如何在团队中使用 SEO Spider
协作通常是优化工作的重要组成部分,尤其是在 SEO 方面。本教程概述了在使用 Screaming Frog SEO Spider 时,如何在团队中进行最佳协作。
简介
协作通常是优化工作的重要组成部分,尤其是在 SEO 方面。由于工作的性质,您经常需要与业务的多个不同领域(例如开发人员、设计师和文案人员)进行互动,以分享见解并推动建议的实施。
虽然 SEO Spider Tool 是一个本地网站爬虫,但您不必把自己孤立起来。有几种协作方式,可以确保每个人都在同一页面上,无论是共享爬取结果、自动导出到云端,还是实施高级调度流程。
以下是使用 Screaming Frog SEO Spider 进行协作的几种方式。
导出数据
最广泛使用的功能之一是将数据导出到电子表格中。如果您想与没有 SEO Spider 的人共享数据,或者不想发送完整的爬取文件,这将非常有用。
只需单击左上角的“导出”按钮,即可从顶部窗口选项卡和过滤器中导出数据。
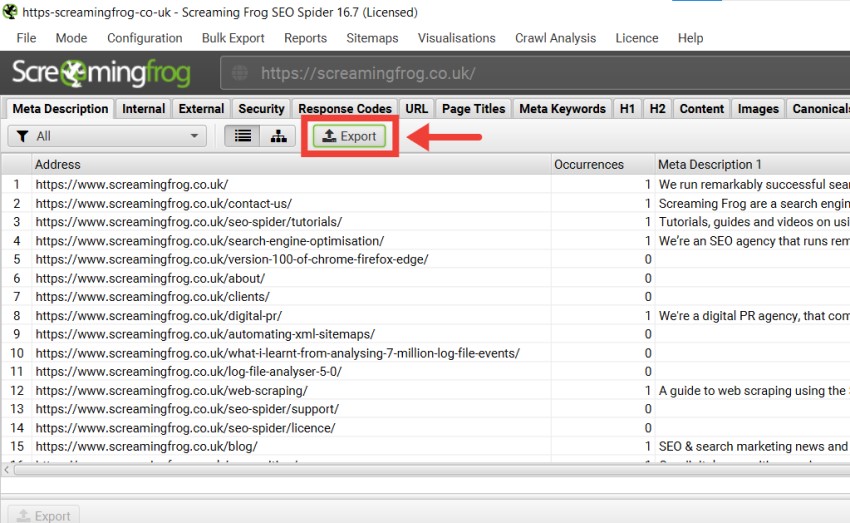
要导出下部窗口数据,请在顶部窗口中右键单击要导出数据的 URL,然后单击其中一个选项。
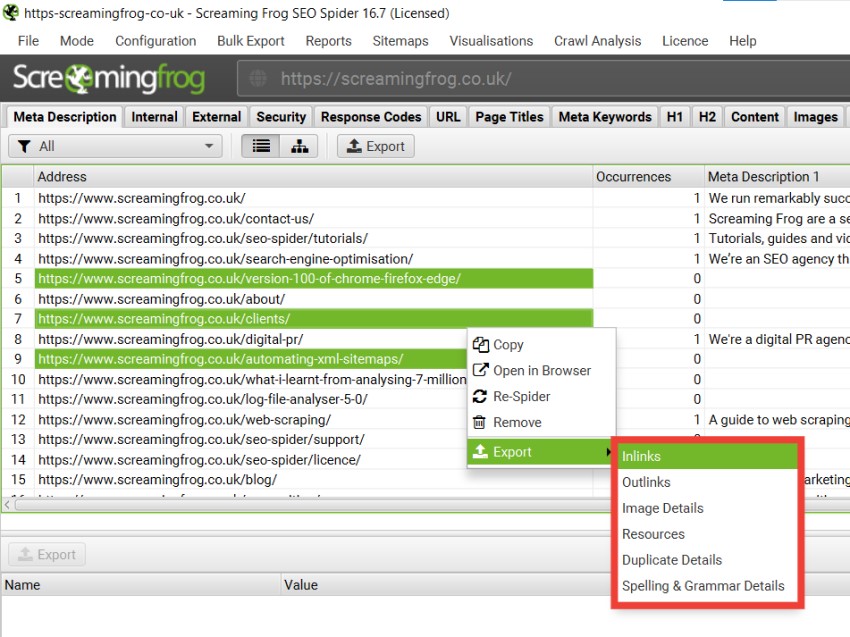
