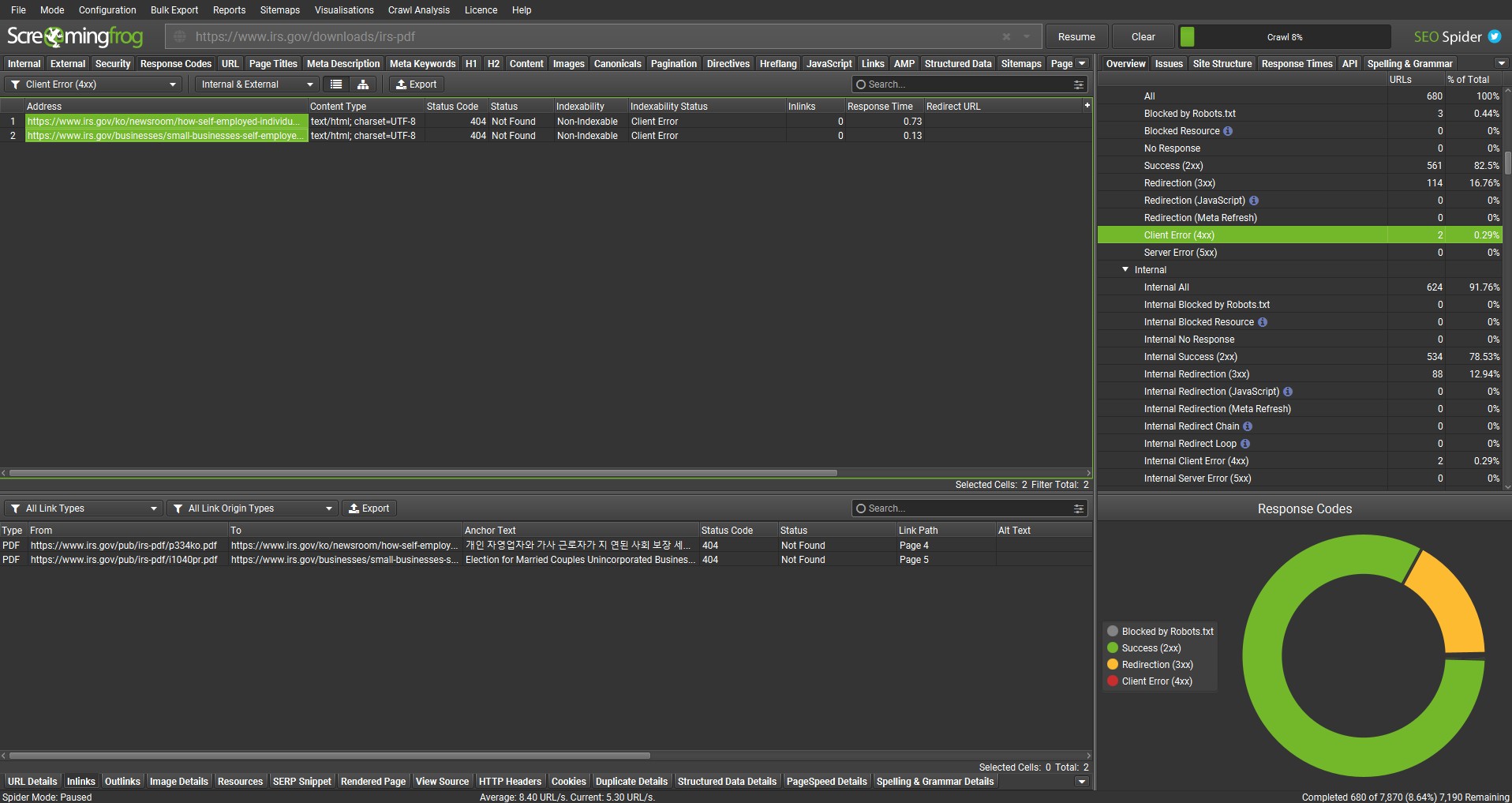
对于在 PDF 中发现的任何断链,“Inlinks”选项卡将显示“type”为 PDF,以及 PDF 的 URL、锚文本和发现它的页码。
可以通过“Bulk Export > Response Codes > Internal & External > Client Error (4xx) Inlinks”批量导出此数据。
阅读我们的教程如何在 SEO Spider 中查找断链以获取更多详细信息。
也可以突出显示“Internal”选项卡中的所有 PDF,然后单击下方的“Outlinks”选项卡以查看其中的链接。“Outlinks”选项卡将填充 PDF 中包含的链接的详细信息。
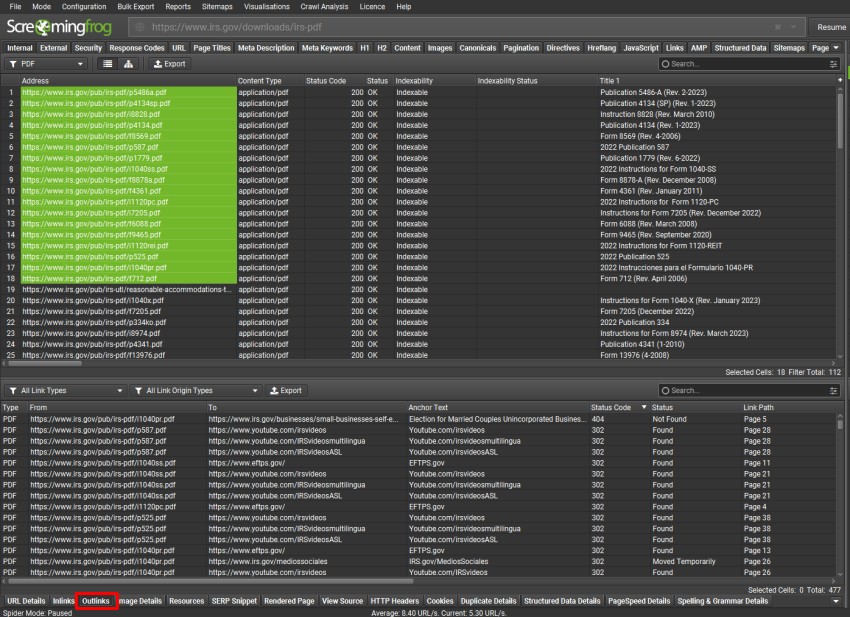
可以使用下方窗口窗格上的“Export”按钮导出数据,右键单击“Export > Outlinks”,或通过顶层菜单“Bulk Export”。
