如何调试 Head 中的无效 HTML 元素
识别 <head> 中的无效 HTML 元素,查看受影响的元数据,并调试导致问题的实际原因。
<Head> 中无效 HTML 元素简介
本教程解释了如何使用 Screaming Frog SEO Spider 识别 <head> 中的无效 HTML 元素,查看哪些元数据可能受到不利影响,以及如何调试导致问题的实际原因。
首先,让我们快速总结一下 <head> 中无效 HTML 元素的含义。
什么是 <Head> 中的无效 HTML 元素?
为页面的元数据使用有效的 HTML 可确保搜索引擎(例如 Google)能够按预期使用它。
虽然搜索引擎会尝试理解标记,即使存在错误,但在 <head> 中执行的一些修复可能会导致使用问题。
如果在 <head> 中使用了无效的 HTML 元素,Google 将假定应该关闭 head,并启动 <body> – 类似于 Chrome 等浏览器。
这意味着出现在无效 HTML 元素之后的任何元数据都可能被 Google 忽略。
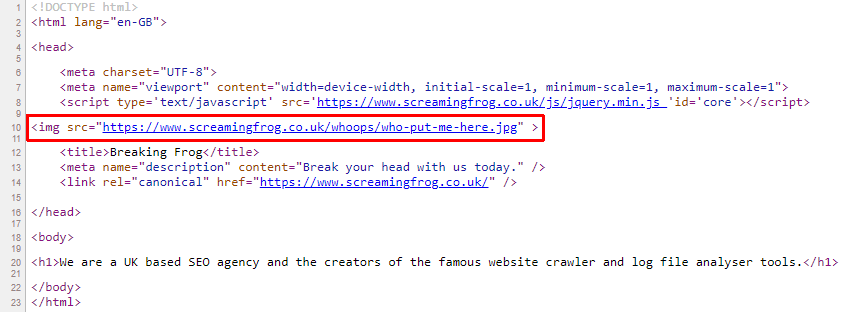
根据 HTML 标准,<head> 元素必须仅包含以下元素:
- title
- meta
- link
- script
- style
- base
- noscript
- template
一些最常出现在 <head> 中,会导致问题的元素包括:
- iframe
- img
- svg
- div
- 包含 img 的 noscript(稍后会详细介绍!)
基本规则是,任何位于 <head> 元素之前的 <body> 元素都会使其失效。
虽然最好避免在 <head> 中使用非 head 元素,但如果它出现在预期的元数据之后,则不会对搜索引擎造成问题。 <head> 只会在元数据之后关闭。
不仅仅是“在 <Head> 中”,而是“在之前”
<head> 中的无效 HTML 元素已由 Google 记录,并且被许多 SEO 人员所熟知和背诵。