顶级菜单下还有一个“批量导出”选项,允许您导出响应代码、规范问题、指令、结构化数据等内容。
导出爬取结果
导出爬取数据是与也使用 SEO Spider 的人分享您的发现的最简单方法之一。当您导出爬取文件时,它还会记住您的配置和选项卡布局,从而使其他人可以轻松地从您离开的地方继续并深入研究数据。
导出和打开爬取结果需要许可证,并且该方法因您的存储模式而异。
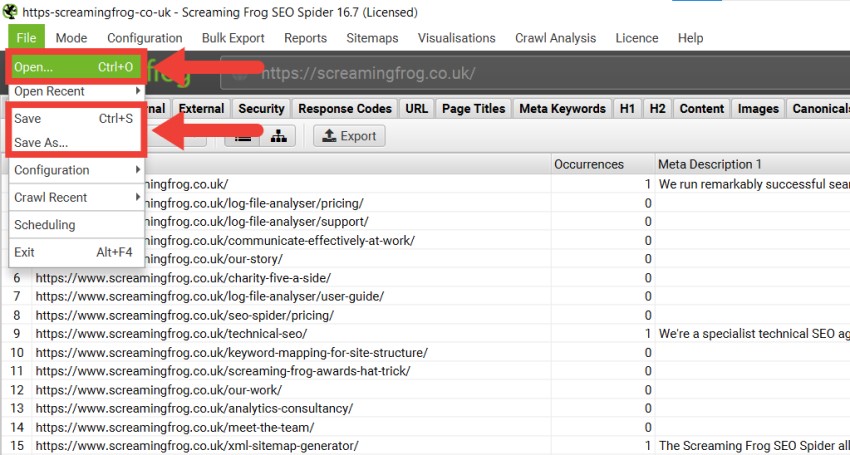
在默认的内存存储模式下,您可以随时(暂停或完成时)保存爬取结果,并通过选择“文件 > 保存/另存为…”或“文件 > 打开”重新打开。
在数据库存储模式下,爬取结果会在爬取过程中自动“保存”并提交到数据库中。要打开爬取结果,请单击主菜单中的“文件 > 爬取结果”。要打开先前使用内存存储模式保存的爬取结果,请单击“文件 > 导入”。要导出爬取结果,请单击“文件 > 导出”。
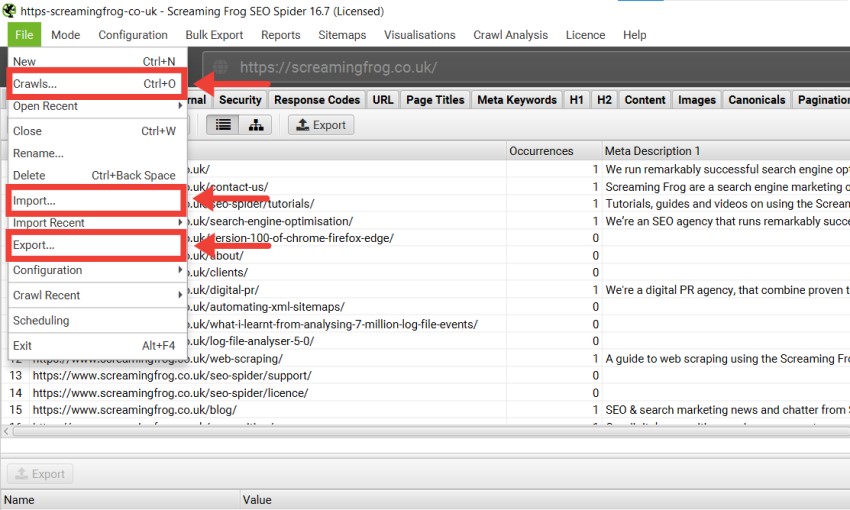
“爬取结果”窗口显示自动存储的爬取结果的概述,您可以在其中批量打开、重命名、组织到项目文件夹中、复制、比较、导出或删除它们。
导出配置文件
