如何识别语义相似的页面和异常值
分析爬取页面中的语义相似性,以帮助识别重复内容并检测网站上潜在的离题、相关性较低的内容。
介绍
SEO Spider 允许您分析爬取页面中的语义相似性,以帮助识别重复内容并检测网站上潜在的离题、相关性较低的内容。
此功能超越了匹配文本(如在我们的重复内容检测中所见),它利用 LLM 嵌入来理解页面上单词的潜在概念和含义。
利用向量嵌入可以:
- 识别重复和相似内容 – 查找主题可能重叠、多次涵盖相同主题、导致内容蚕食或仅导致爬取和索引效率低下的完全和近似重复页面。
- 检测离题的低相关性内容 – 发现偏离网站平均内容主题或重点的页面。
- 可视化内容集群 – 查看网站内容中的模式和关系,其中语义相似的内容被聚集在一起,而异常值被隔离。
这些功能需要该软件的付费许可证。
本教程将引导您完成如何连接到 AI 提供商以获取向量嵌入、启用语义相似性分析以及查找语义相似页面和低相关性内容。
1) 选择用于嵌入的 AI 提供商
要执行语义内容分析,您需要连接到 AI 提供商 API 以生成爬取页面内容的向量嵌入。
通过“Config > API Access > AI”从 OpenAI、Gemini 和 Ollama 中进行选择。
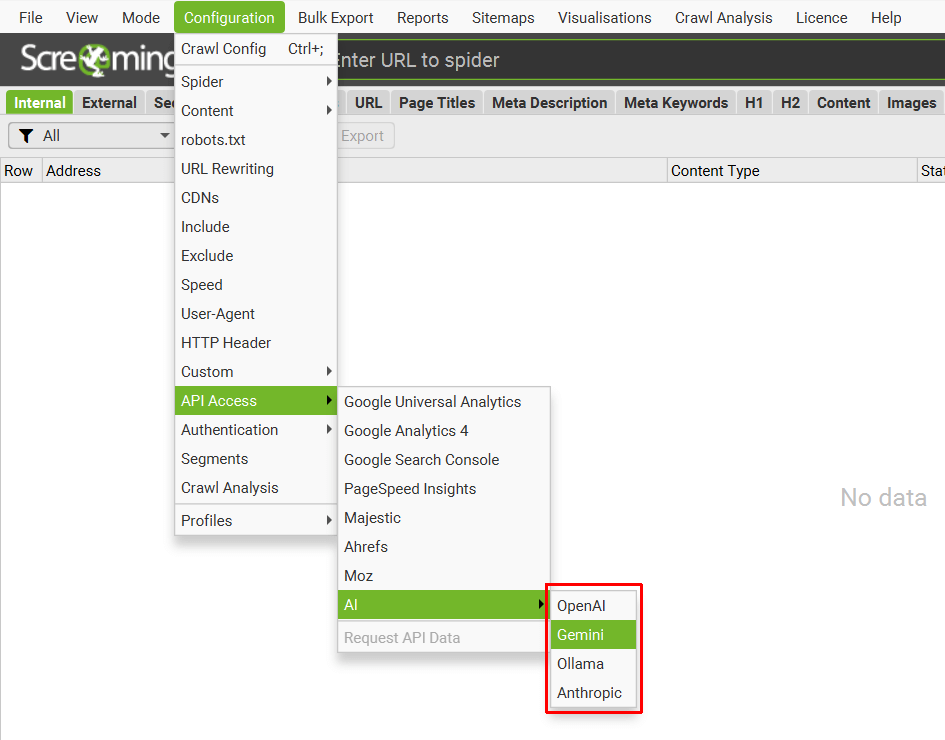
确保您已按照上述指南中的概述设置帐户并拥有 API 密钥。
2) 从库中添加嵌入提示
选择 AI 提供商后,导航到“Prompt Configuration”,选择“Add from Library”并选择相关的嵌入预设。
建议使用 Gemini 嵌入和 API,并在我们的示例中使用。 对于 Gemini,选择“Extract Semantic Embeddings from Page”,它将被添加为提示。
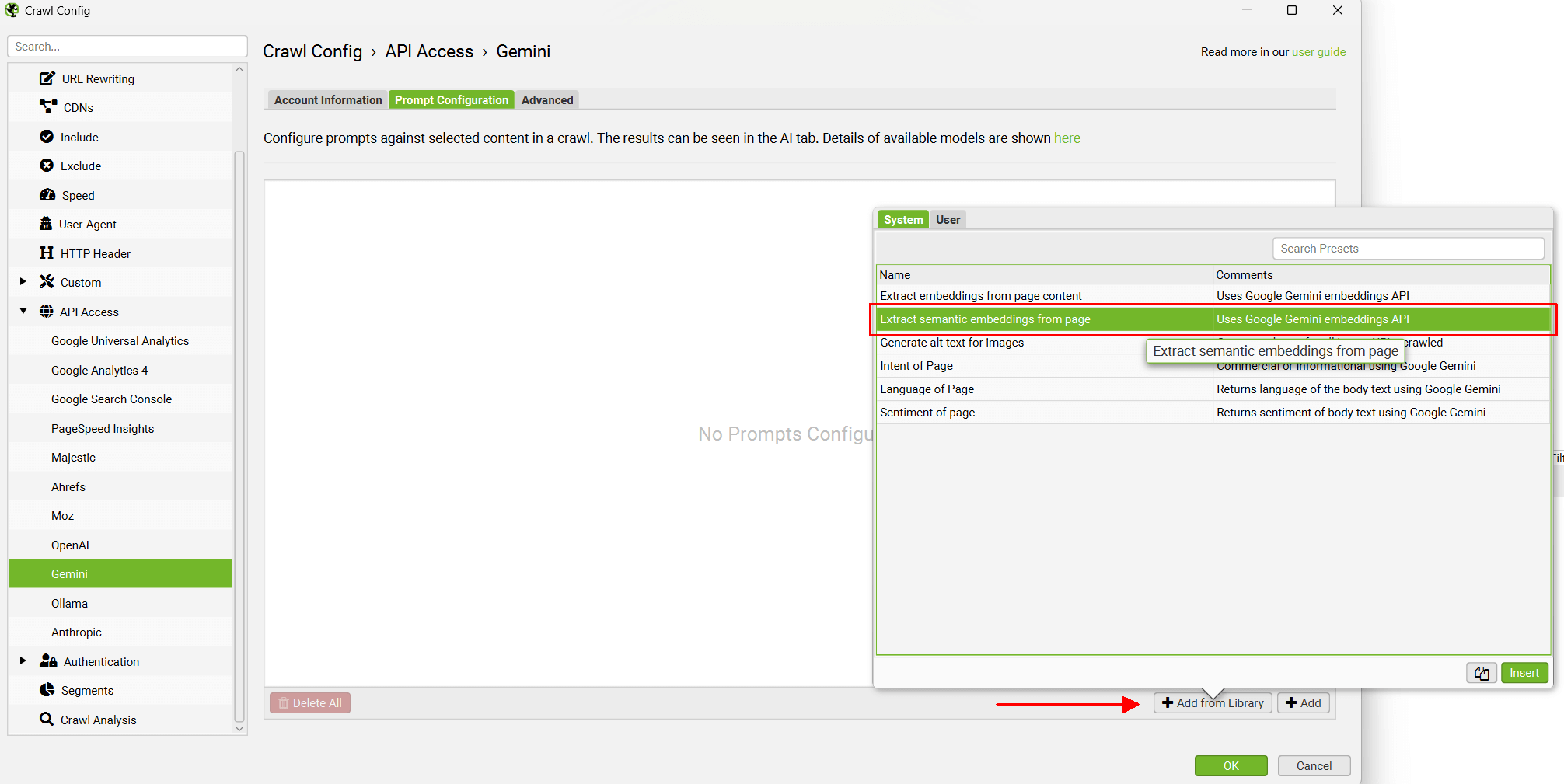
“Extract Semantic Embeddings from Page”提示专门使用 ‘SEMANTIC_SIMILARITY’ 任务类型,这适合此分析。