但是,不仅仅是“在 <head> 中”可能存在问题,而且 <body> 元素本身位于 <head> 元素之前也可能影响 <head> 中的所有元数据。
例如,位于开头 <html> 元素之前的多余 <div> 标签将意味着 Google 会自动打开和关闭一个空的 <head> 元素,这意味着所有元数据都将位于 <body> 中,并且可能被忽略。
如何识别破坏 <Head> 的无效 HTML 元素
大规模地在整个网站上查找 <head> 中或之前的无效 HTML 元素非常困难,而这正是 SEO Spider 可以帮助完成繁重工作的地方。
它会标记任何包含可能有问题的无效 <html> 元素的页面,以及任何位于 <head> 之外的元数据,例如标题、canonical 或 meta robots。
要识别 <head> 中或之前的无效 HTML 元素,只需按照以下步骤操作。
1) 抓取网站
将网站地址输入到 URL 栏中,然后点击“开始”。

SEO Spider 会实时分析,因此您可以开始分析数据,或者等到抓取达到 100%。
2) 查看“验证”选项卡
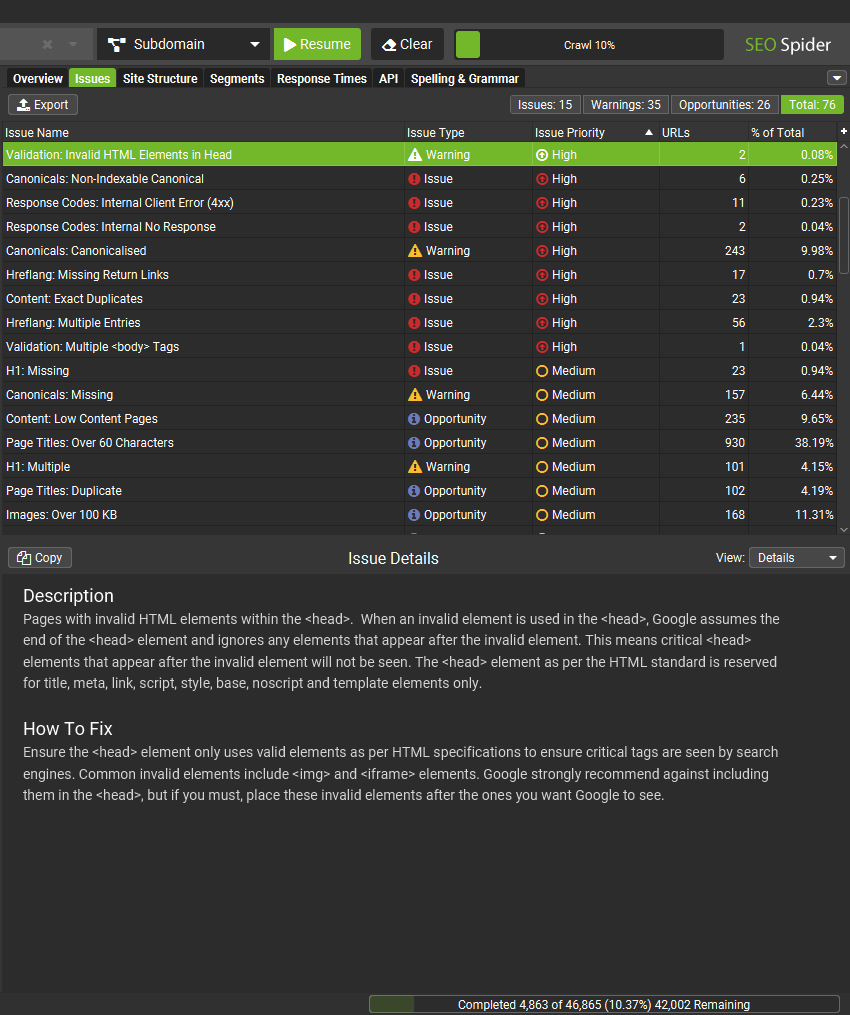
点击 “验证”选项卡,该选项卡具有许多过滤器,可帮助识别潜在问题。
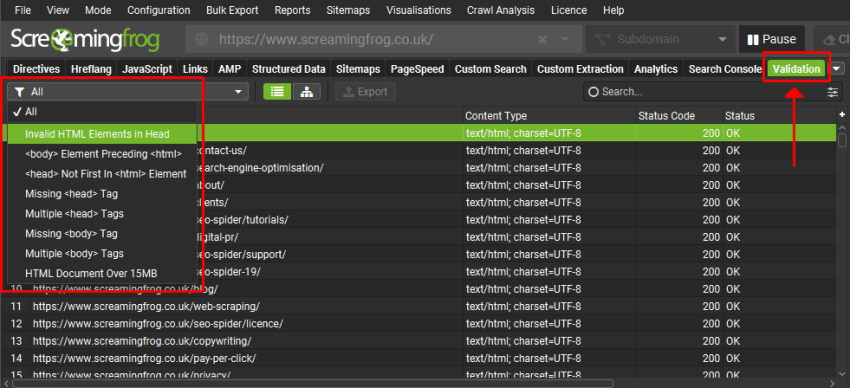
使用右侧的“概述”选项卡查看过滤器中每个问题 URL 的数量。
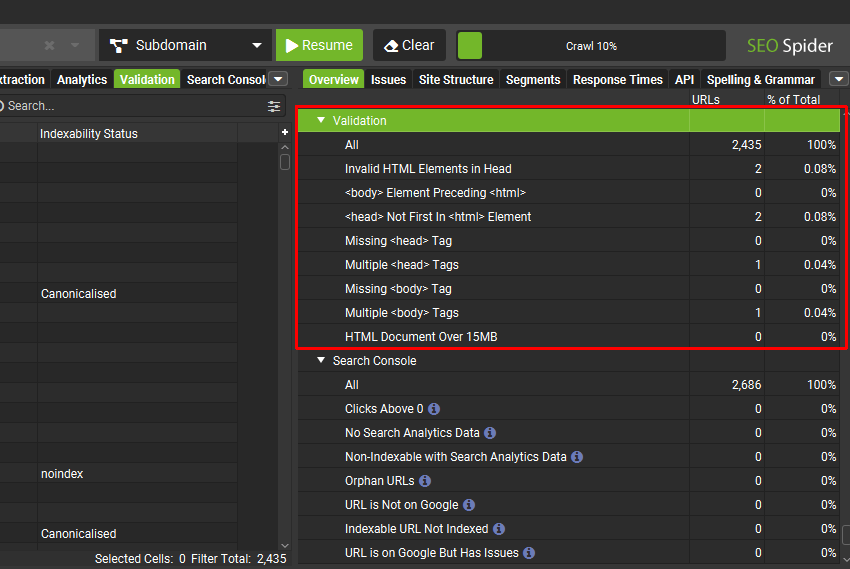
此选项卡包括以下与无效 HTML 可能导致的潜在问题相关的过滤器。
<head>中的无效 HTML 元素 –<head>中包含无效 HTML 元素的页面。 当在<head>中使用无效元素时,Google 会假定<head>元素的结尾,并忽略出现在无效元素之后的任何元素。 这意味着出现在无效元素之后的关键<head>元素将不会被看到。 根据 HTML 标准,<head>元素仅保留用于 title、meta、link、script、style、base、noscript 和 template 元素。