除了共享爬取文件外,您还可以共享 SEO Spider 配置文件。能够与他人共享配置对于在同一站点或需要特定配置(例如排除项、包含项、限制等)的一组站点上工作的团队非常有用。
要导出配置文件,请转到“文件 > 配置 > 另存为…”�:
要导入配置,请单击“文件 > 配置 > 加载”。如果一切顺利,您将在 SEO Spider 中看到一条成功消息:
将数据导出到 Google Drive
还可以将 SEO Spider 中的数据直接导出到 Google Drive。为此,只需在“导出”窗口中将“类型”更改为 Google Sheets。
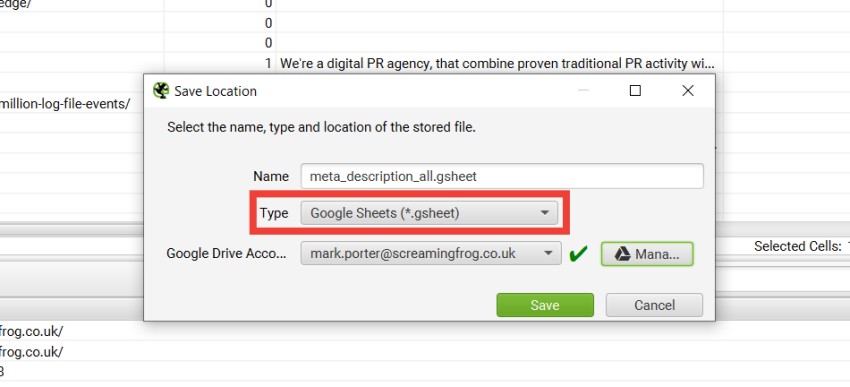
如果您尚未连接 Google 帐户,只需单击“管理”,然后单击“添加”。
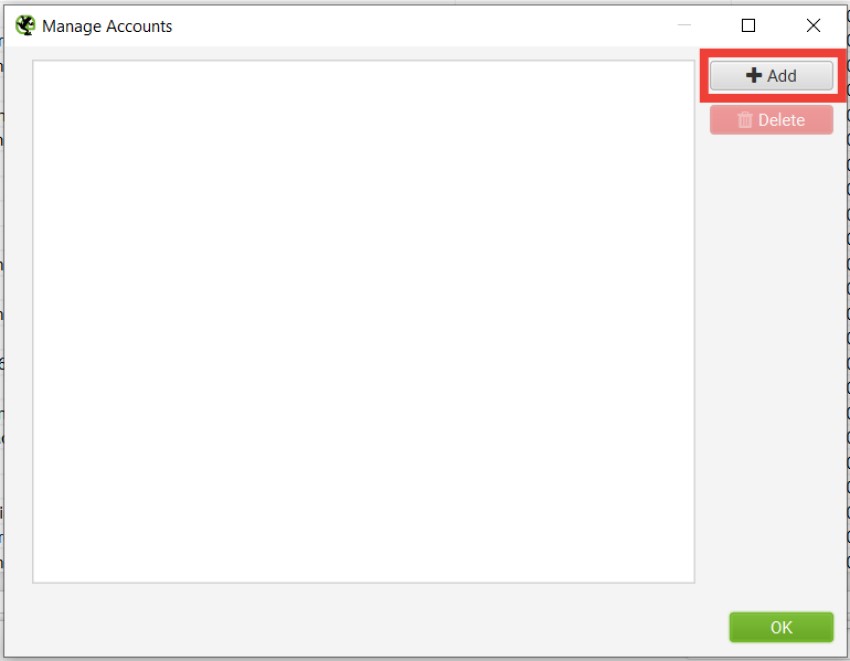
将打开一个新的浏览器窗口,您可以在其中登录到所需的 Google 帐户并授予所需的权限。
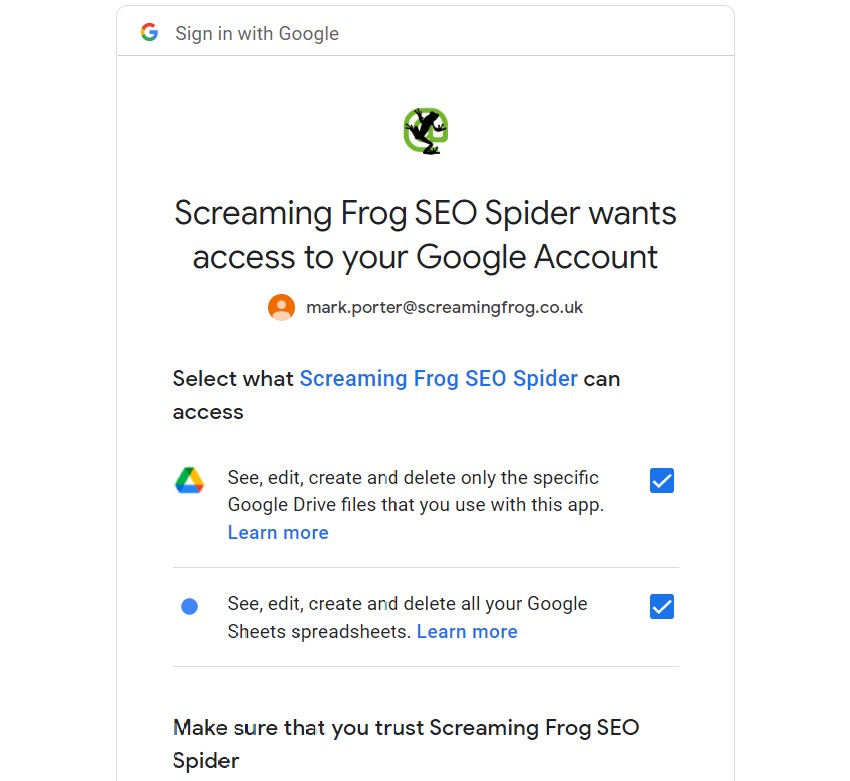
授予访问权限后,您可以关闭浏览器窗口并返回到 SEO Spider。
导出到 Google Sheets 会将导出内容保存在 Google Drive 帐户中的“Screaming Frog SEO Spider”文件夹中。然�后,您可以与其他用户共享此文件夹,并且还可以开启自动化的机会。