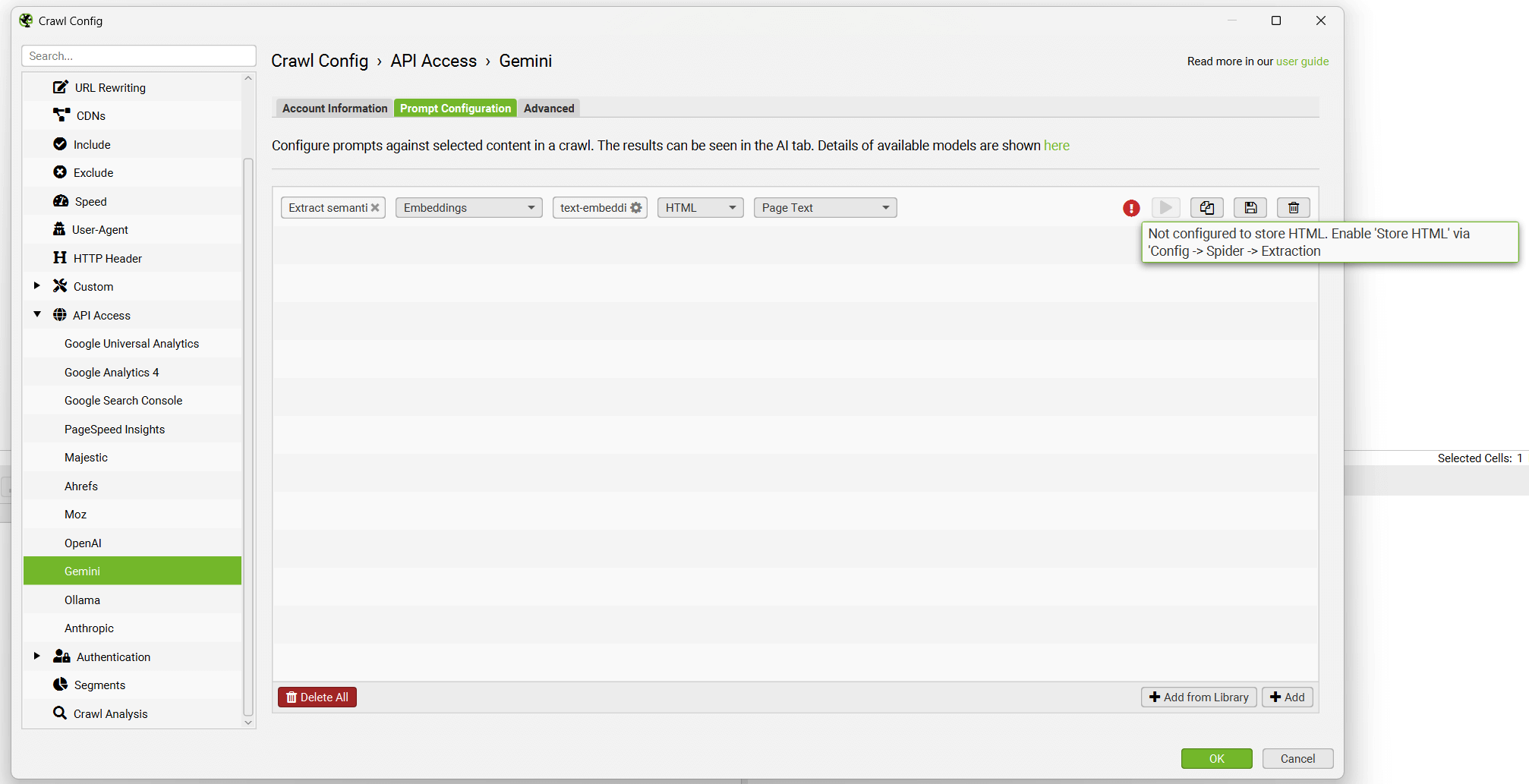
将显示提示,并显示一条错误消息,指出还必须配置“Store HTML”。 稍后会详细介绍。
3) 连接到 API
在启用“Store HTML”设置之前,请记住在“Account Information”下“Connect”到 API。
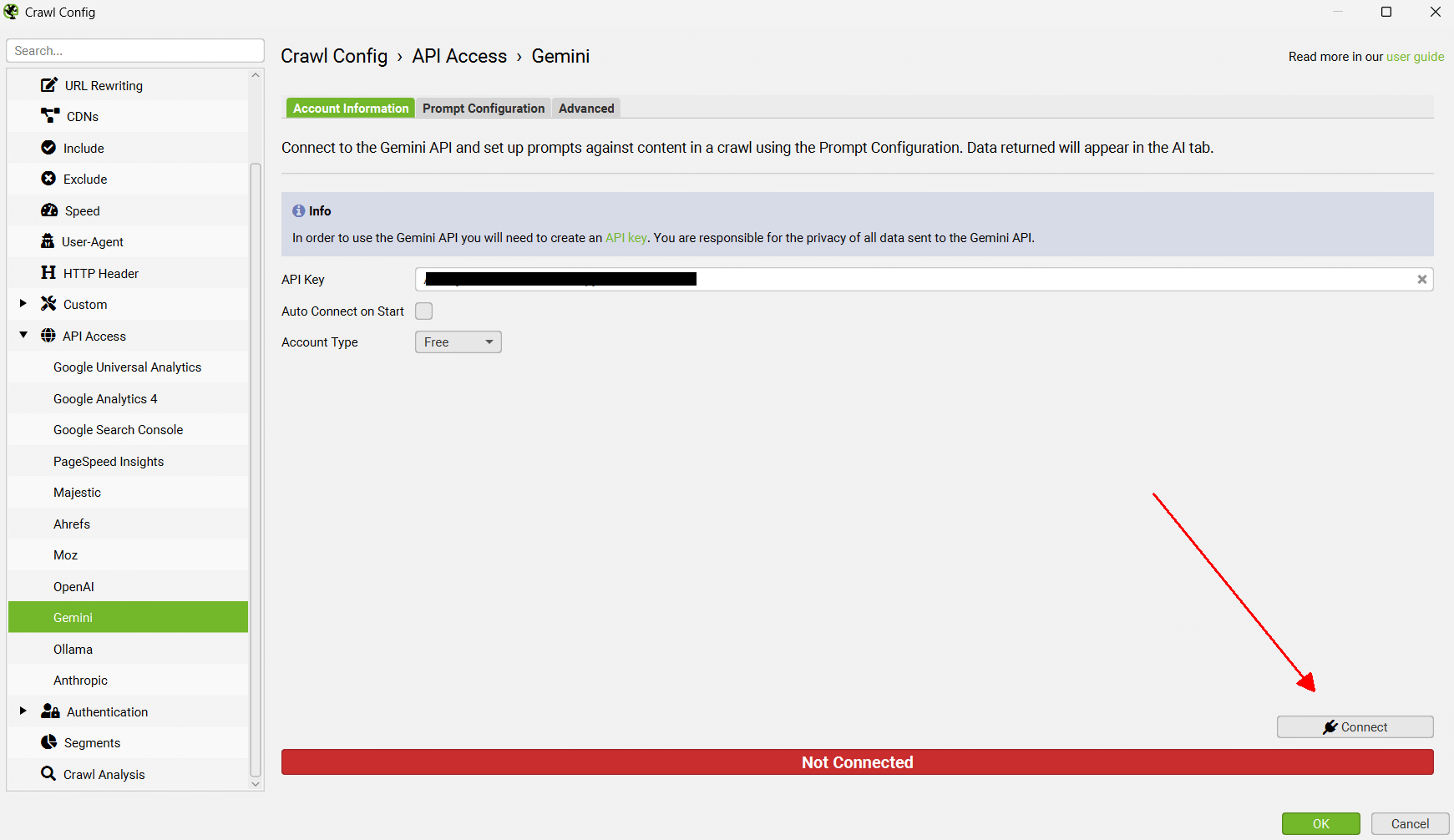
这意味着当您开始爬取时,将生成嵌入并显示在 AI 选项卡中。
4) 选择“Store HTML”和“Store Rendered HTML”
单击“Config > Spider > Extraction”并启用“Store HTML”和“Store Rendered HTML”,以便存储页面文本并用于向量嵌入。
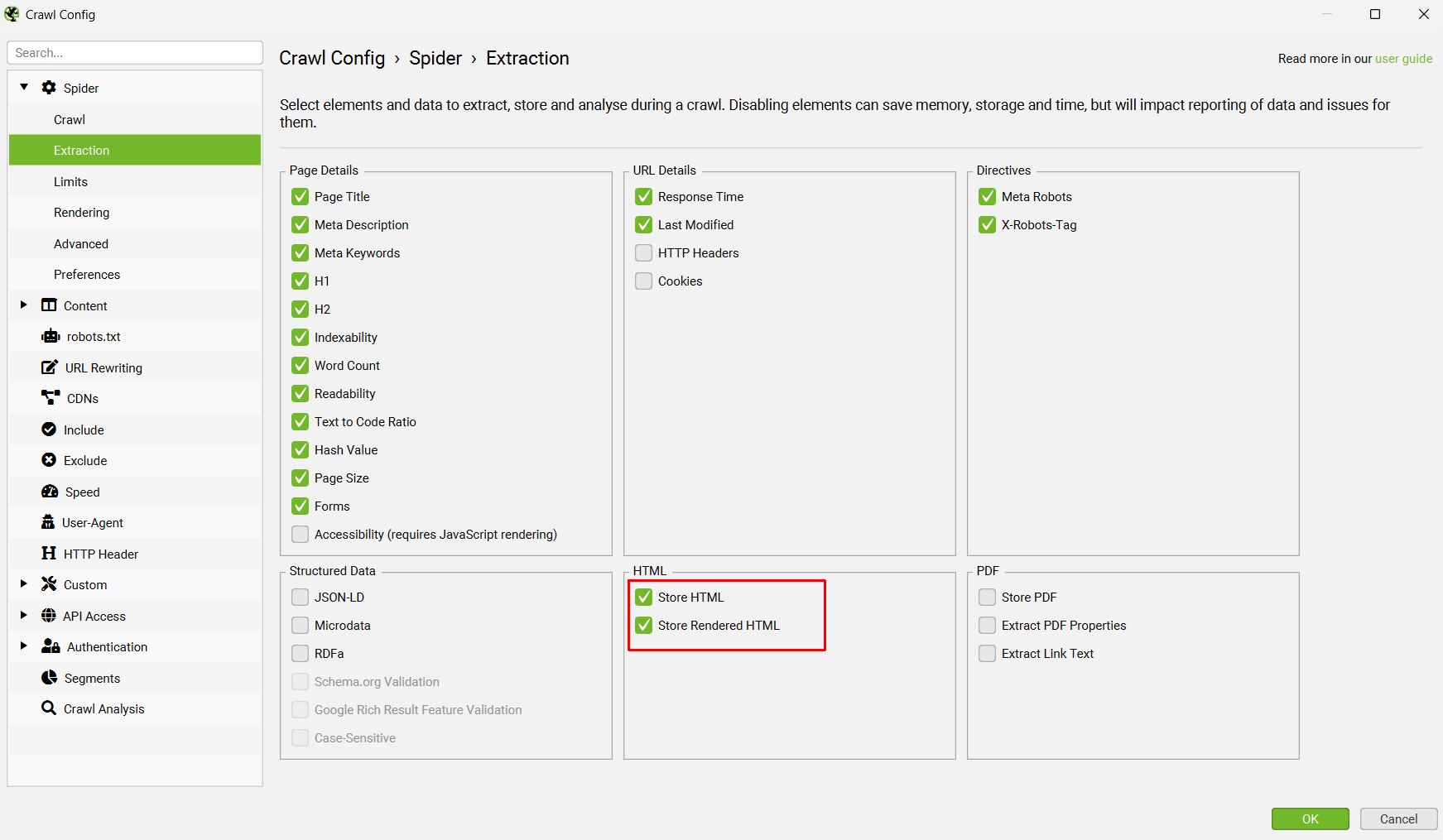
原始 HTML 页面文本将用于纯文本模式的爬取,而渲染的 HTML 页面文本将用于 JavaScript 渲染模式。
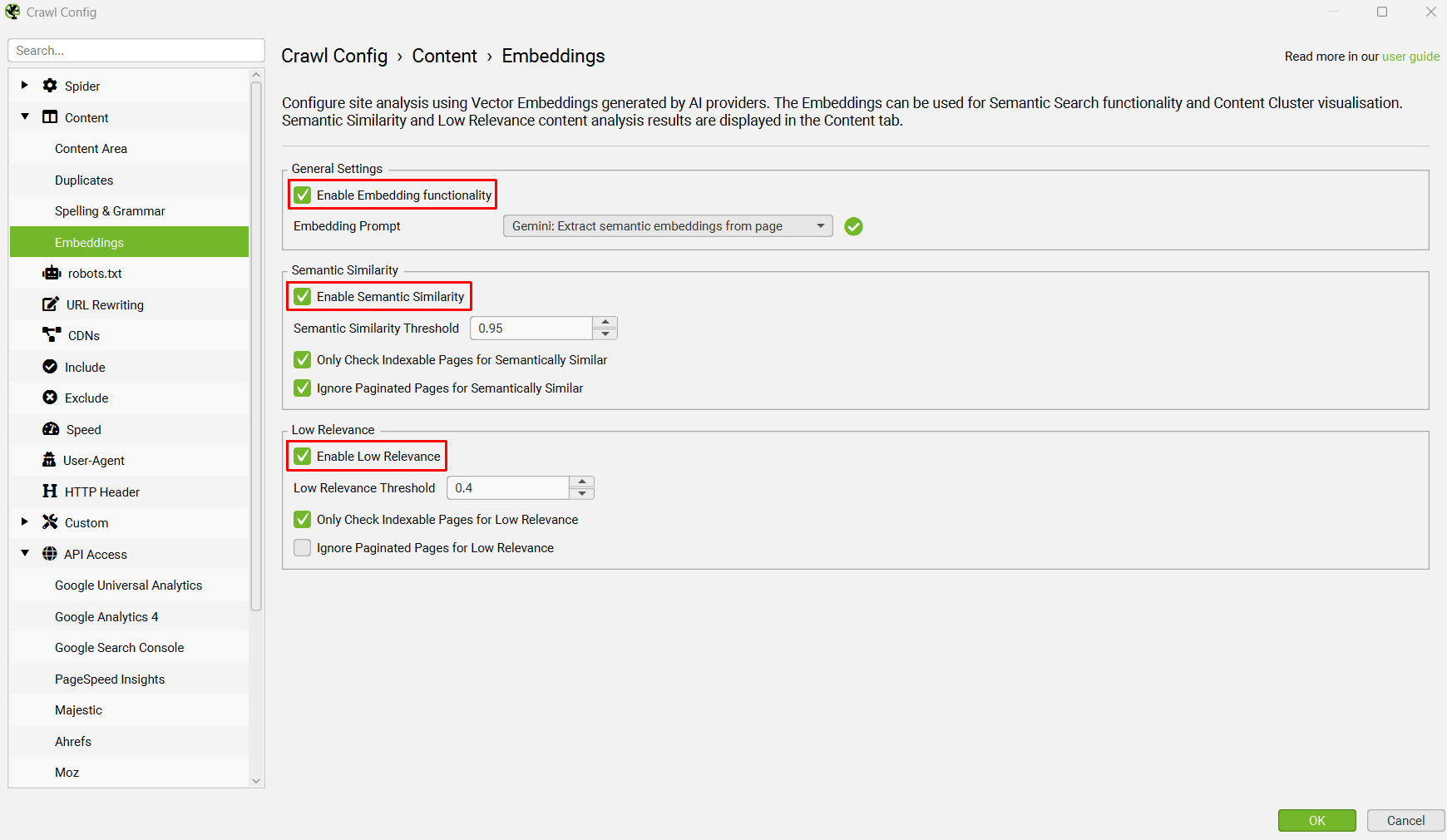
5) 启用嵌入功能
通过“Config > Content > Embeddings”导航到 嵌入配置 并“Enable Embedding functionality”。
设置的提示应自动显示在嵌入提示下拉列表中。 您可以选择多个 API 提供商,并使用下拉列表在它们之间切换。
启用“Semantic Similarity”和“Low Relevance”以填充“Content”选项卡中的相关列和过滤器。
6) 爬取网站
在“Enter URL to spider”框中输入您要爬取的网站,然后点击“Start”。

等待爬取和 API 进度条达到 100%。
7) 运行爬取分析
要在“Content”选项卡中填充“Semantically Similar”和“Low Relevance Content”过滤器(以及关联的列),您需要在爬取完成后执行爬取分析。
在右侧“Overview”选项卡中,在需要爬取分析才能填充的过滤器旁边会显示一个图标和消息。