<body>元素位于<html>之前 – 页面具有位于开头 html 元素之前的 body 元素。 浏览器和 Googlebot 会自动假定 body 的开始,并在其之前生成一个空的 head 元素。 这意味着下面的预期 head 元素及其元数据将在 body 中被看到并被忽略。<head>不是<html>元素中的第一个 – 页面具有 HTML 元素,该元素在 HTML 中位于<head>元素之前。<head>应该是<html>元素中的第一个元素。 如果<head>不是 HTML 中的第一个元素,浏览器和 Googlebot 将自动生成一个<head>元素。 虽然理想情况下<head>元素应该位于<head>中,但如果有效的<head>元素是<html>中的第一个元素,它将被视为生成的<head>的一部分。 但是,如果在预期的<head>元素及其元数据之前使用了非<head>元素(例如<p>、<body>、<img>等),则 Google 会假定<head>元素的结尾。 这意味着预期的<head>元素及其元数据可能仅在<body>中被看到并被忽略。- 缺少
<head>标签 – HTML 中缺少<head>元素的页面。<head>元素是页面元数据的容器,位于<html>和<body>标签之间。 元数据用于定义页面标题、字符集、样式、脚本、视口和其他对页面至关重要的数据。 如果标记中省略了<head>元素,浏览器和 Googlebot 将自动生成一个<head>元素,但是它可能不包含页面的有意义的元数据,因此不应依赖它。 - 多个
<head>标签 – HTML 中具有多个<head>元素的页面。 HTML 中应该只有一个<head>元素,其中包含文档的所有关键元数据。 如果随后的<head>元素都在<body>之前,浏览器和 Googlebot 将合并来自这些元素的元数据,但是,不应依赖此行为,并且可能会出现混淆。<body>开始后的任��何<head>标签都将被忽略。
请记住,如果非 head 元素出现在预期的元数据之后,则对 Google 来说不是问题。 但是,您如何知道它是否会影响任何关键的 SEO 和元数据元素?