调度爬取
您可以在 SEO Spider 中自动运行爬取,作为一次性运行或以选择的间隔运行。此功能可以在应用程序中的“文件 > 调度”下找到。
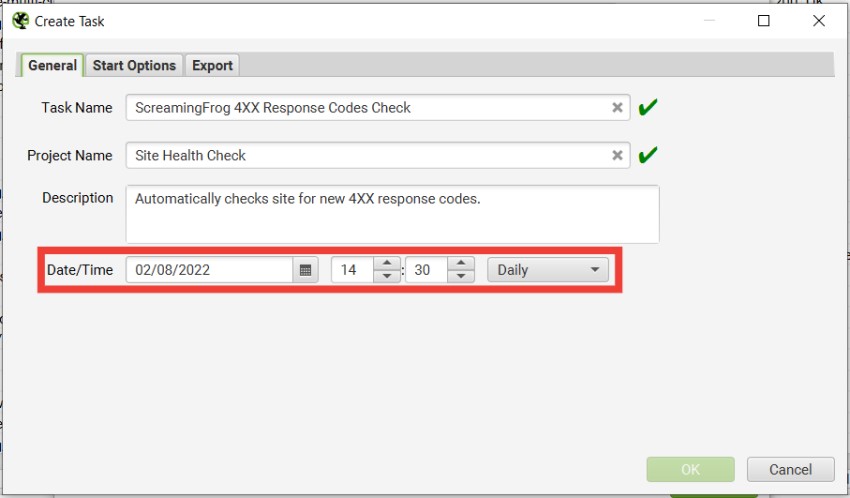
您可以预先选择模式(spider 或 list)、保存的配置以及 API(Google Analytics、Search Console、Majestic、Ahrefs、Moz)来提取计划爬取的任何数据。
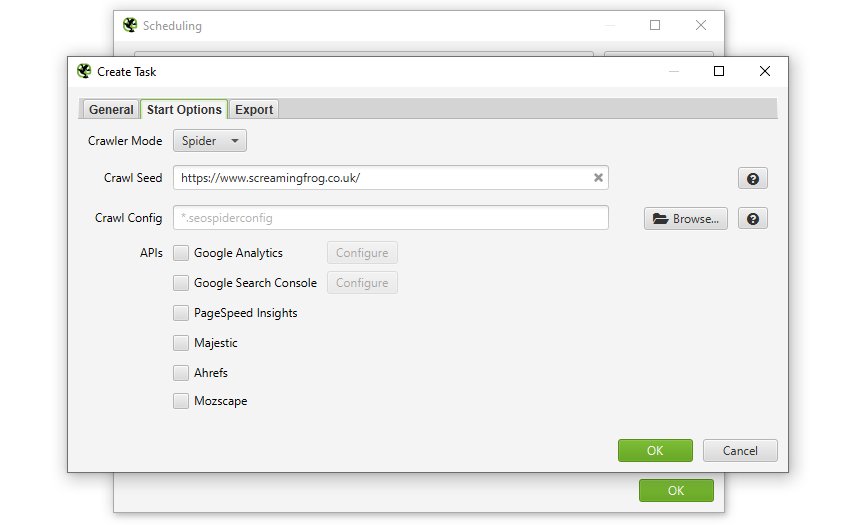
您还可以自动保存爬取文件,并将任何选项卡、批量导出、报告或 XML 站点地图导出到选定的位置,例如网络驱动器。
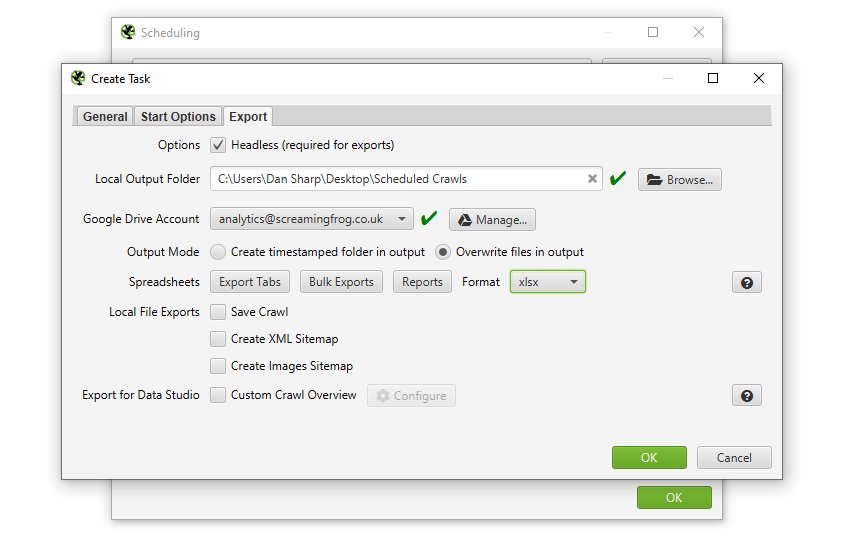
调度还允许您通过将“格式”切换为 gsheet 来自动将任何选项卡、过滤器、导出或报告导出到 Google Sheets。如前所述,这会将 Google Sheet 保存在 Google Drive 帐户中的“Screaming Frog SEO Spider”文件夹中。