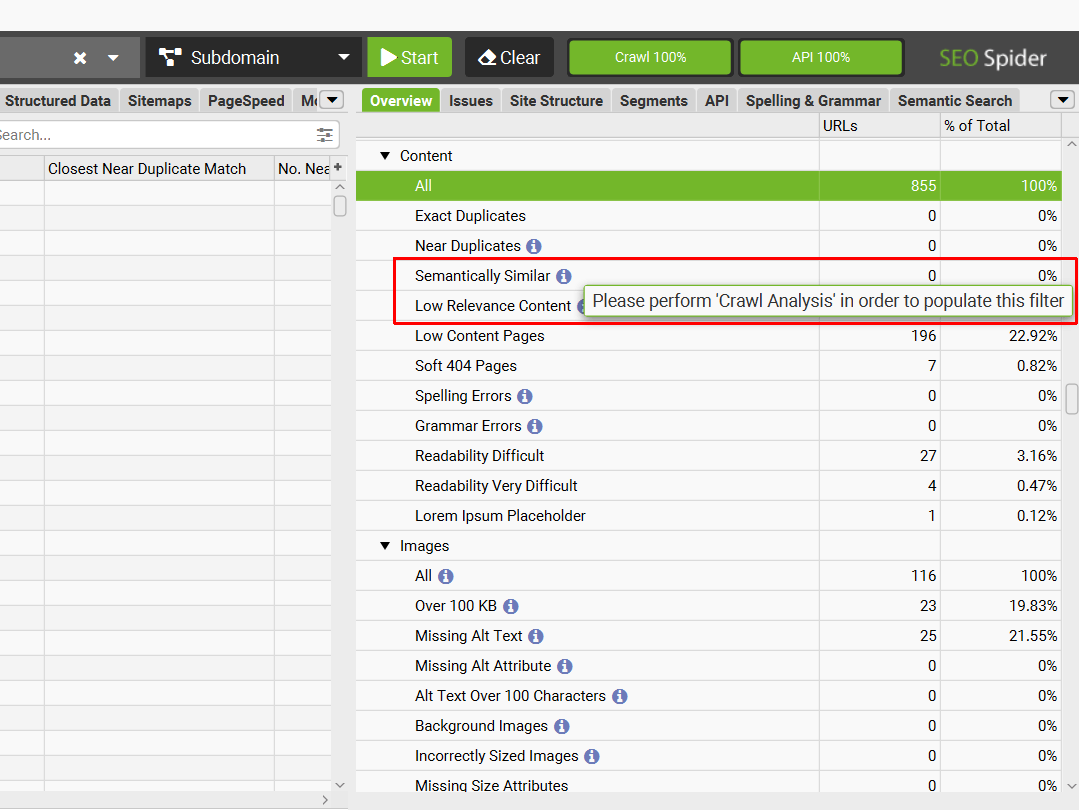
要运行爬取分析,只需点击顶部菜单中的“Crawl Analysis > Start”。
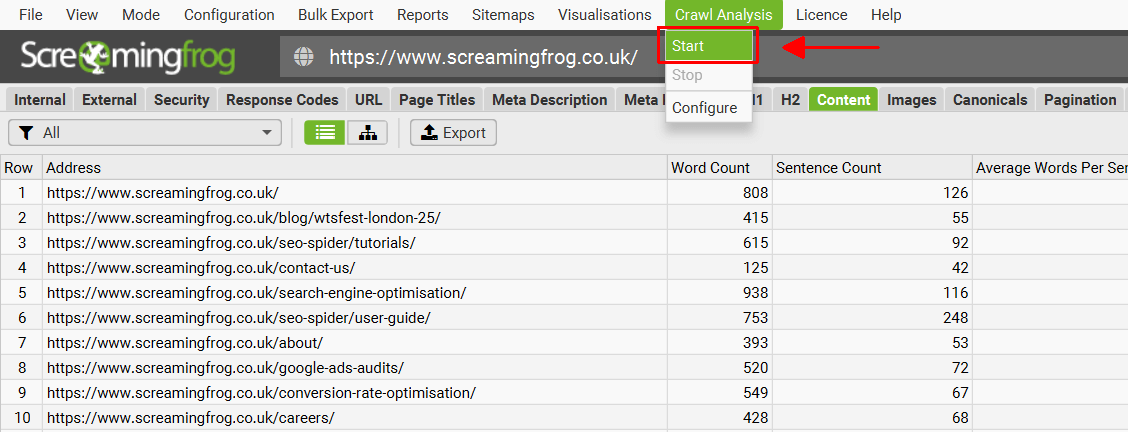
爬取分析进度条将出现在右上角,当它达到 100% 时,就可以分析数据了。
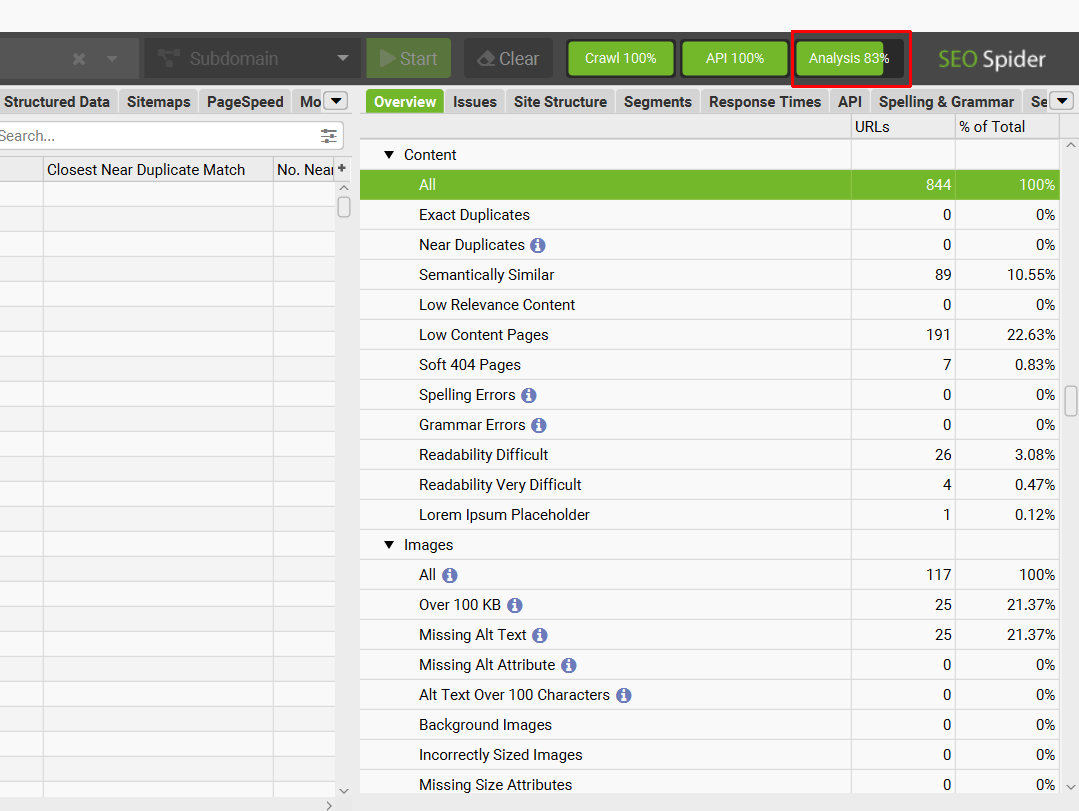
您可以选择在爬取结束时自动运行此操作,以避免将来执行此步骤,方法是依次点击“Crawl Analysis > Configure”并选择“Auto-Analyse at End of Crawl”。
8) 查看语义相似和低相关性过滤器
点击“Content”选项卡并查看现在将填充的“Semantically Similar”和“Low Relevance Content”过滤器。
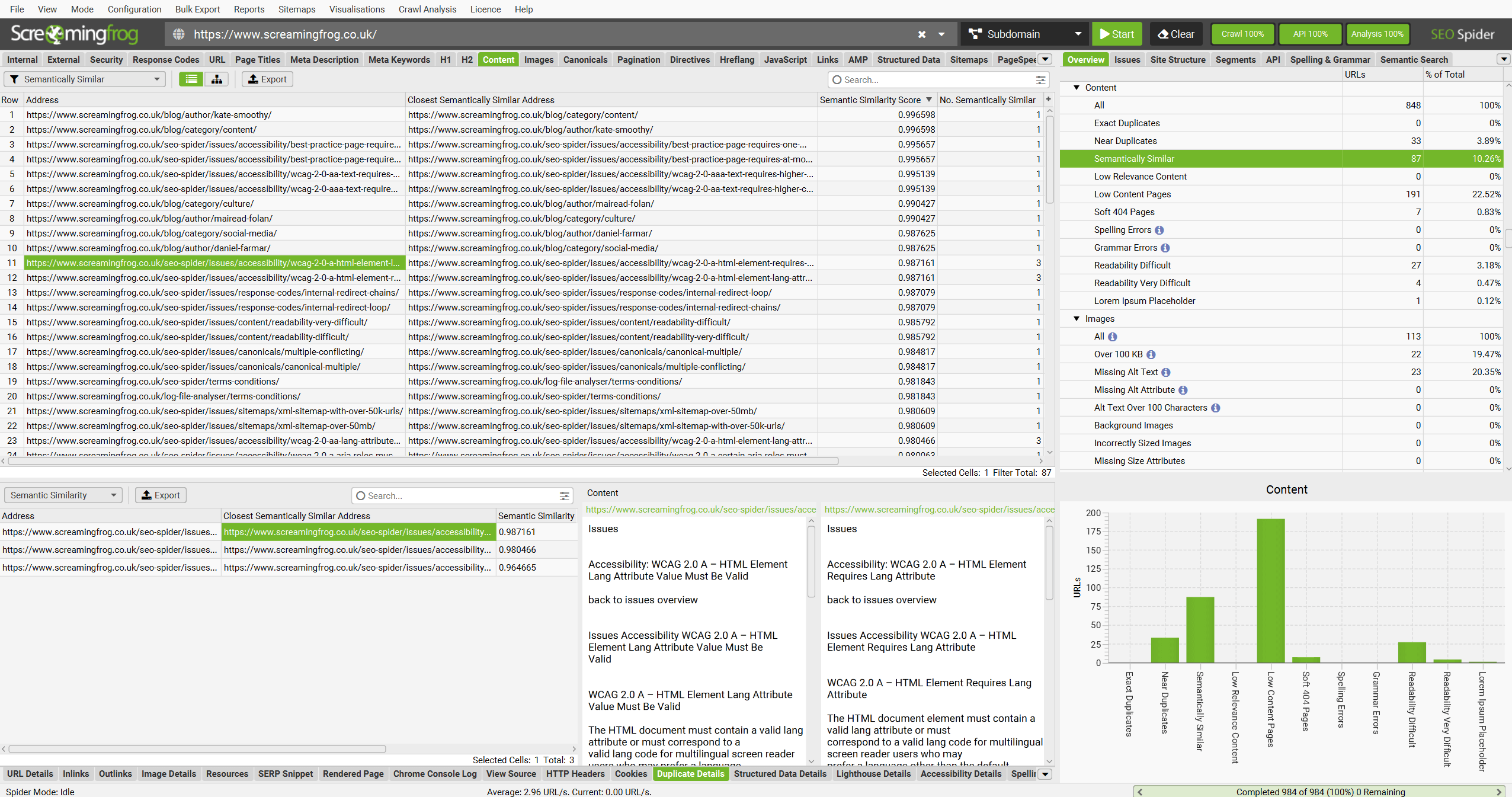
这两个问题如我们的右侧“Issues”选项卡和我们的问题库中所述。
语义相似
“Semantically Similar”过滤器显示每个 URL 的最接近语义相似地址,以及语义相似性得分和语义相似 URL 的数量。
高语义相似性可能完全正常,但也可能表明应审查的重复或重叠内容。
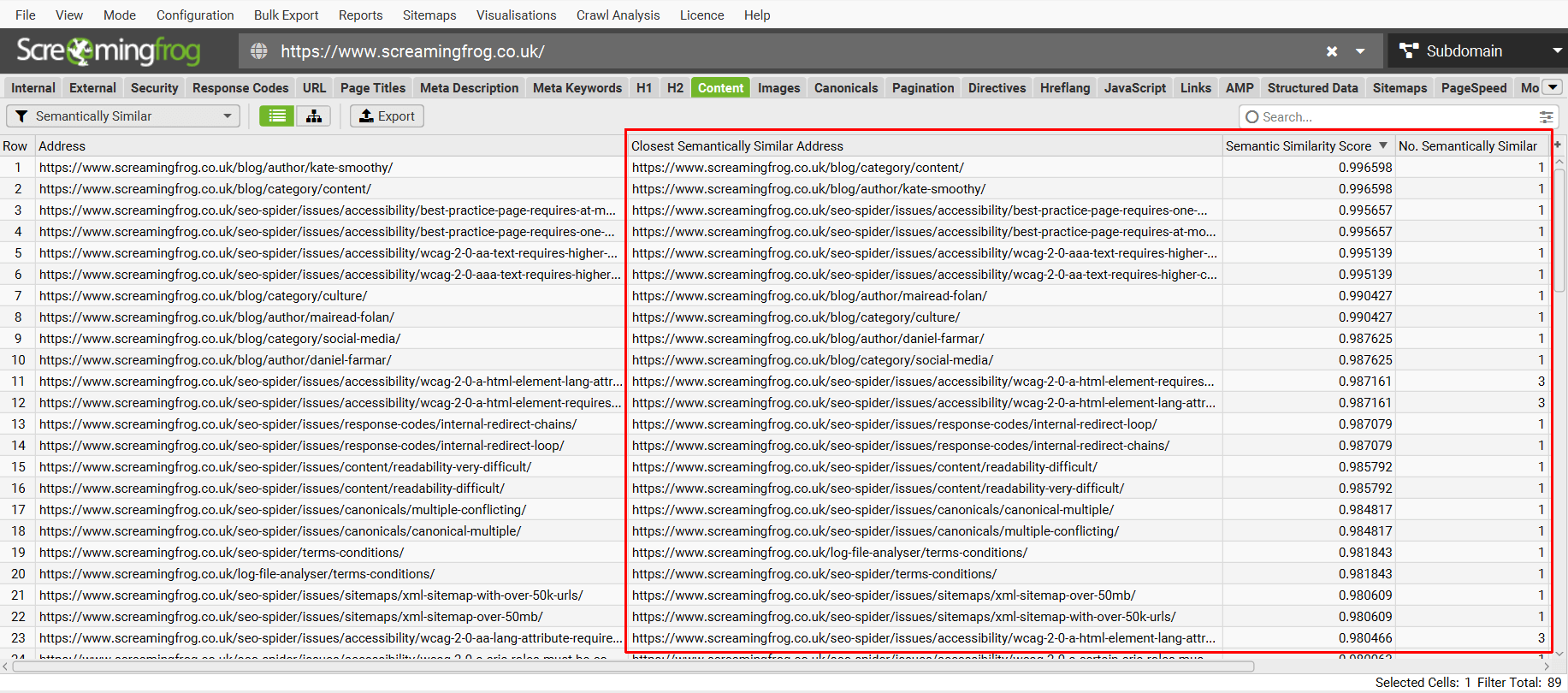
语义相似性得分范围为 0 – 1。 得分越高,页面与其最接近的邻居(显示在最接近的语义相似地址列中)的相似度越高。
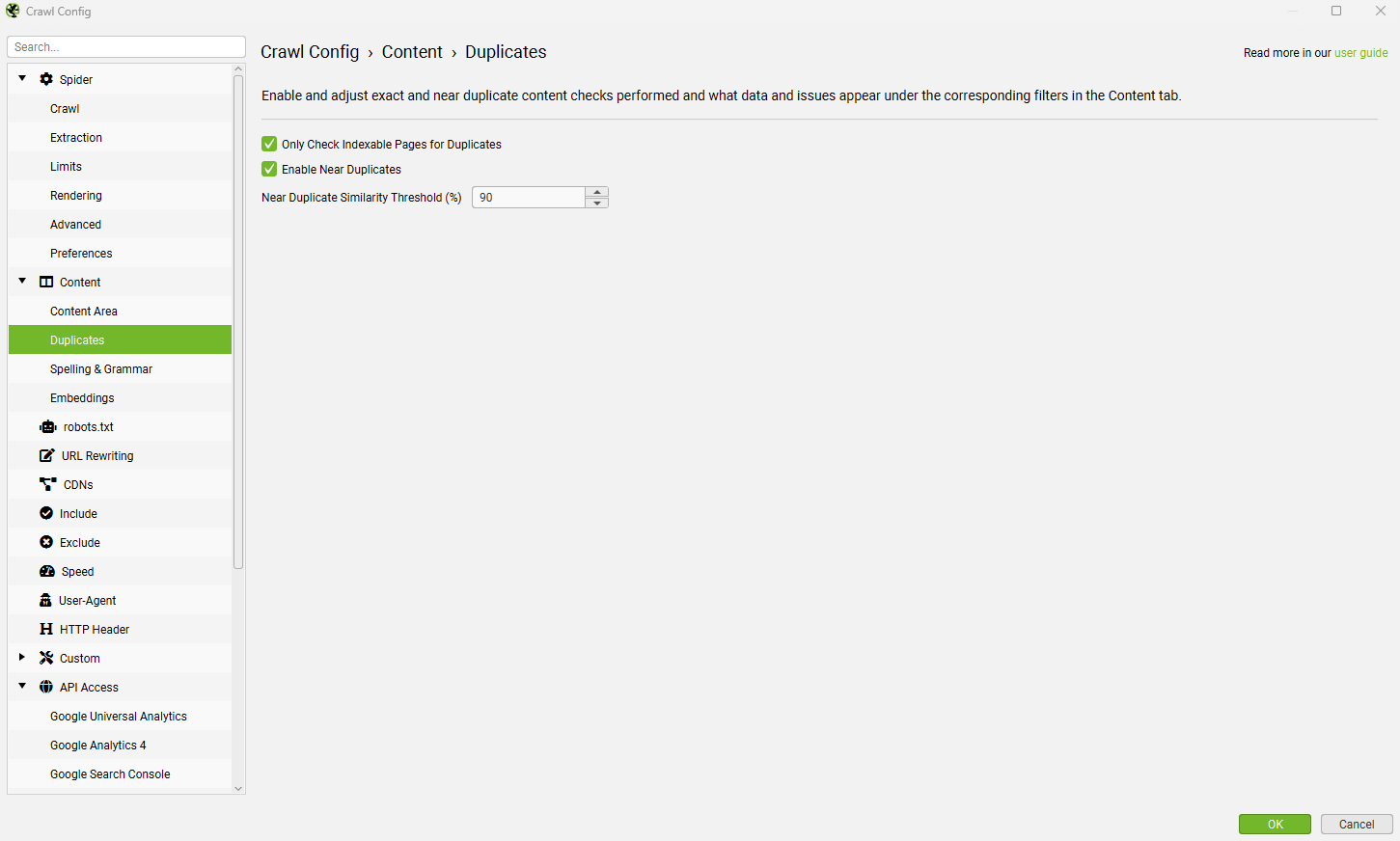
默认情况下,得分高于 0.95 的页面被认为是语义相似的。 可以在 嵌入配置 中调整此阈值。
在我们的问题库中阅读有关“Semantically Similar”问题的更多详细信息。
低相关性内容
“Low Relevance Content”过滤器显示与网站的一般内容主题相比,可能不太相关或离题的页面。
与整个网站重点的低语义相似性可能表明不相关的页面或那些通常不适合所写内容的页面。