3) 查看元数据选项卡
如果上述任何“验证”过滤器被标记,则预期的元数据可能位于 <head> 之外。
为了更好地理解和识别此问题,在以下选项卡中,关键元素具有“在 <head> 之外”的过滤器 – 页面标题、元描述、Canonical、指令和 Hreflang。
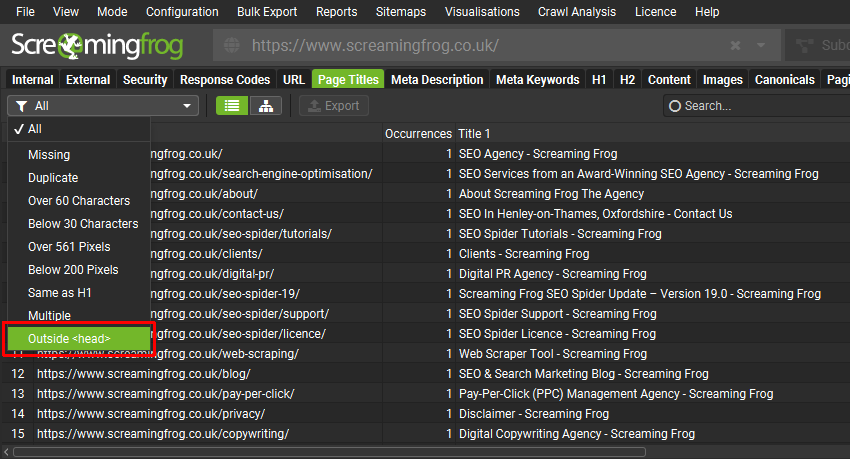
可以在每个选项卡和过滤器下查看数据,或者如果您使用右侧的 “问题”选项卡,则所有验证问题都将标记为关键元素“高优先级”。
虽然 SEO Spider 会在适当的情况下标记任何“在 <head> 之外”的元素,但测试表明 Google 会考虑 <body> 中的标题和指令,例如“noindex”。 但是,不应依赖此行为,并且 Google 对此行为并不一致,并且会忽略 canonical 和 hreflang。
如果您有一个损坏的 <head>,那么对于你们这些好奇的 SEO ��人员来说,下一步就是调试它。
如何调试破坏 <Head> 的无效 HTML 元素
如果您发现 URL 在“Head 中的无效 HTML 元素”过滤器或其他相关问题下被标记,则可以分析 HTML 进行调试。
原始 HTML
在 Chrome 中右键单击并“查看页面源代码”将显示 JavaScript 之前的原始 HTML,您可以在其中查看 <head> 元素的内容。