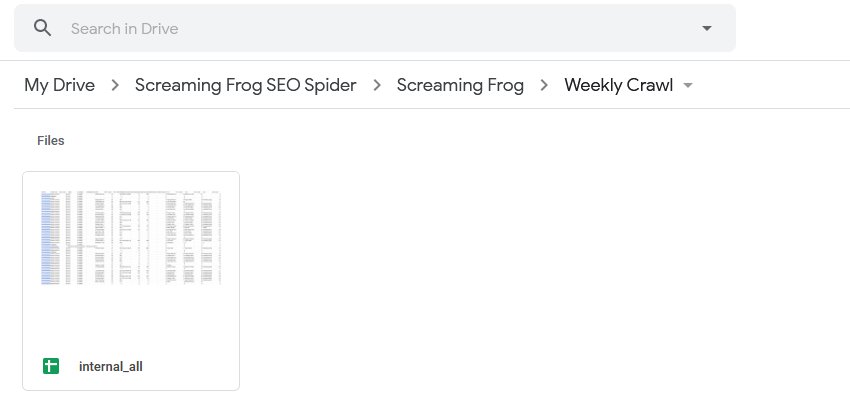
调度中使用的“项目名称”和“爬取名称”将用作导出的文件夹。例如,“Screaming Frog”项目名称和“每周爬取”名称将位于 Google Drive 中,如下所示。
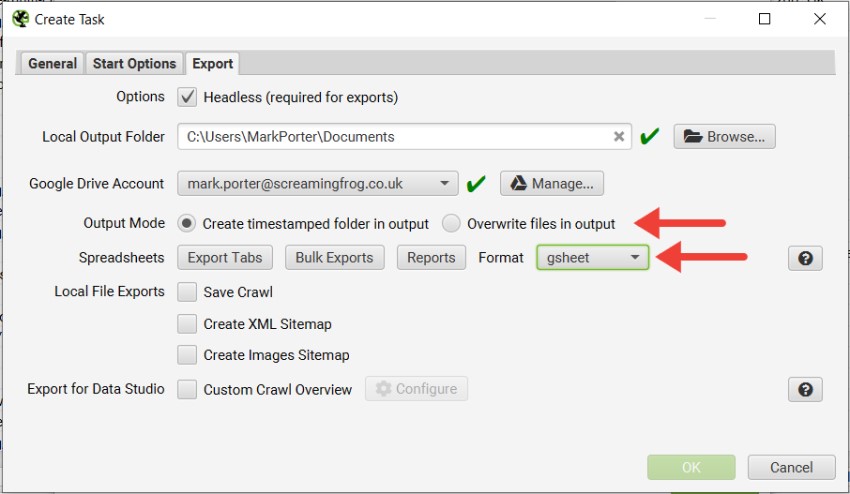
您还可以选择覆��盖现有文件(如果存在)或在 Google Drive 中创建带时间戳的文件夹。
如果您希望导出到 Google Sheets 以连接到 Google Data Studio,请使用“导出到 Data Studio”自定义概览导出。
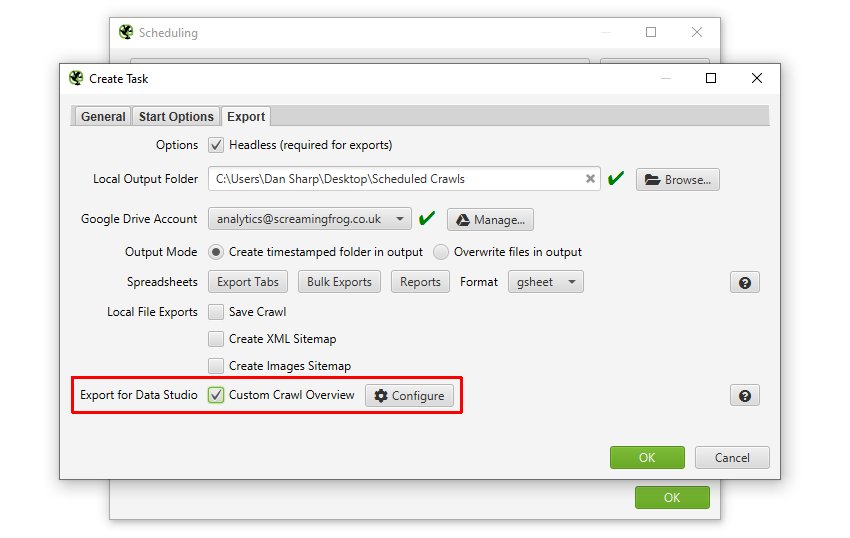
这允许用户选择爬取概览数据作为单个摘要行导出到 Google Sheets。它会自动将新的计划导出附加到同一工作表中时间序列中的新行。请阅读我们的教程“如何在 Data Studio 中自动化爬取报告”来设置此功能。
使用调度时,SEO Spider 将在无头模式下运行(意味着没有界面)以导出数据。这是为了避免任何用户交互或应用程序在您面前启动并单击选项,这会有点奇怪,但这确实意味着机器必须正在运行。但是,也可以将 SEO Spider 用作云爬虫,因此您不必确保设备正在运行(稍后会详细介绍)。