抓取 PDF 列表
您可以通过切换到列表模式(“Mode > List”)并粘贴它们(“Upload > Paste”)来上传 PDF URL 列表。

但是,这只会抓�取 PDF,而不会抓取 PDF 中的链接。
要抓取 PDF 中的外链,请在“Config > Spider > Limits”下将“Limit Crawl Depth”配置从“0”调整为“1”。
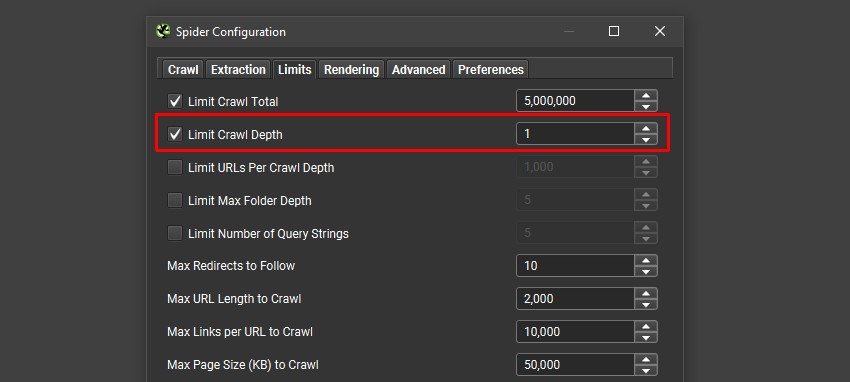
这意味着当您上传 PDF 列表时,不仅会抓取它们,还会抓取其中包含的外链。
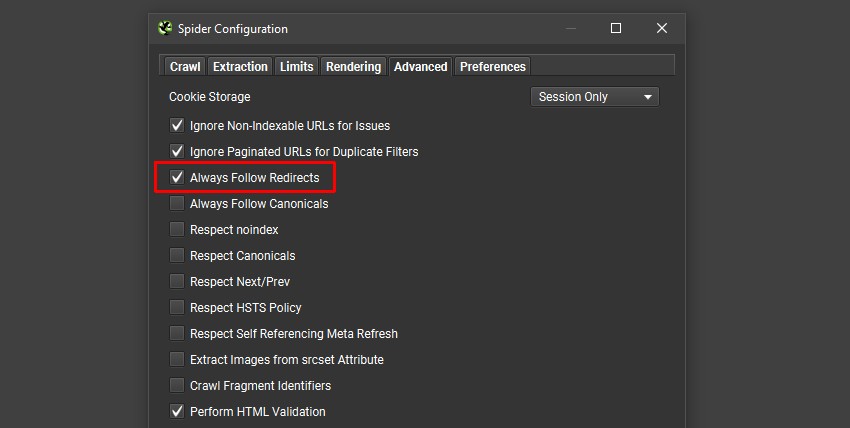
如果任何外链是重定向,您还可以通过在“Config > Spider > Advanced”下启用“Always Follow Redirects”来选择跟随重定向直到最终目的地。