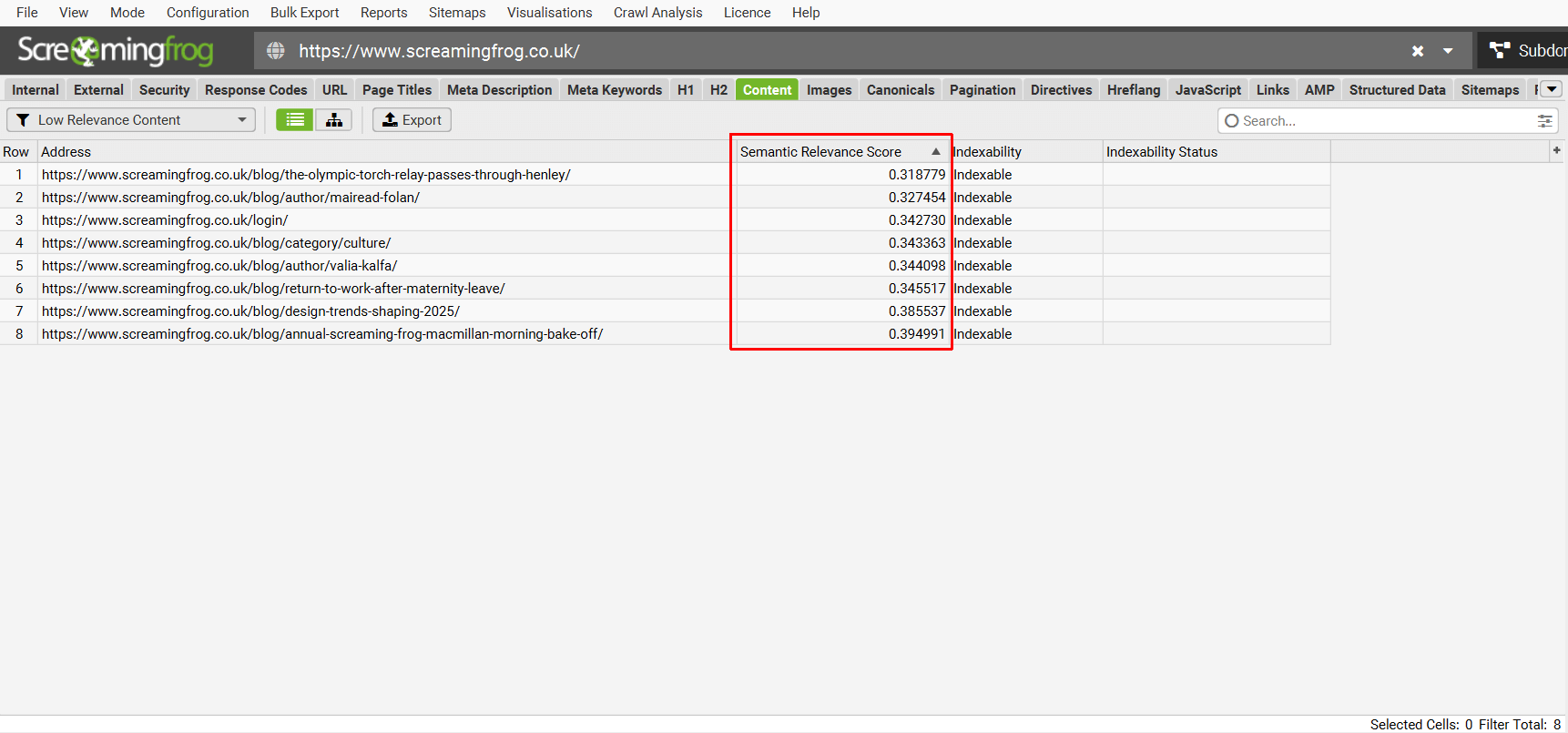
低相关性内容页面是通过平均所有爬取页面的嵌入来识别“质心”,然后测量到质心的语义距离来计算的。“Semantic Relevance Score”列显示页面与质心的相似度。
可以通过“Config > Content > Embeddings”调整阈值,默认设置为 0.4。 页面与网站上编写的平均内容的语义相似性越低,“Semantic Relevance Score”就越低。
在我们的问题库中阅读有关“Low Relevance Content”问题的更多详细信息。
上述两个问题的算法都是根据 内容区域 对页面上的文本运行的。
9) 查看重复详细信息选项卡
当有多个 URL 与某个 URL 语义相似时,较低的“Duplicate Details”选项卡和“Semantic Similarity”过滤器将列出所有语义相似的 URL。
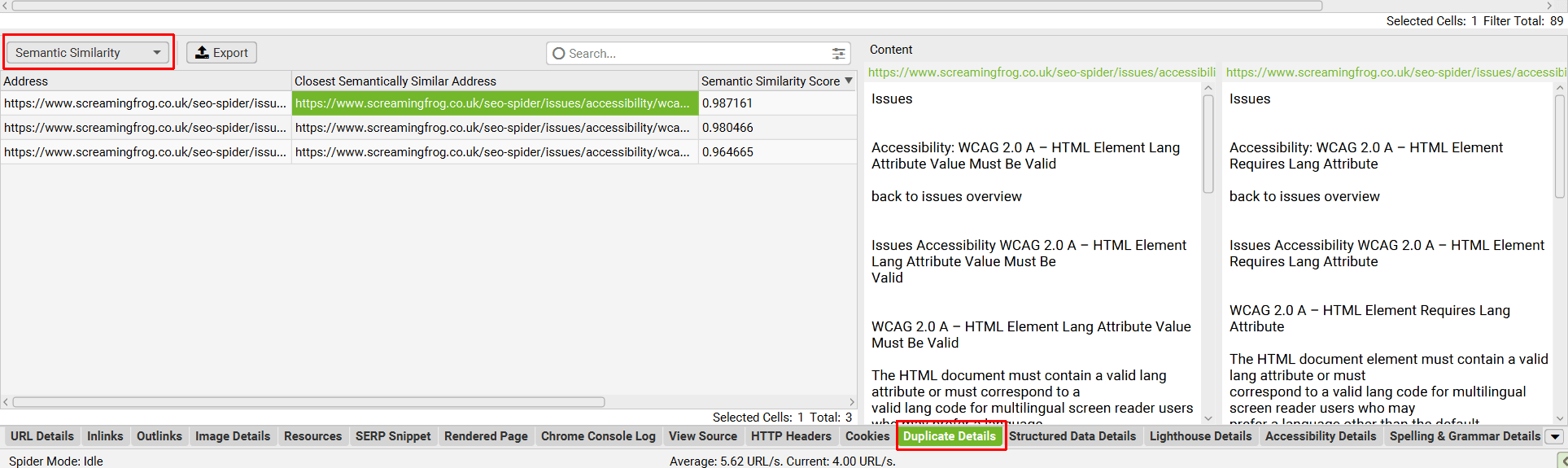
选项卡的右侧显示分析的文本,因此很容易查看它们为何被归类为相似。
10) 批量导出语义相似
可以通过“Bulk Export > Content > Semantically Similar”导出批量导出“Semantically Similar”URL。
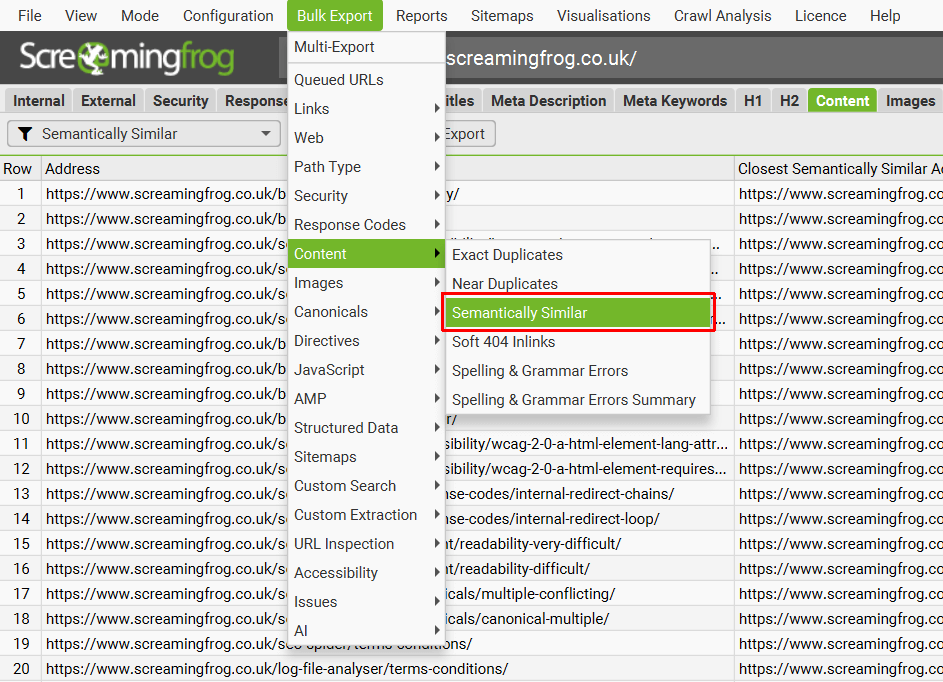
这将包括最接近的语义相似地址和任何高于阈值的地址。
11) 查看语义内容集群图
“Visualisations”菜单下提供的“Content Cluster Diagram”是爬取中 URL 的二维可视化,这些 URL 从嵌入数据中绘制和聚类。
它可用于识别网站内容中的模式和关系,其中语义相似的内容聚集在一起。
该图一次最多可以显示 10,000 个页面。 节点越靠近,它们彼此之间的语义相似性就越高。
上面的示例图突出显示了动物网站的语义关系。
老虎种群紧密地聚集在一起,最近的邻居是老虎和狮子之间的狮虎兽杂交种,然后是其他大型猫科动物,如豹子、美洲虎和猎豹,依此类推。