如果您更喜欢使用命令行来操作 SEO Spider,请参阅我们的命令行界面指南。
调度与导出到共享位置(例如 Google Drive、Dropbox 或 OneDrive)相结合,开启了自动化和与 SEO Spider 协作的无限可能。
保存到共享位置
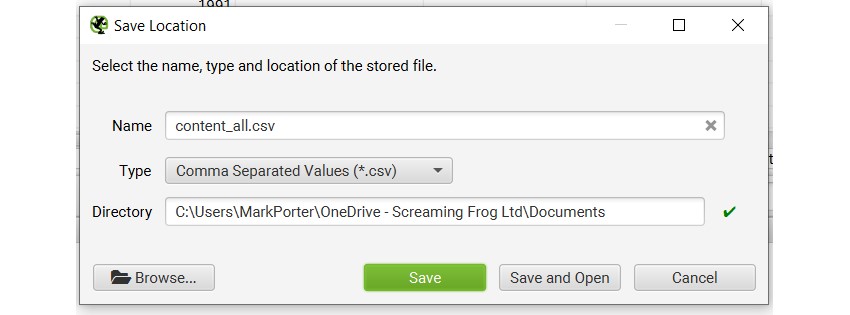
与直接导出到 Google Sheets 类似,您当然可以导出到共享网络驱动器,例如 Dropbox 或 OneDrive。这就像在保存爬取结果、配置文件、导出等内容时选择所需的网络驱动器一样简单。
如果您使用的是数据库存储模式,则不支持使用网络驱动器作为数据库的位置。这是因为它会太慢并且连接不可靠。也不支持 Vault 驱动器。
Google Data Studio
由于调度中的 Data Studio 导出选项,可以创建完全自动化的 Data Studio 报告。这对于定期网站运行状况检查或与利益相关者沟通顶级发现等事情非常有用。
我们有一个关于如何在 Google Data Studio 中设置完全自动化的爬取报告的综合指南,从而为协作方法开启更多选项。
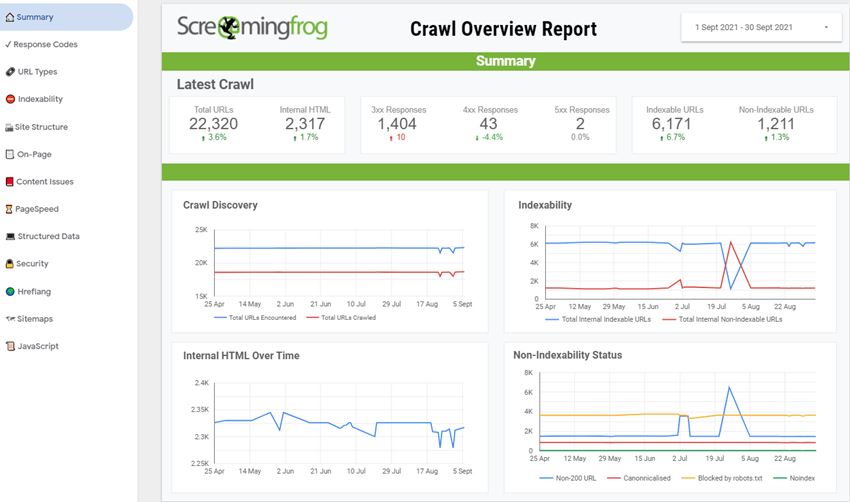