提取 PDF 属性
您可以通过在 Chrome 中打开 PDF,然后单击右上角的“More Actions”按钮和“Document Properties”来查看 PDF 的文档属性。
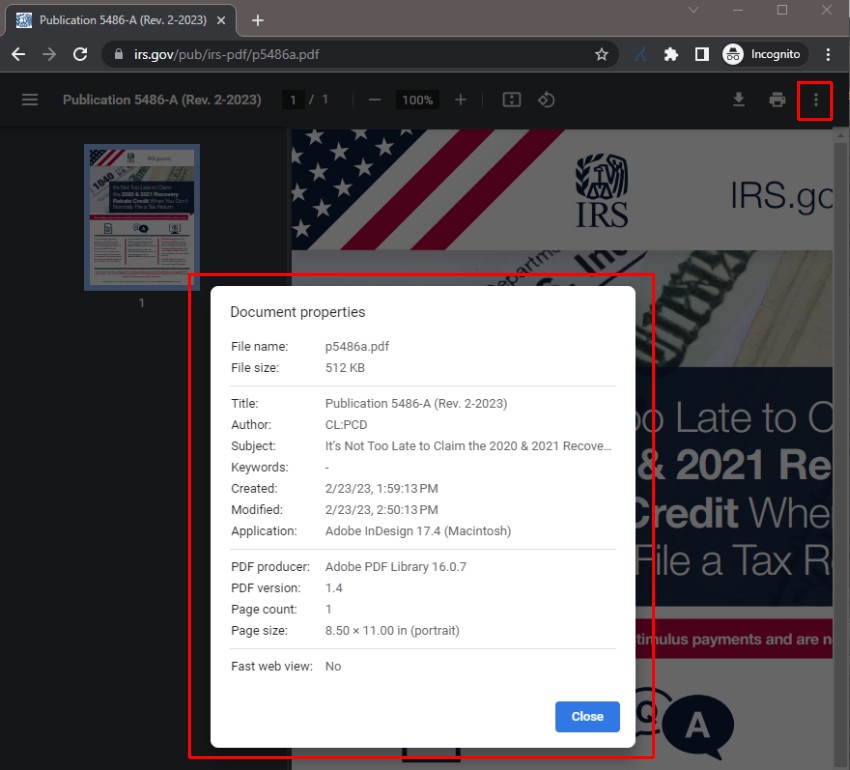
默认情况下,SEO Spider 将提取文档标题和关键字属性,并在“Internal”选项卡中的“Title”和“Meta Keywords”列中显示它们。
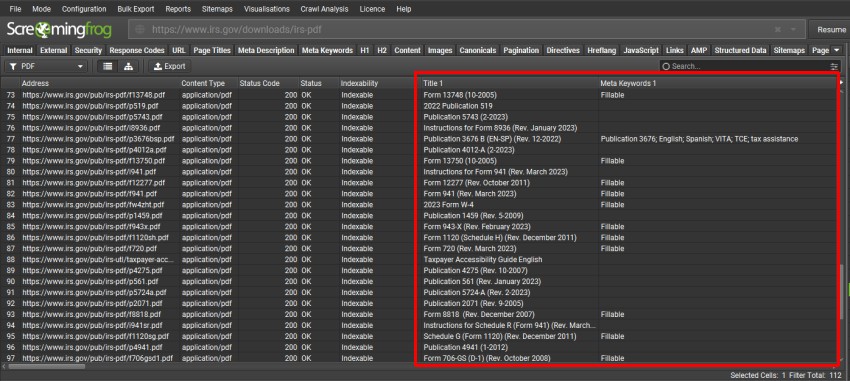
Google 会将 PDF 转换为 HTML,并将 PDF 文档标题用作标题元素,并将文档关键字用作 HTML 中的元关键字,尽管它实际上并不在网络结果排名中使用��元关键字。
页面标题用于评分,因此 PDF 文档标题必须是唯一的、相关的和描述性的——就像常规网页标题元素一样。