这些图可以可视化网站上内容集群的规模,或识别语义相关的潜在主题集群 - 但可能与用户的集成度较低。
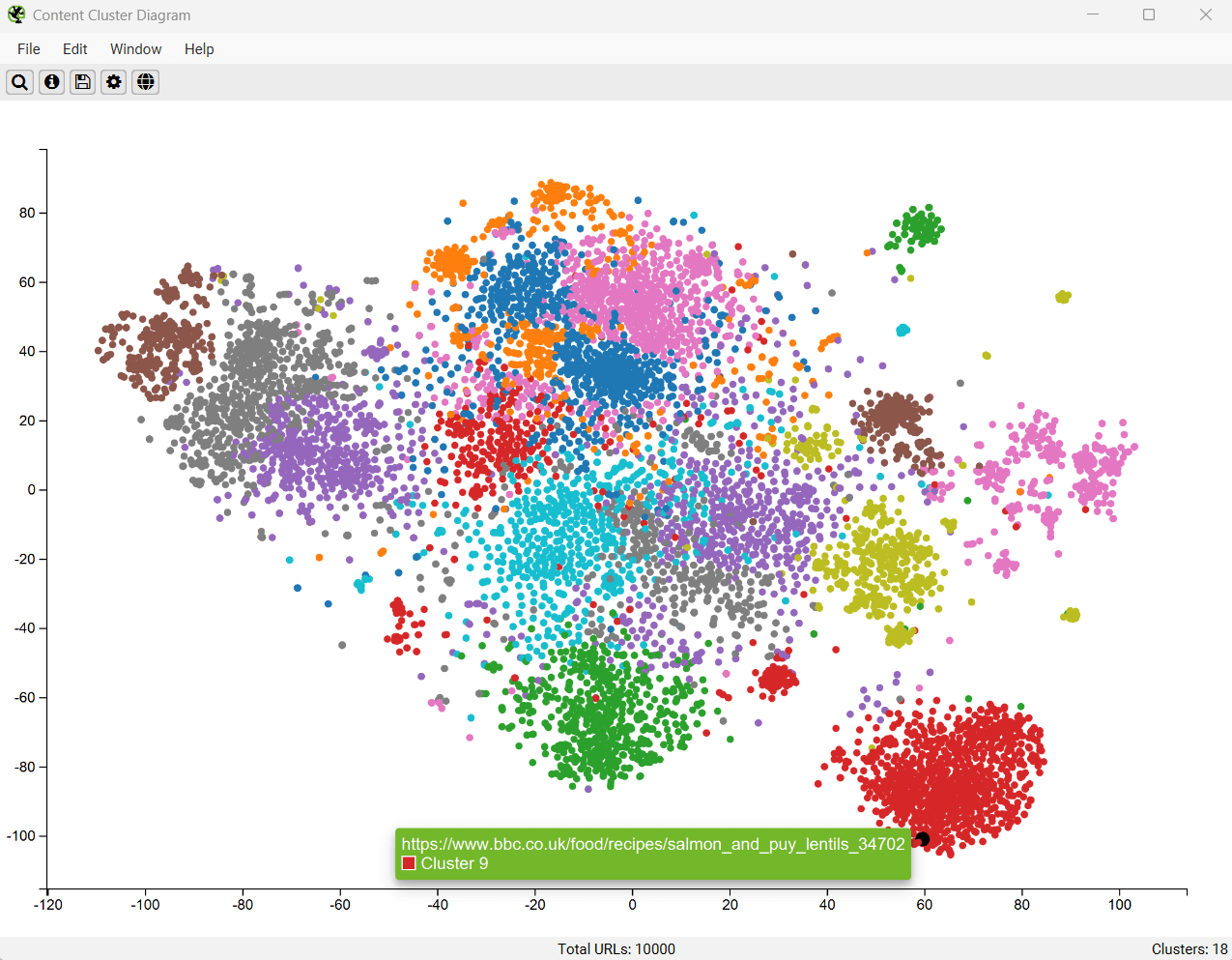
低相关性内容和异常值可以很容易地识别为图边缘上的孤立节点。
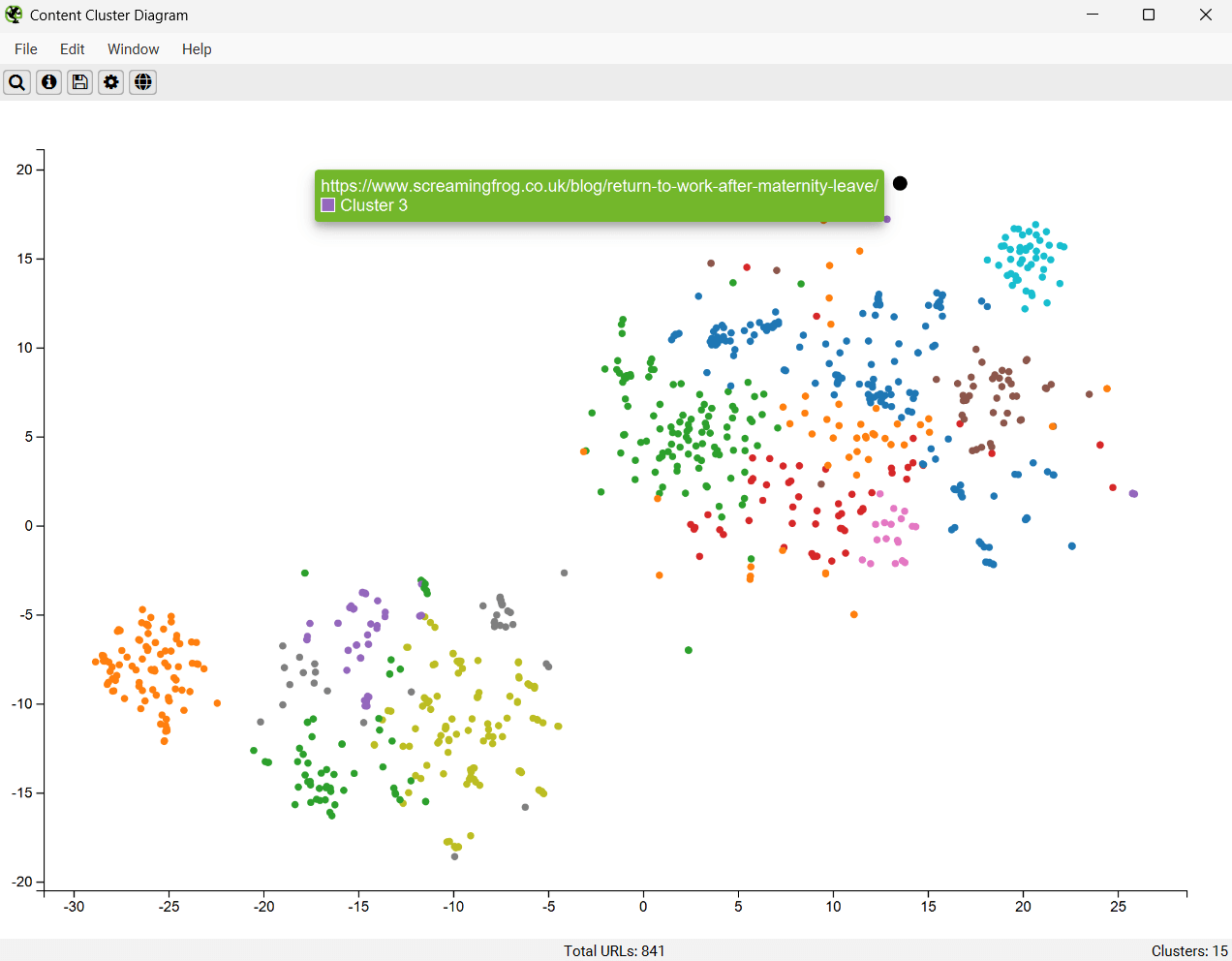
齿轮允许您调整使用的采样、降维、集群数量和配色方案。 您也��可以选择使用“segments”作为聚类节点配色方案。
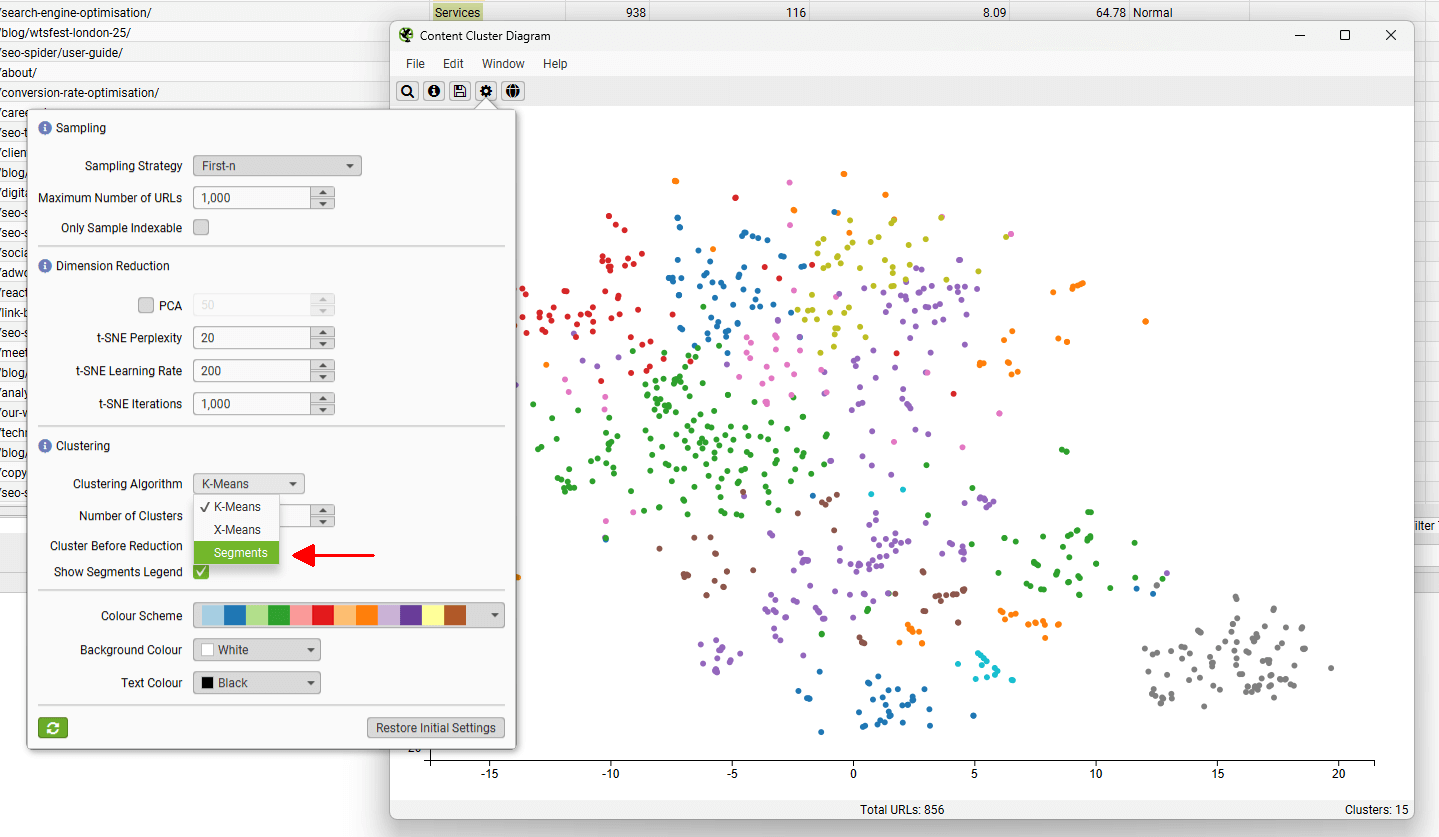
当两个语义相似的页面位于不同的段中时,这可能有助于发现,可以考虑将它们相互内部链接。
在上述情况下,涵盖相同主题的两个页面位于网站的不同部分 - tutorials 和我们的 issues library,并且应该通过内部链接相互引用。
改进结果的技巧
您可以执行各种操作来改进使用向量嵌入进行语义内容分析的结果。
优化您的内容区域设置
嵌入的质量将仅与生成期间提供的内容一样好。 如果提供给 LLM 的内容混乱,那么分析的嵌入和结果将不太有用。
要查看为 URL 生成嵌入而提供的内容,请使用较低的“View Source”选项卡和“Visible Content”过滤器。
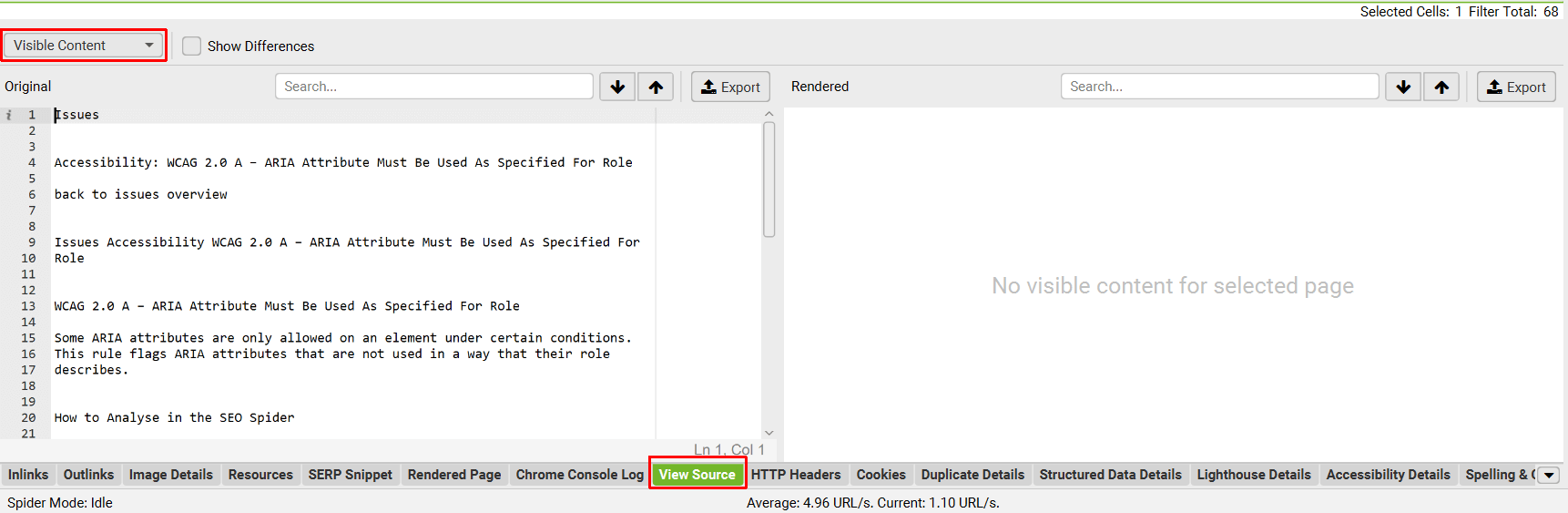
您可以通过“Config > Content > Area”配置使用的内容。
SEO Spider 将排除导航和页脚元素,以专注于主要正文内容。 但是,并非每个网站都是使用这些 HTML5 元素构建的,因此您可以优化用于分析的内容区域。 您可以选择从分析中“include”或“exclude”HTML 标签、类和 ID。
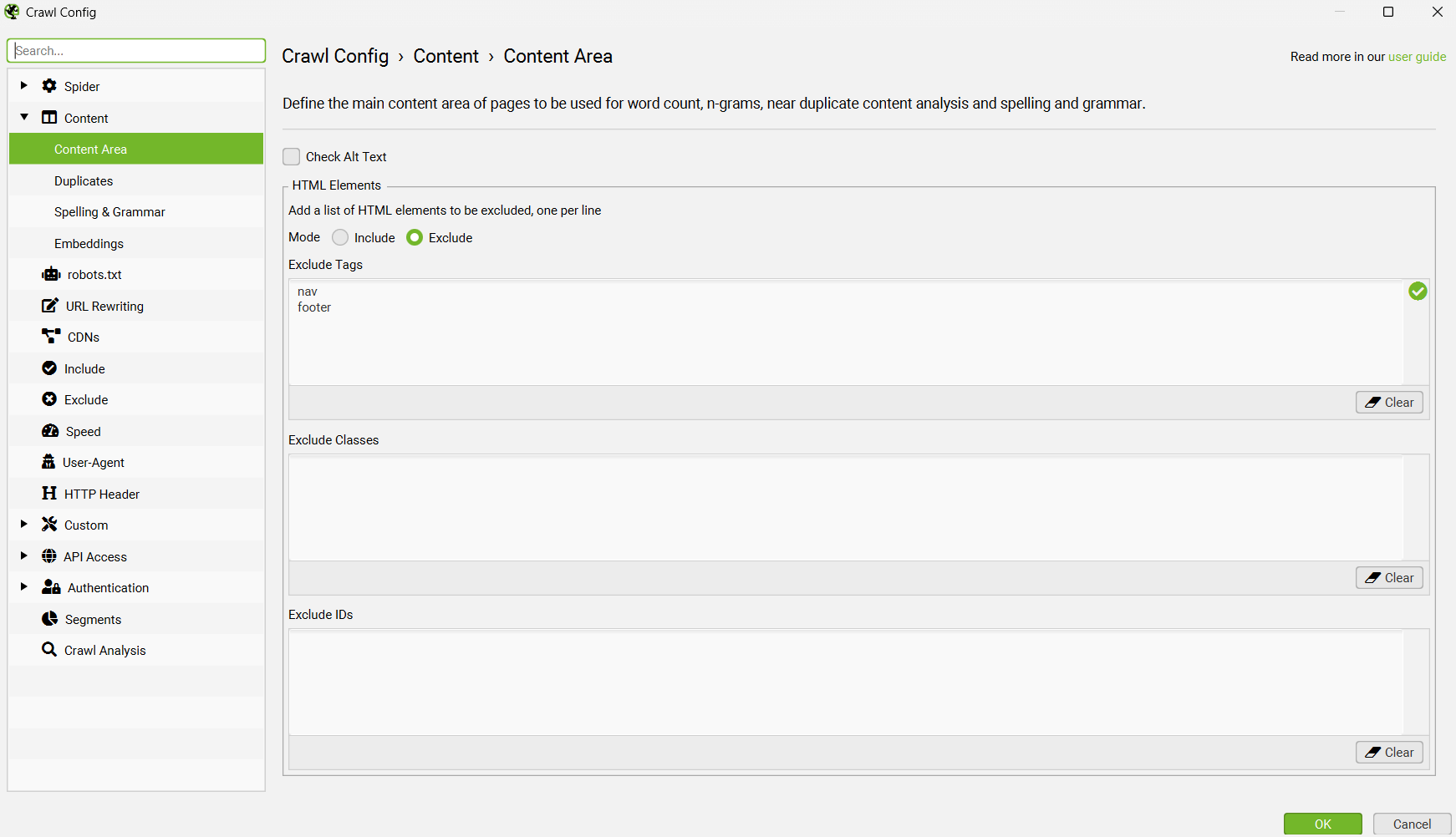
因此,请考虑删除样板文本,这些文本在页面上是相同的 - 例如 cookie 内容文本、其他菜单项、公司地址和电话号码等。 专注于每个页面的主要独特内容。
例如,Screaming Frog 网站在 issues 页面上有一个额外的辅助导航,以及在整个网站上重复相同文本的“download”模式窗口。