Google Data Studio 最有用的功能之一是电子邮件调度,它允许您每天、每周或每月发送报告。为此,请打开您的 Data Studio 报告,然后单击“共享”旁边的下拉菜单,然后选择“安排电子邮件发送”:
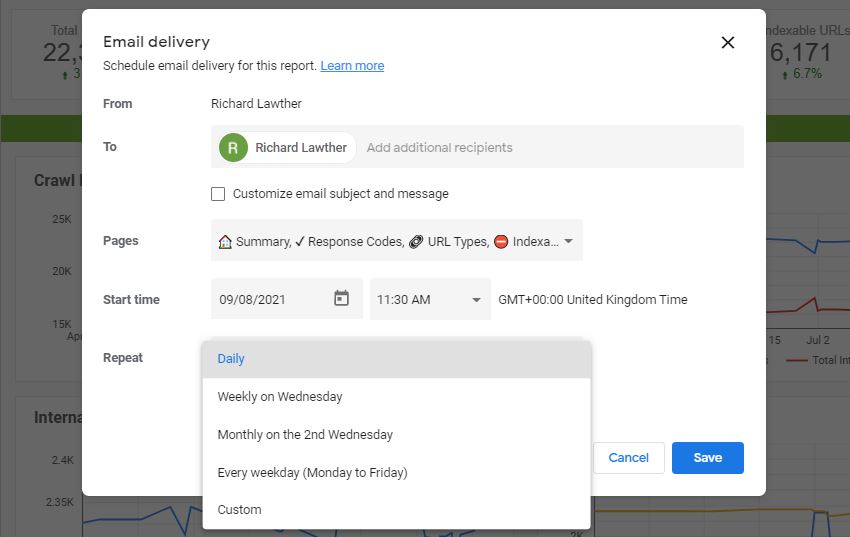
在设置电子邮件时间时,请确保您有足够的时间让爬取完成并且 Google Sheets 同步。例如,如果您的爬取通常需要 1 小时才能完全完成,请将电子邮件发送时间设置为初始爬取计划时间后至少 1 小时。
在云中运行 SEO Spider
如前所述,如果您想在使用 SEO Spider 时自动化工作流程的某些区域,则需要确保您的设备在自动化发生时正在运行。但是,有多种运行 SEO Spider 的方法不需要您始终保持机器开启。
在云中运行 SEO Spider 是实现此目的的一种方法,我们有一个关于如何使用 Google 的 Compute Engine 执行此操作的深入指南。您可以快速启动虚拟机来执行日常任务、运行并发爬取并使用 Compute Engine 的高级调度功能来实现自动化,而无需占用您的本地资源。
除此之外,在云中运行它还允许您或您的同事从任何地方访问正在进行或已完成的爬取,因此您可以轻松获得所需的信息。