虽然 Google 会以类似于元关键字的方式忽略关键字属性,但 Bing 会将 PDF 的属性关键字解析为 HTML 表格,并在排名中使用它们——以及标题、作者、主题和创建日期。
可以通过在“Config > Spider > Extraction”下启用“Extract PDF properties“来提取其他属性。
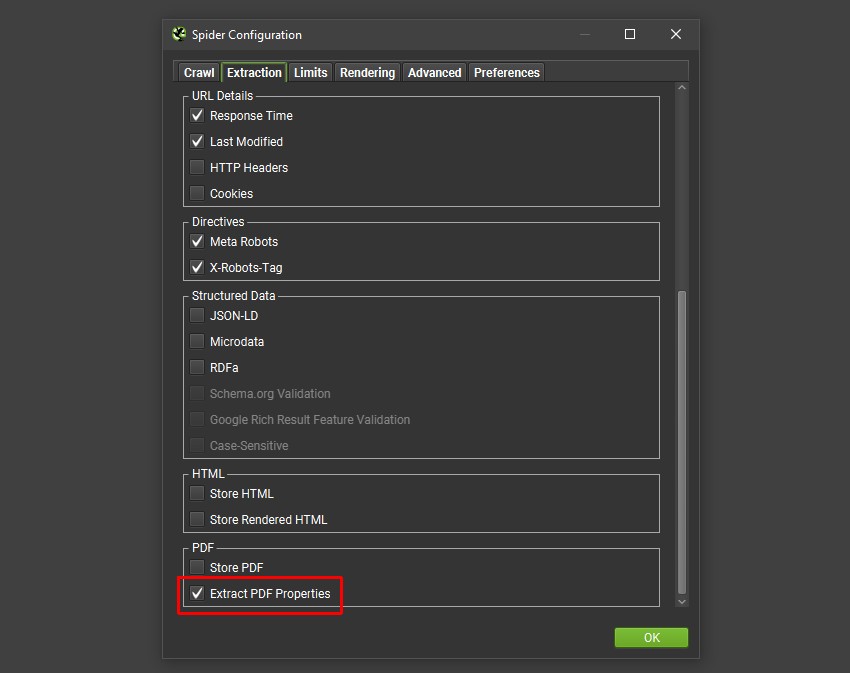
属性包括:
- 主题
- 作者
- 创建日期
- 修改日期
- 页数
选择后,新的列将显示在 Internal 中。
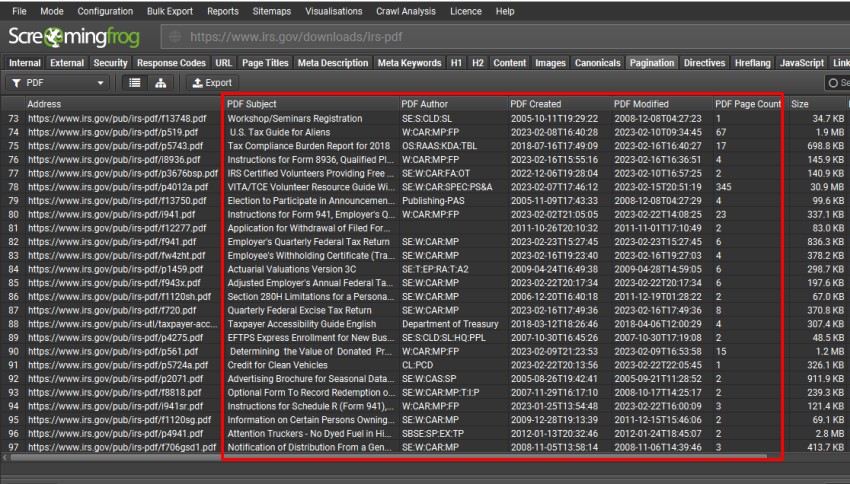
一些 SEO 指南表明搜索引擎使用“subject”文档属性作为 meta description。但是,没有证据表明 Google 在 HTML 中或在搜索中使用它。
Bing 可能会使用主题属性的内容作为元描述,因为它已解析为 HTML,并且将被视为页面上的任何文本。
审查 PDF 内容