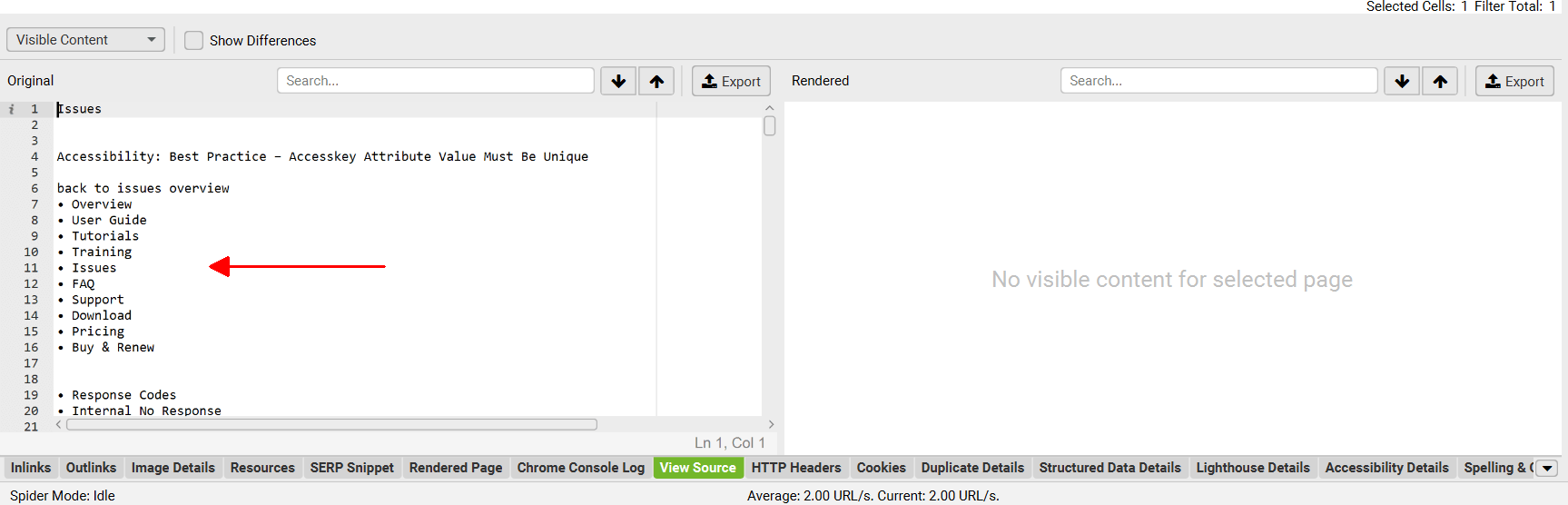
如果用于生成嵌入,它们的存在会使页面看起来更相似。 更新内容区域设置以删除相关的 div 类可以改善提供的内容。
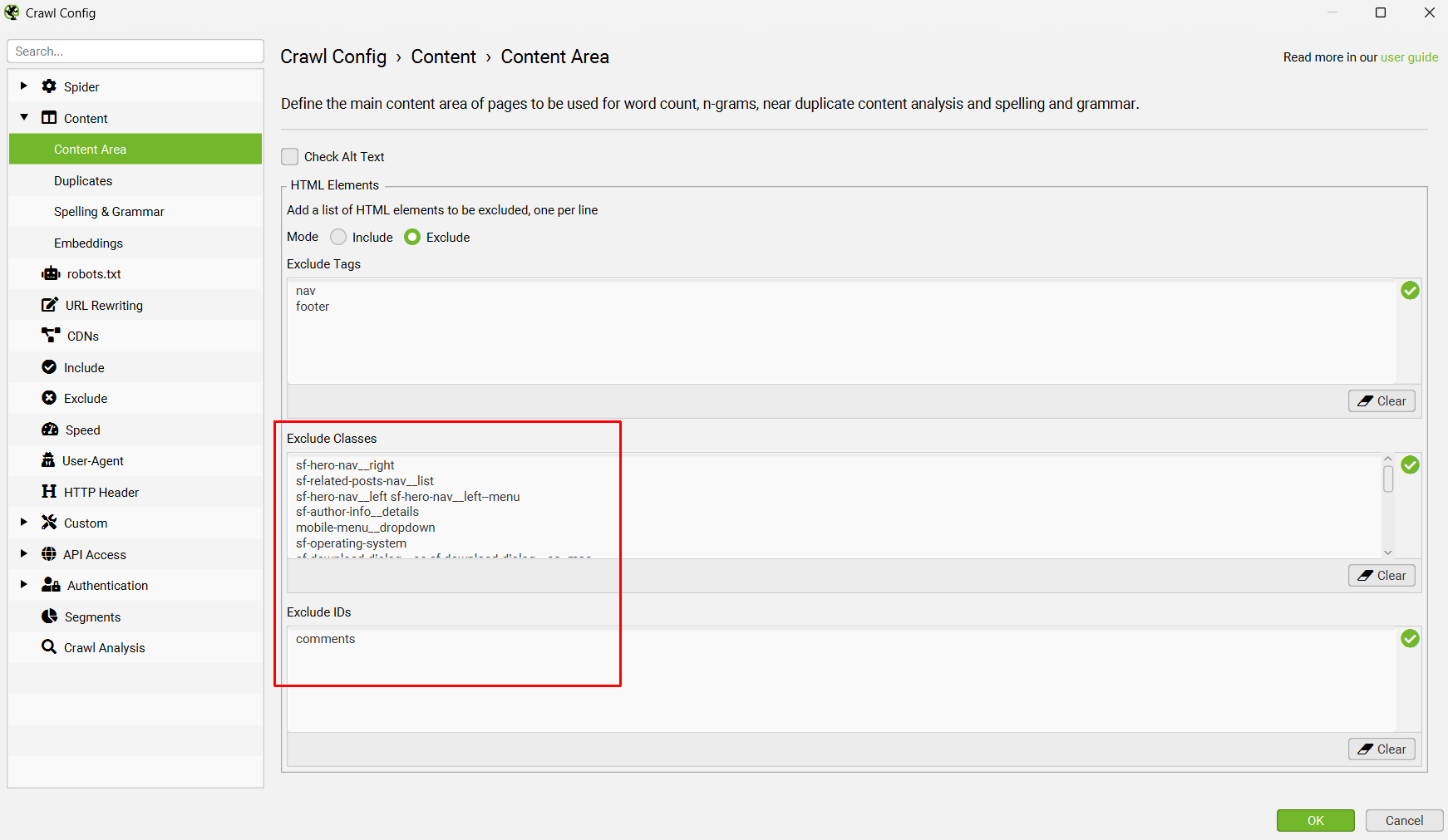
这将从嵌入生成中排除菜单和其他重复项目,以获得更好的结果。
提高速度,而不损失准确性
Dejan SEO 的研究表明,您可以将向量嵌入的维度从 1,024 减少到 256,并且不会牺牲准确性,同时显着提高速度并减小尺寸。
可以通过点击模式名称旁边的齿轮来添加参数,从而截断嵌入的维度。
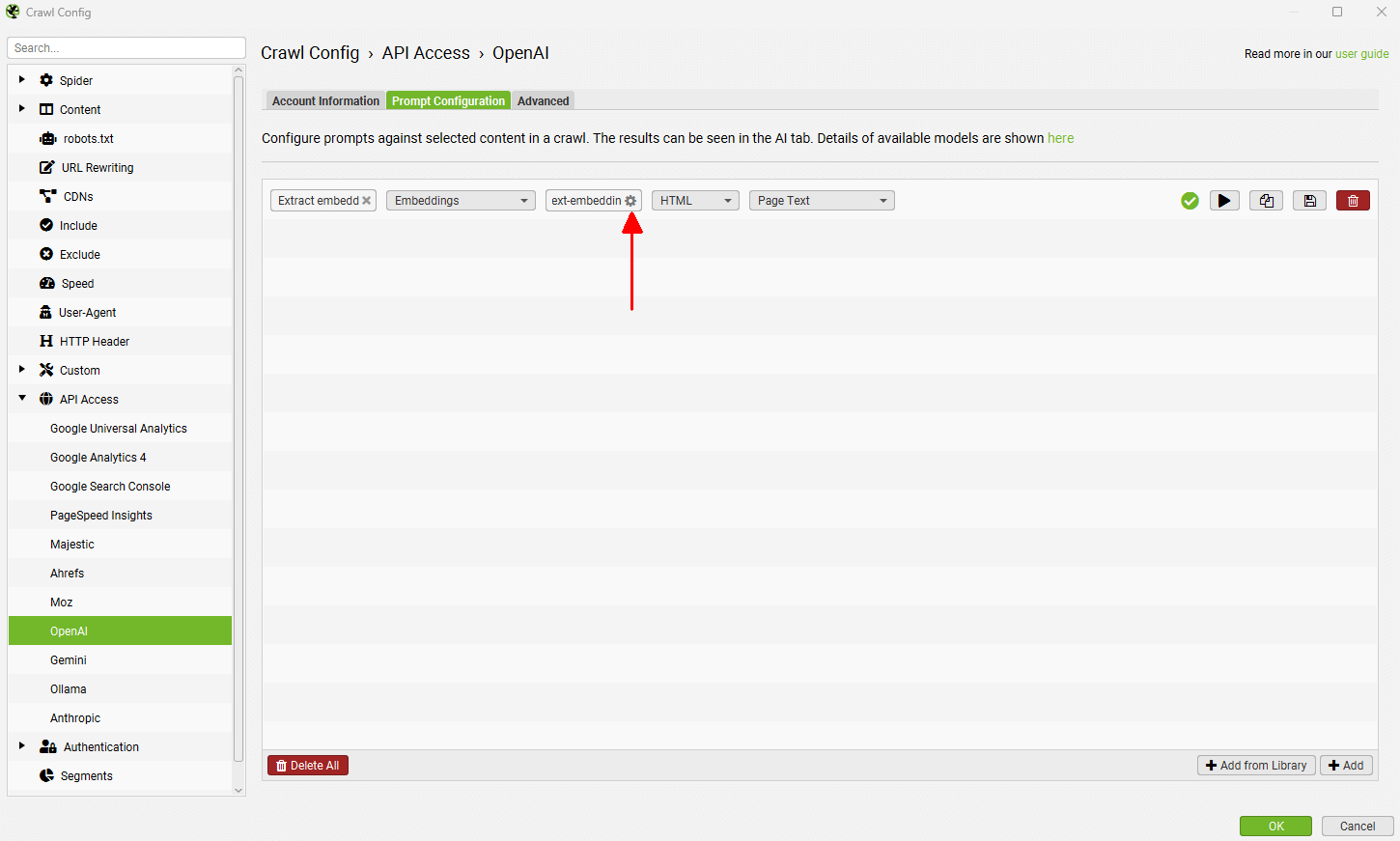
点击“添加参数”,输入维度名称和值,并将类型从“字符串”调整为“数字”。对于 OpenAI,维度参数是“dimensions”。
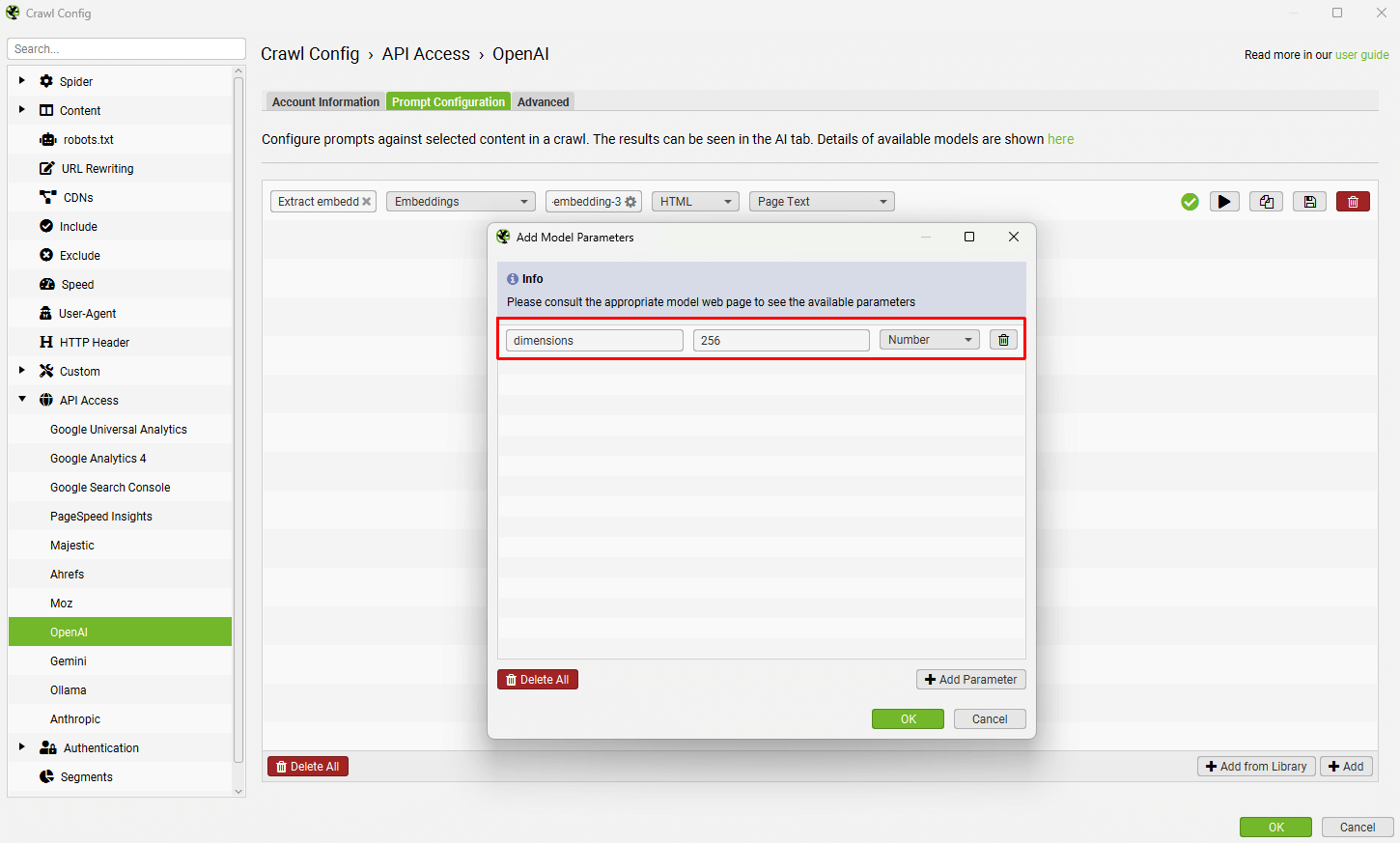
对于 Gemini,设置维度的参数是“outputDimensionality”。
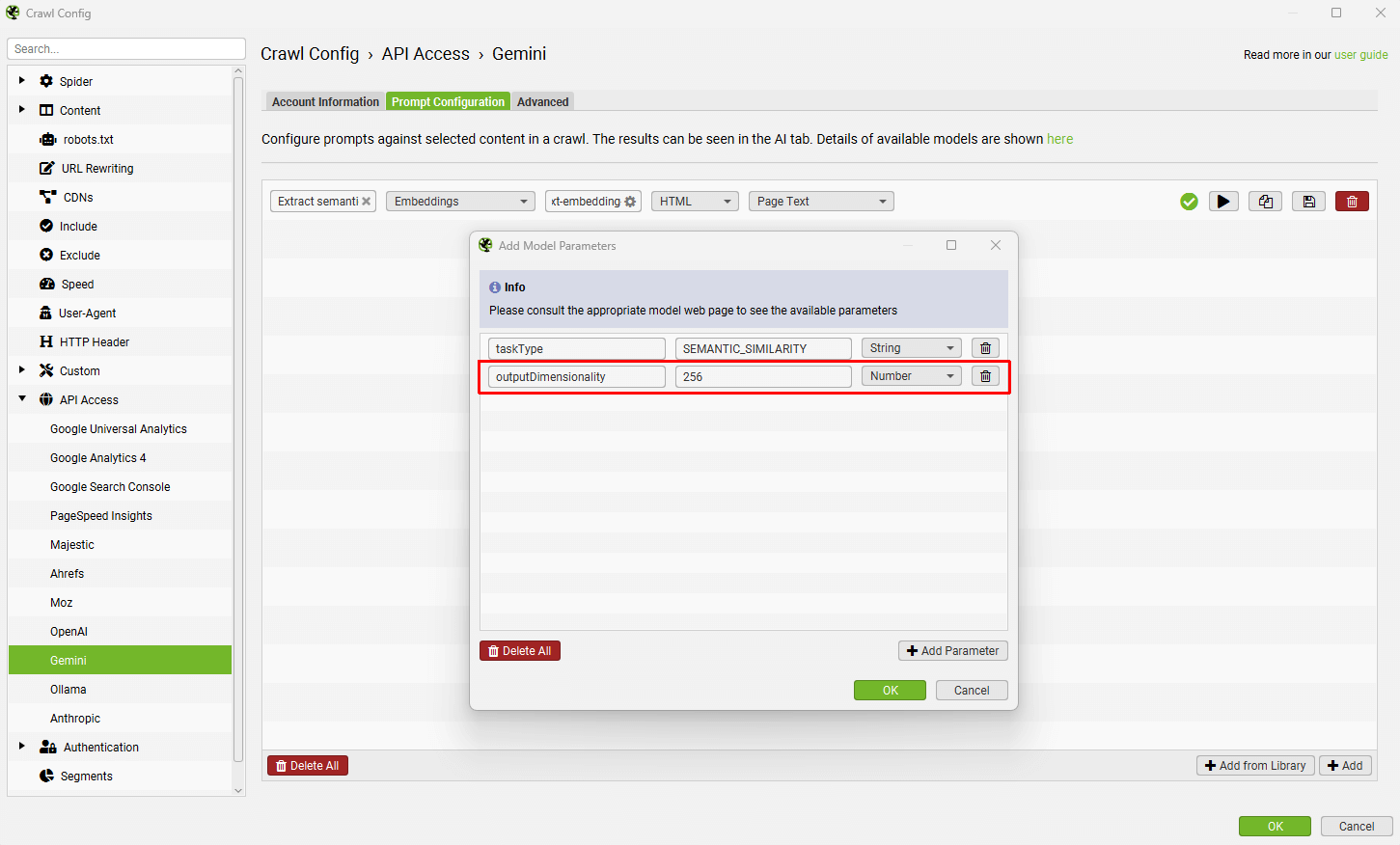
这些更改在性能较低的机器上会更加明显,但会加快抓取分析和内容集群可视化,并减小抓取的大小。
经过有限的测试,我们发现抓取分析提高了 30%,t-SNE 降维提高了 55%。
针对大型页面的“限制页面内容”
在“AI”选项卡下查看可索引的 HTML 页面,查找任何缺少嵌入的页面(相关嵌入列中应该有一个长数字),并在“Prompt Request Status”中显示错误:
Error: Bad Request. "This model's maximum context length is 8192 tokens, however you requested 11679 tokens (11679 in your prompt; 0 for the completion). Please reduce your prompt; or completion length."