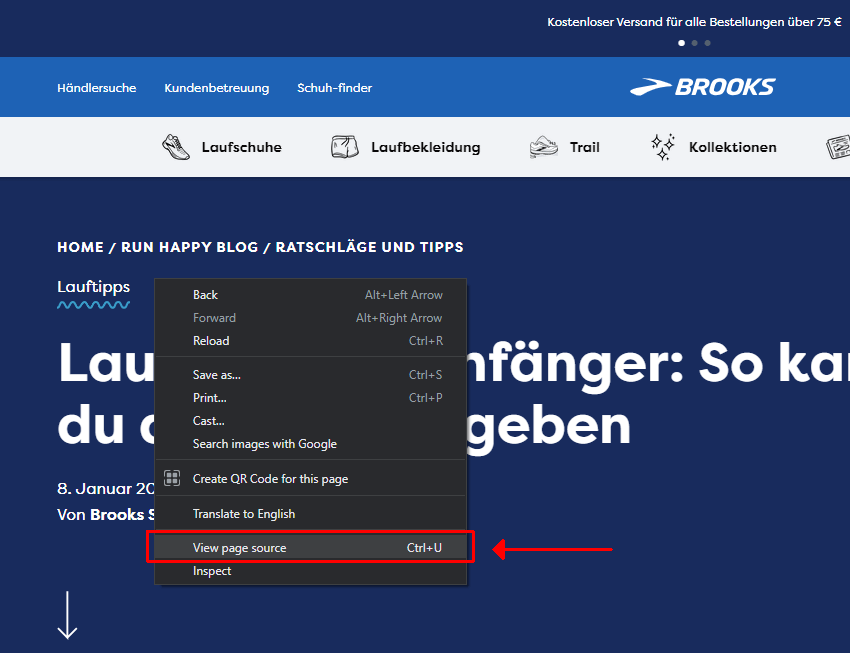
扫描原始 HTML 以查找开头和结尾 <head> 元素之间的无效 HTML 元素可能很棘手,尤其是在 <head> 元素很大的情况下。 此示例在 <head> 中有 600 多行。
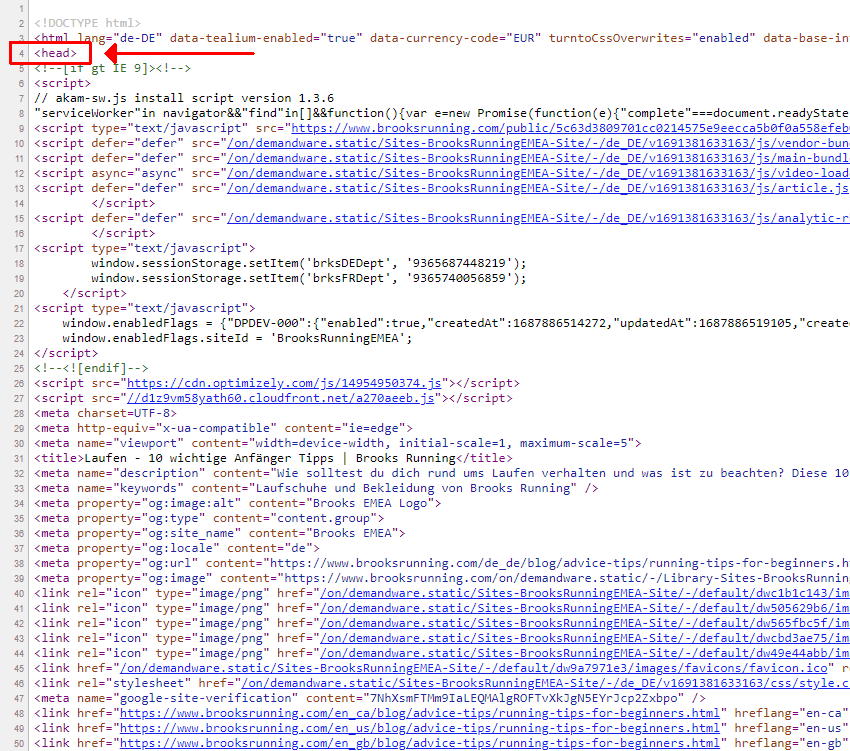
但是,这是可能的,在这种情况下,第 70 行上有一个 SVG 元素,它不应该在那里 – 基于我们 之前概述 的有效 HTML 元素。
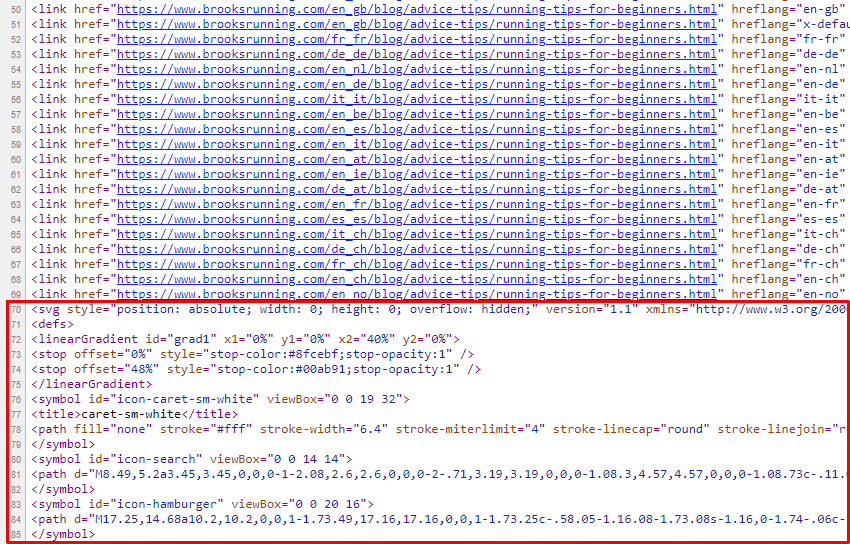
仅查看原始 HTML 的问题之一是,它可能会错过由 JavaScript 动态插入的元素。
渲染的 HTML
识别 <head> 中无效 HTML 元素的一种更有效和可靠的方法是使用 Chrome 中右键单击“检查元素”,它会显示 JavaScript 处理后的渲染 HTML。
这很有用,原因有两个 – <body> 中的第一个元素通常是无效的 HTML 元素。 它还会考虑讨厌的 JavaScript,如果您只是分析了原始 HTML,它可能会在不知不觉中将无效的 HTML 元素动态插入到 <head> 中。