在“Config > Spider > Extraction”下启用“Store PDF“意味着 PDF 的内容将被解析和存储,并且可以使用各种其他详细信息。
字数统计和可读性
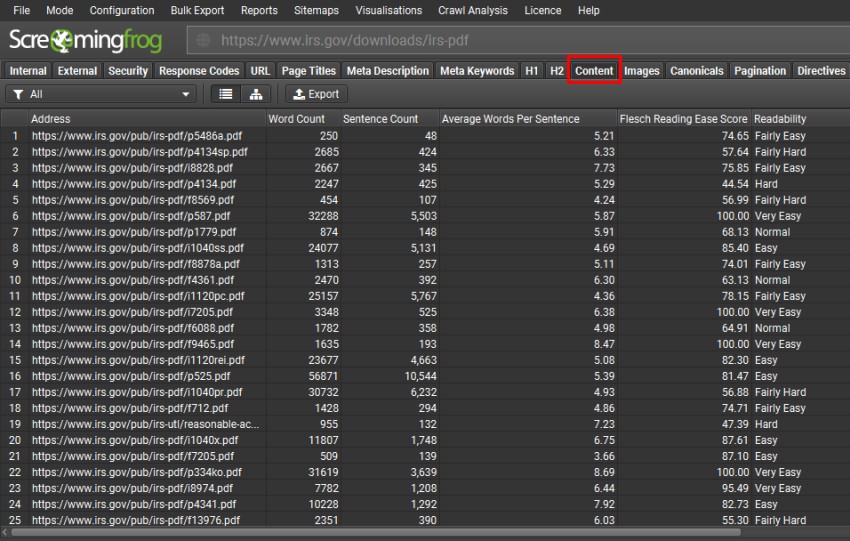
字数统计和可读性都将可用于 PDF,并且可以在 Content 选项卡中看到。
拼写和语法
与常规 HTML 网页一样,也可以检查 PDF 的拼写和语法。
要启用此功能,请单击“Config > Content > Spelling & Grammar”并启用“Spell Check”和“Grammar Check”。
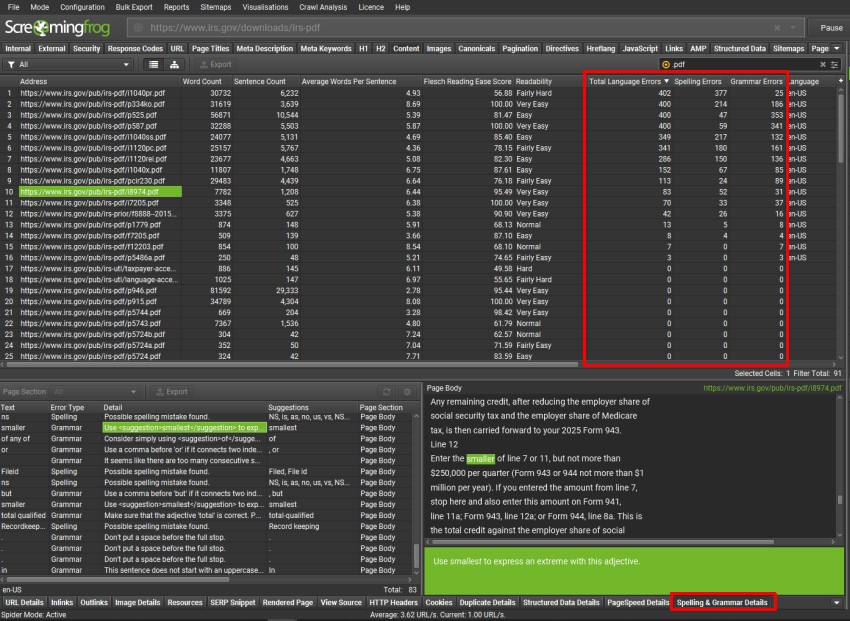
然后,拼写和语法错误的详细信息将显示在“Content”选项卡中,如我们的教程“Spell & Grammar Check Your Website“中所述。
自定义搜索