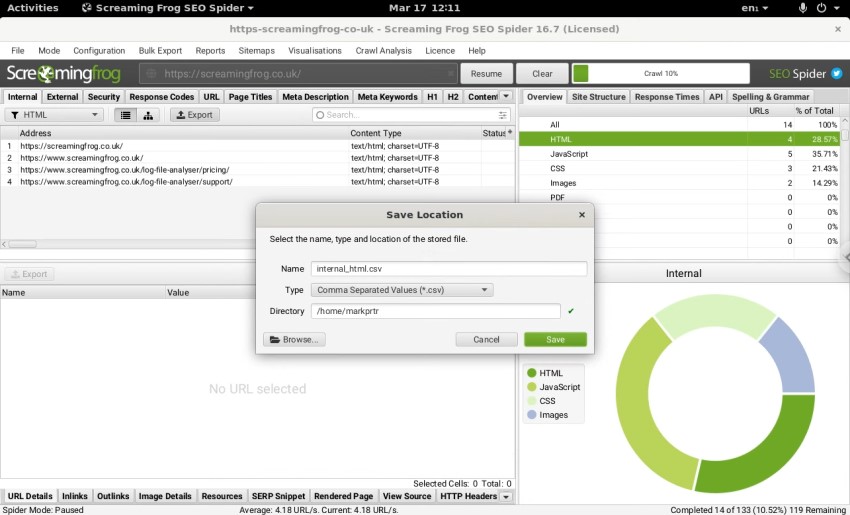
任何上述用于保存和共享数据的方法都适用于在云中运行的 SEO Spider 实例,并且还能够导出到 Google 存储桶。存储桶允许您将数据存储在�云中,从而为自动化开启更多机会,同时保持经济实惠。其他用户也可以添加到存储桶中,使其非常适合共享 SEO Spider 爬取和导出。
虽然有多种在云中运行 SEO Spider 的方法,但我们的指南使用 Chrome 远程桌面来访问虚拟机,主要是为了简单起见。但是,这意味着如果您希望其他人能够访问同一 VM,则需要在多个用户有权访问的 Google 帐户上设置 Chrome 远程桌面。Chrome 远程桌面不支持并发连接,因此如果您需要此功能,则需要探索 Windows Server 远程桌面连接之类的东西。
请注意:许可证是按用户计算的,因此您需要为每个将要访问它的用户提供一个许可证。
总结
希望本教程能够帮助您在使用 Screaming Frog SEO Spider 工具在团队中工作时改进您的工作流程。
如果您在协作时遇到任何问题,或者对此功能有任何其他问题或建议,请通过支持与我们联系,我们可以提供帮助。