Chrome(如 Googlebot)会假定 <head> 应该关闭,并且当遇到 <body> 元素时,<body> 应该打开。 因此,您可以立即看到它是 SVG,而无需费心在原始 HTML 中搜索不应该存在的元素。
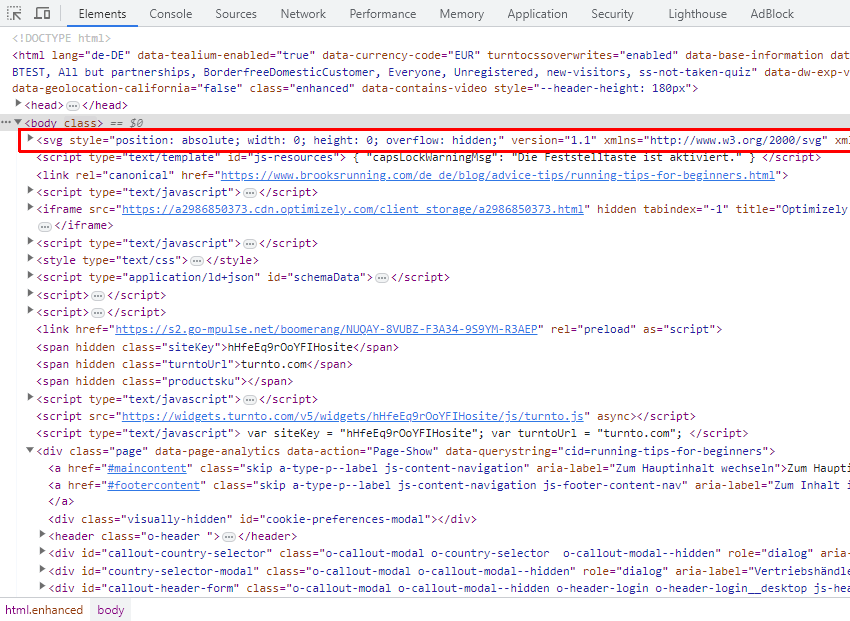
您还可以看到,在这种情况下,出现在原始 HTML 中 SVG 之后(但在 <head> 元素内)的 canonical link 元素实际上被认为是“在 <head> 之外”,并且在渲染的 HTML 中位于 <body> 中。
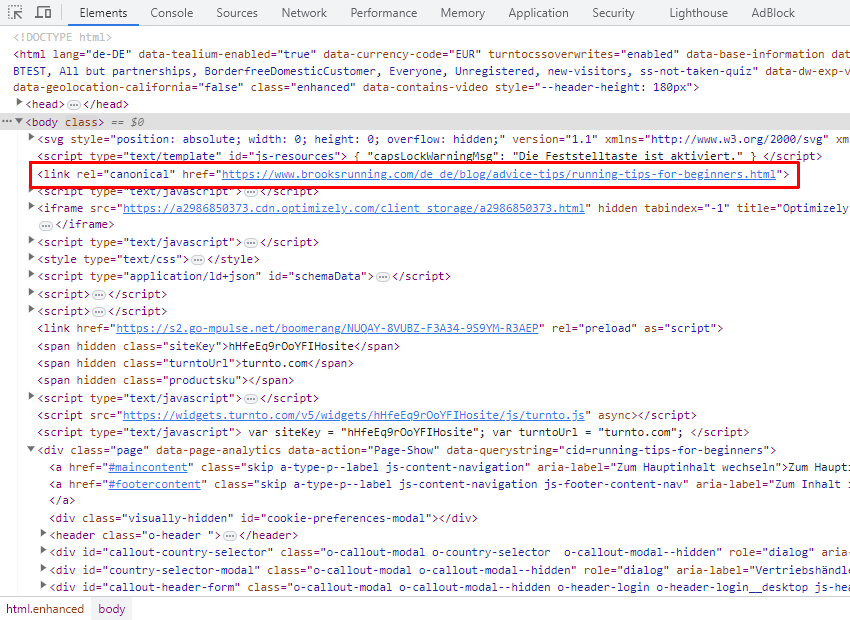
Googlebot
根据我们的测试,Googlebot 通常以与 Chrome 相同的方式进行解析,但 iframe 除外,它们喜欢内联 iframe。
但是,您可以使用 Search Console 中的 URL 检查工具或移动设备适合性测试工具(即将被淘汰)并查看渲染的 HTML 来验证 Google 自己的行为。
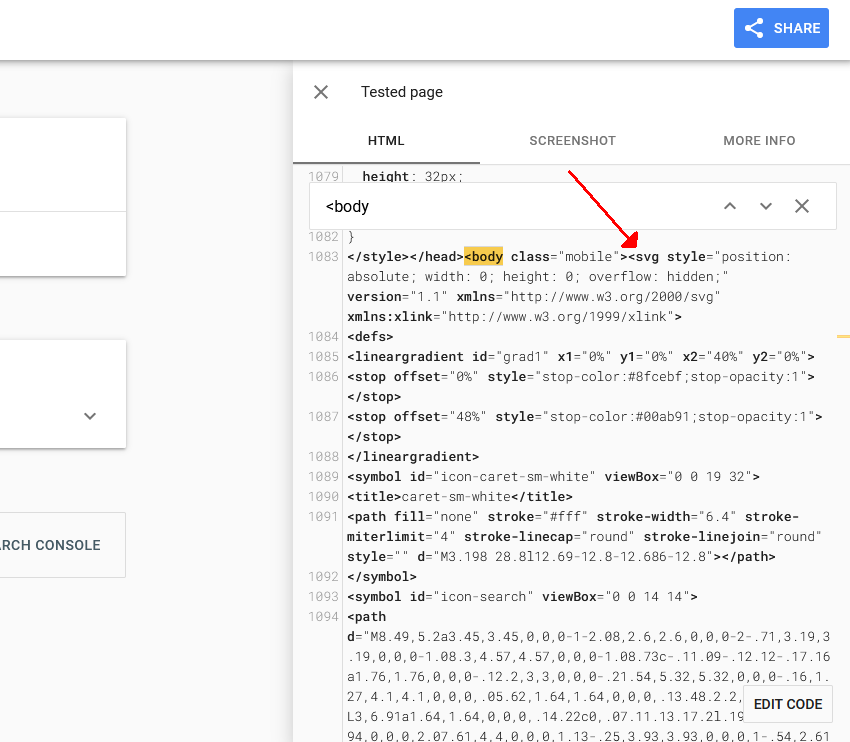
正如您在此处看到的,由于 SVG,<body> 以与 Chrome 相同的方式打开。 渲染的 HTML 中更靠下的位置是 <head> 之外的 canonical。