由于 SEO Spider 能够看到 PDF 中的内容,因此自定义搜索适用于 PDF。这意味着您可以搜索 PDF 和网页中的任何文本,例如旧品牌名称或电话号码。
确保在“Config > Spider > Extraction”下启用“Store PDF”,然后设置自定义搜索。
单击“Config > Custom > Search”,输入您要查找的文本,然后选择“Page Text”。在“Custom Search”选项卡下查找包含文本的页面的详细信息。
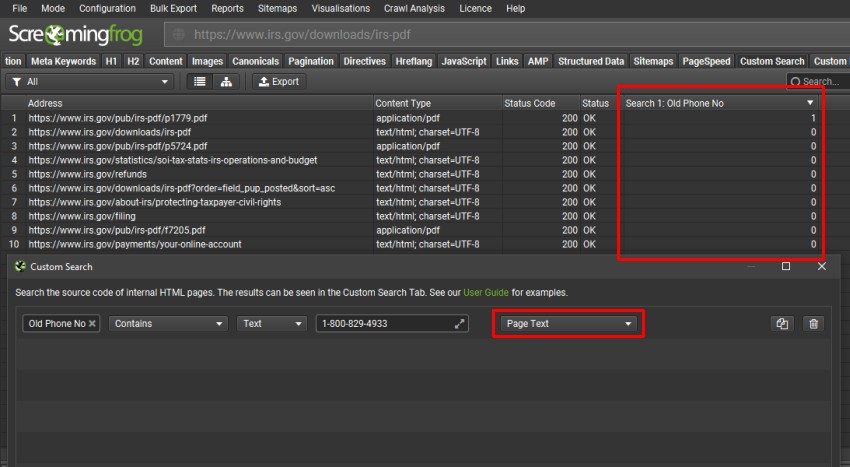
在上面,顶部的 PDF 包含电话号码的“1”个匹配项。
批量保存 PDF
要在抓取时保存 PDF 副本,请在“Config > Spider > Extraction”下启用“Store PDF“,然后使用“Bulk Export > Web > All PDF Documents”导出。