这些通常是大型内容页面,它们超过了 AI 提供商模型的上下文 token 长度。
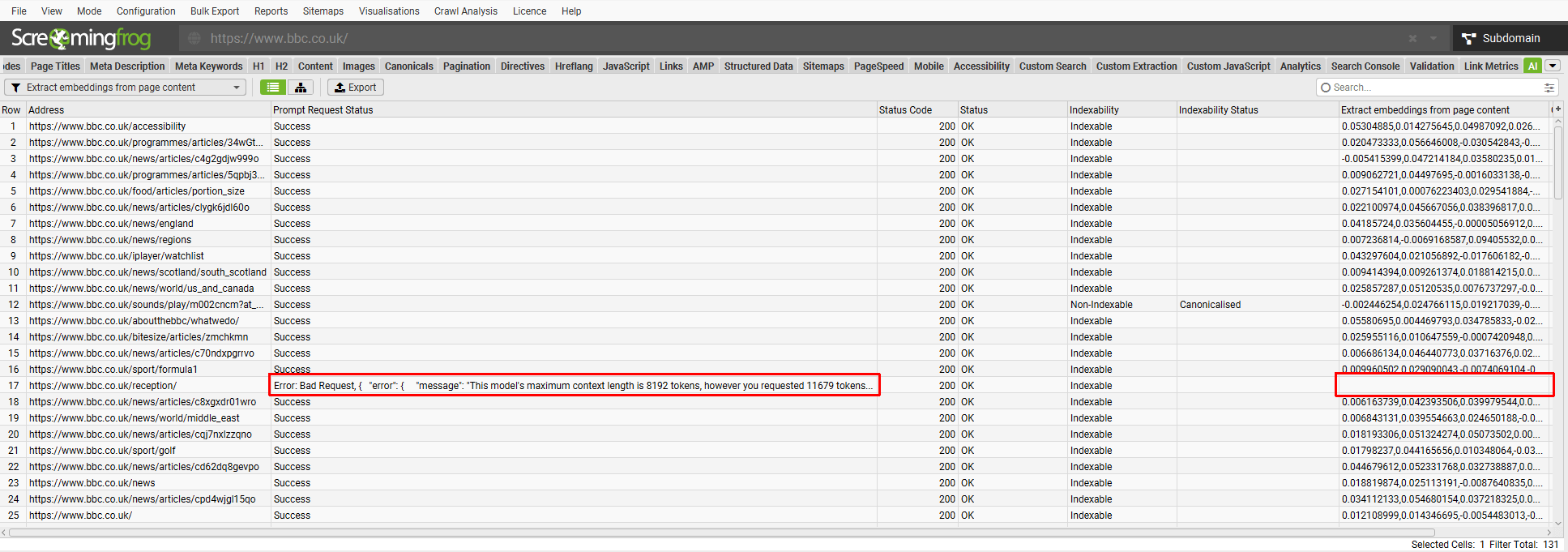
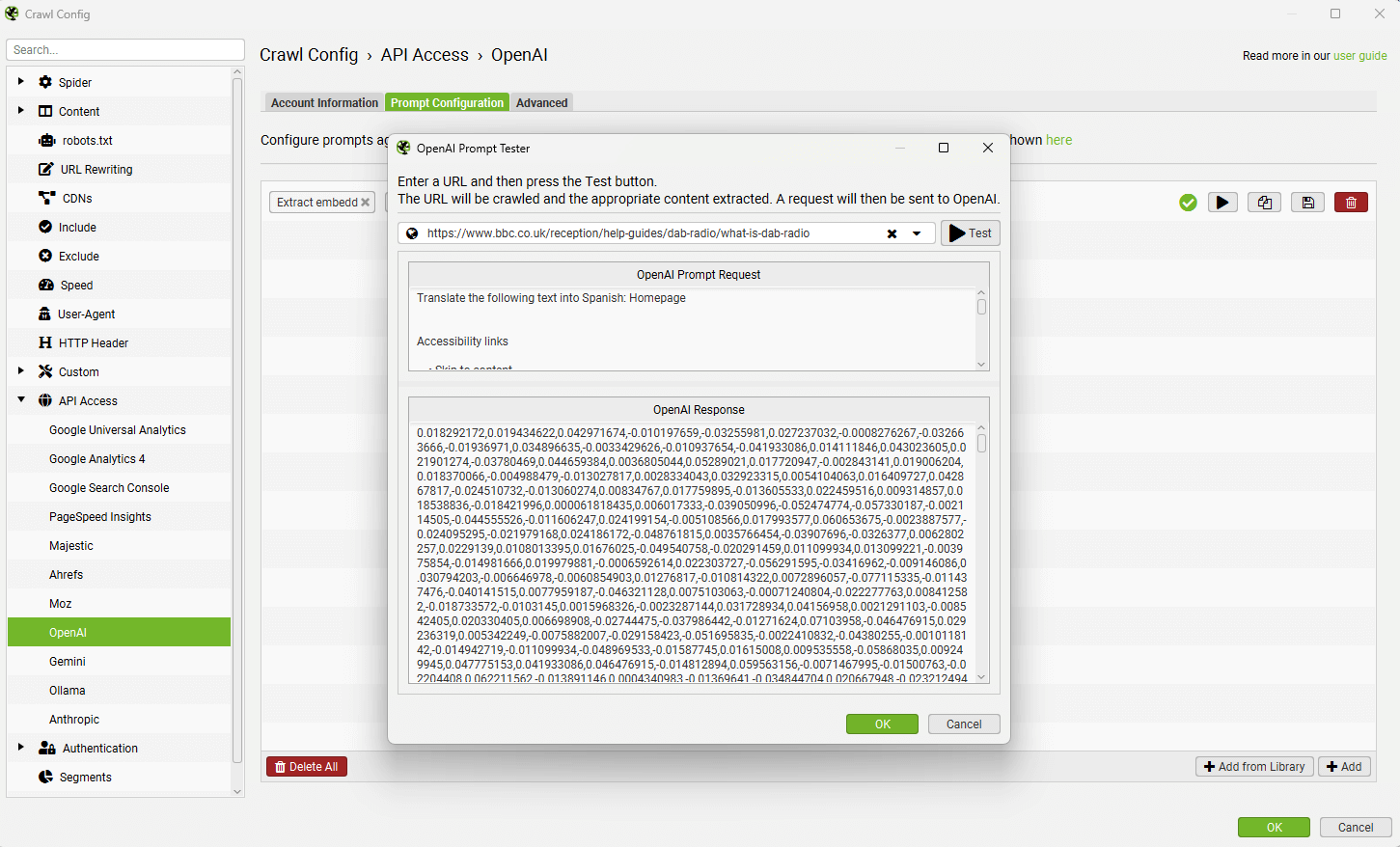
可以通过暂停抓取,然后点击“配置 > API 访问 > AI > AI 提供商”,然后在“Prompt Configuration”上点击“测试”按钮来调试此问题。
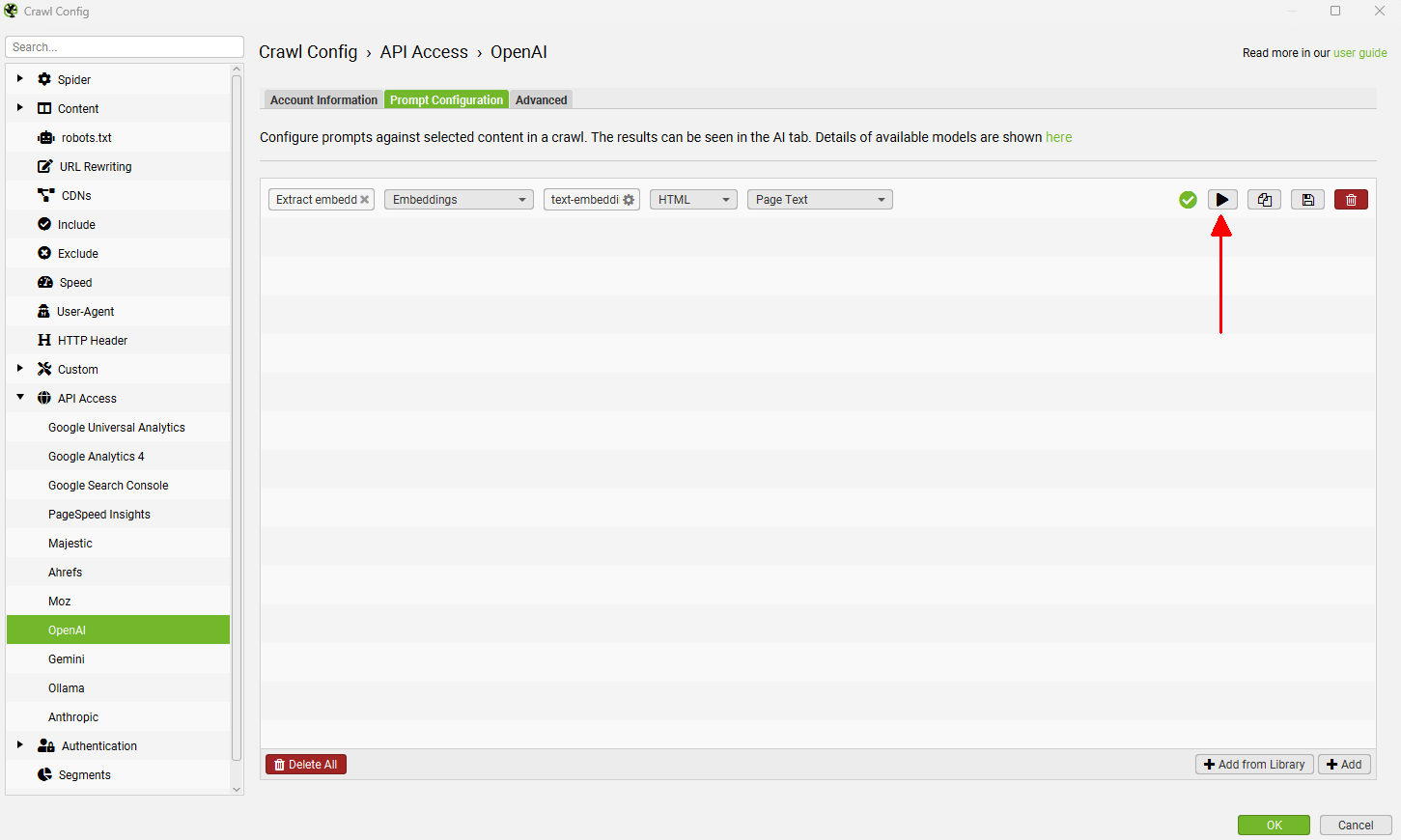
输入缺少嵌入的页面的 URL,并读取来自 AI 提供商的响应。
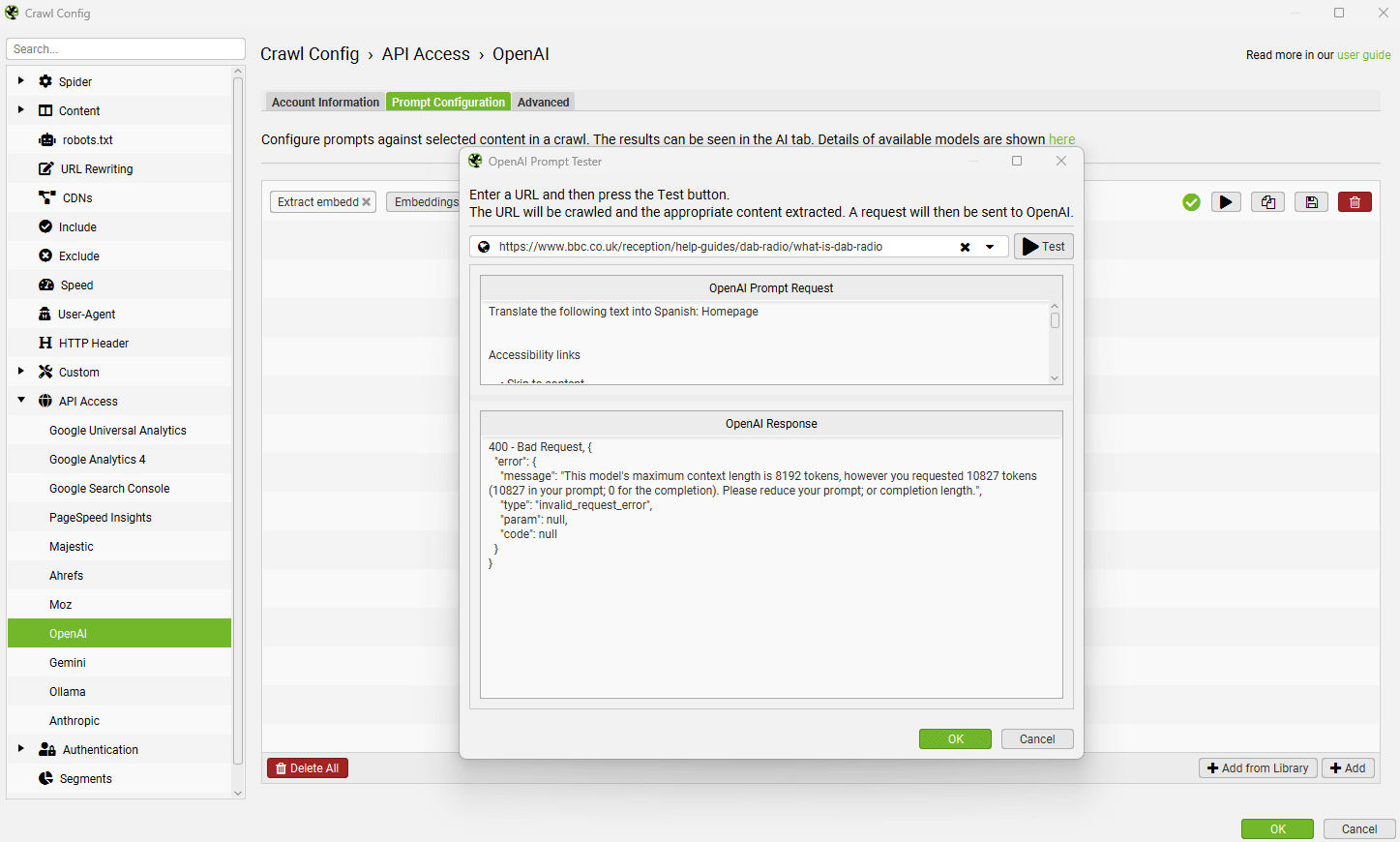
这将确认错误是否与上下文长度 token 限制的大小有关。
关闭测试窗口,点击“高级”选项卡,然后启用“限制页面�内容”,这将把 prompt 中的内容限制为 5,000 个字符。可以根据模型调整此值。
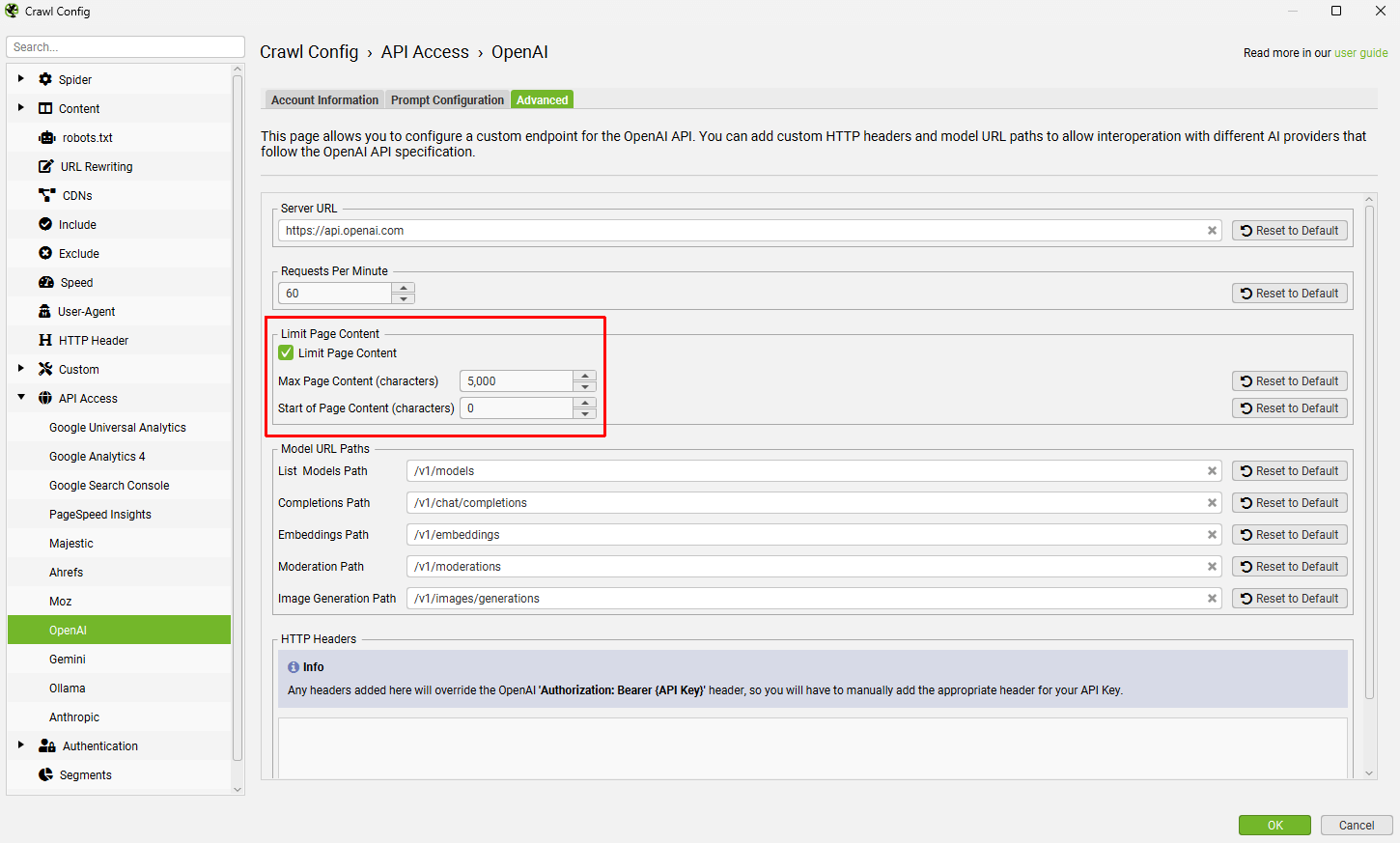
返回到测试选项卡,确认此更改现在会生成嵌入。
通过此调整,返回到 AI 选项卡,右键单击并为任何缺少嵌入数据的 URL 批量“请求 API 数据”。

这将仅为这些 URL 重新请求数据,以便可以将它们包含在分析中。
结合使用精确和近似重复内容检测
SEO Spider 能够使用更传统的页面文本匹配方法,使用 MD5 和 minhash 算法查找精确和近似重复内容。
此检测不旨在理解语言,而是依赖于单词匹配和顺序。因此,它不会找到语义相似的页面,这些页面使用不同的词语来描述相似的事物。
虽然语义相似性功能会找到出现在这些过滤器�中的精确和近似重复项,但它也会找到更复杂的匹配项。
两者执行类似的工作,但方式不同,并且可以产生截然不同的结果——这就是为什么通常将它们结合使用很有用。
重复内容检查的结果通常是“显而易见”的更高优先级的重复项,因为它们是单词匹配。另一个好处是它们不需要使用嵌入和 API token。
嵌入的其他用途
语义相似性分析不仅可以用于检测近似重复项和低相关性内容,还可以用于:
- 改进内部链接 – 较低的“重复详细信息”选项卡和“语义相似性”过滤器可用于改进语义相似内容之间的内部链接。
- URL 重定向映射 – 将旧网站和新网站一起抓取,并调整语义相似性阈值,以获取最接近的语义相似 URL 的重定向列表。
- 任何元素的语义相似性分析 – 选择“页面标题”而不是“页面文本”进行嵌入,并运行语义相似分析以查找近似重复的标题。
还有更多!
嵌入的局限性
不概述嵌入及其在工具中的使用的局限性是不负责任的。在深入阅读时,我们建议:
虽然建议以通常的方式使用 OpenAI 嵌入 和 Gemini 嵌入,但通常需要整理和调整数据集,然后应用各种技术来探索数据集,以确定如何呈现结果。
由于我们软件的性质,我们采用了一种一刀切的方法。
虽然结果在所有情况下可能并不完美或可靠,但从经验来看,结果已被证明在各种网站上都很有用。
永远不要盲目地遵循数据,始终需要人工解释和分析。
调试
如果任何依赖嵌入的功能都无法工作,则可能是通过您选择的 AI 提供商生成它们时出现问题。
第一步是检查是否已在“AI”选项卡下创建了嵌入。嵌入列中应该有一个长数字。“Prompt Request Status”也应该显示“成功”。
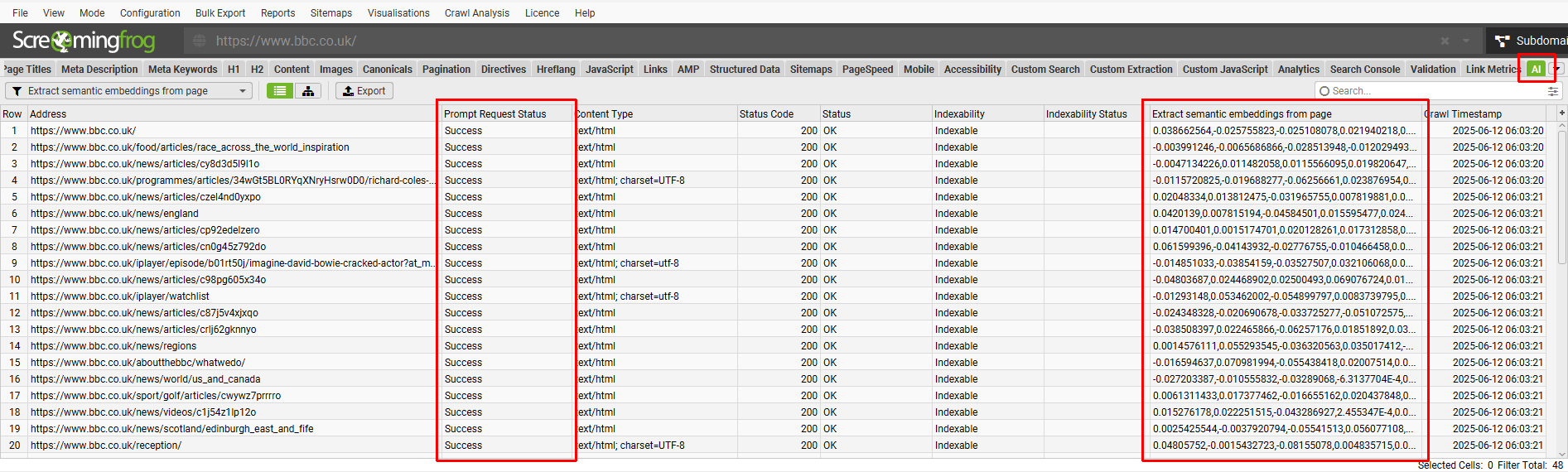
如果嵌入列为空白,则表示尚未创建任何嵌入——并且依赖它的功能将无法工作。
可以通过点击“配置 > API 访问 > AI > AI 提供商”,然后在“Prompt Configuration”上点击“测试”按钮来调试此问题。
输入缺少嵌入的页面的 URL,并读取来自 AI 提供商的响应。
这将确认具体错误。上面是大型页面超过 token 大小限制的示例错误,但通常所有页面的错误都与帐户信用等有关。
成功的请求应如下所示 –
总结
上面的指南应该说明如何使用 SEO Spider 在抓取中查找重复和语义相似的页面。
为了获得最佳结果,请优化用于嵌入的内容区域,并调整不同站点或页面组的阈值。
另请阅读我们的 Screaming Frog SEO Spider 常见问题解答 和完整的用户指南,以获取有关该工具的更多信息。如有任何疑问,请与我们的支持联系。