<noscript> 注意事项
虽然通常我们认为 Google 今天会渲染所有内容,但有一些 <noscript> 边缘情况,需要您在使用检查元素进行测试时禁用 JavaScript。
如果 <noscript> 标签包含无效的 HTML 元素,则可以关闭 <head>。 使用 URL 检查工具查看渲染的 HTML 也不会显示损坏的 <head> 元素。
查看问题的一种方法是使用 Google 的 URL 检查“页面索引”,它会在索引后显示“用户声明的 Canonical”。
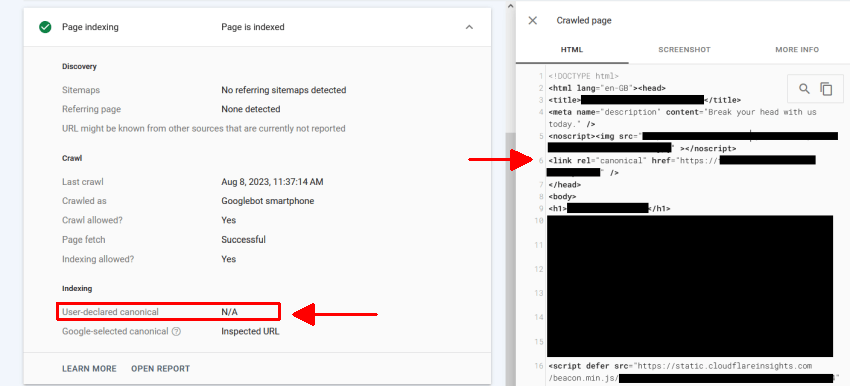
右侧的渲染 HTML 看起来不错��,但我们可以看到“用户声明的 Canonical”为“N/A”,因为它被忽略了,因为包含在其上方的图像的 <noscript> 标签默默地关闭了 <head>。
总结
本教程有望帮助您找到 <head> 中的无效 HTML 元素,发现哪些元数据可能受到不利影响,并调试导致问题的具体原因。
然后可以将违规的 HTML 与老板、客户或开发人员分享,以获得额外的赞誉和温暖的模糊感觉。
如果您中途睡着了,所有这些都没有意义,或者您只是在努力调试问题,那么或者,请通过 支持 与我们联系,我们可以提供帮助。