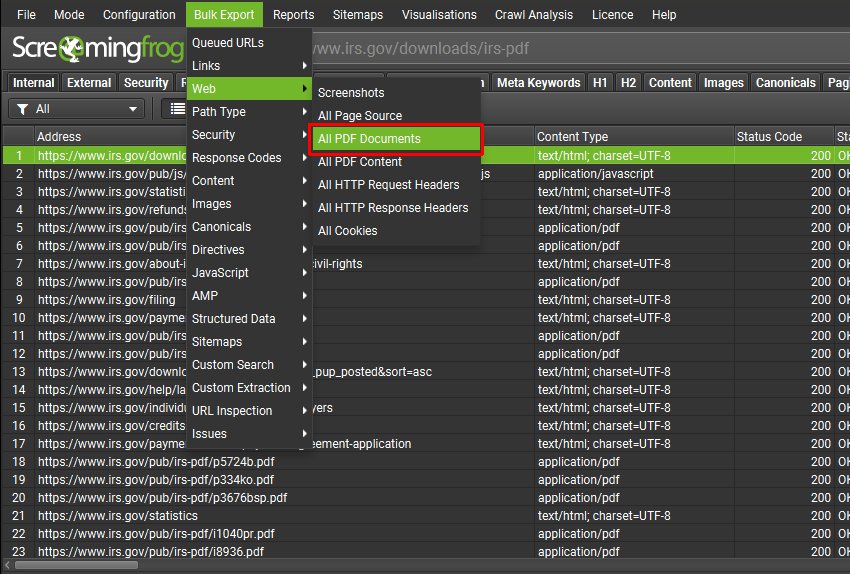
这会将发现和抓取的每个 PDF 文件保存到您选择的文件夹中。
批量导出 PDF 内容
SEO Spider 允许您将 PDF 的原始文本内容导出为 .txt 文件。
在“Config > Spider > Extraction”下启用“Store PDF“,然后单击“Bulk Export > Web > All PDF Content”。
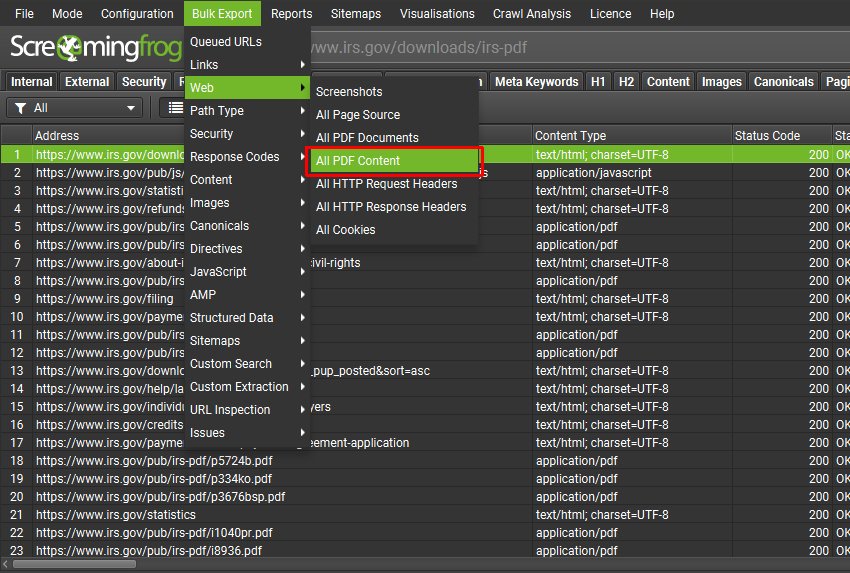
这会将每个 PDF 的内容导出到所选位置的单独文本文件中。
总结
上面的指南应说明如何在审核 PDF 时使用 SEO Spider,无论是针对常见的 SEO 相关问题、常规网站维护还是合规性。
请参阅我们的用户指南、教程和 FAQ,了解有关该工具的更多信息。
如果您有任何其他疑问、反馈或改进 SEO Spider 中拼写检查器工具的建议,请通过支持与我们的团队联系。